PEFT documentation
OFT
OFT
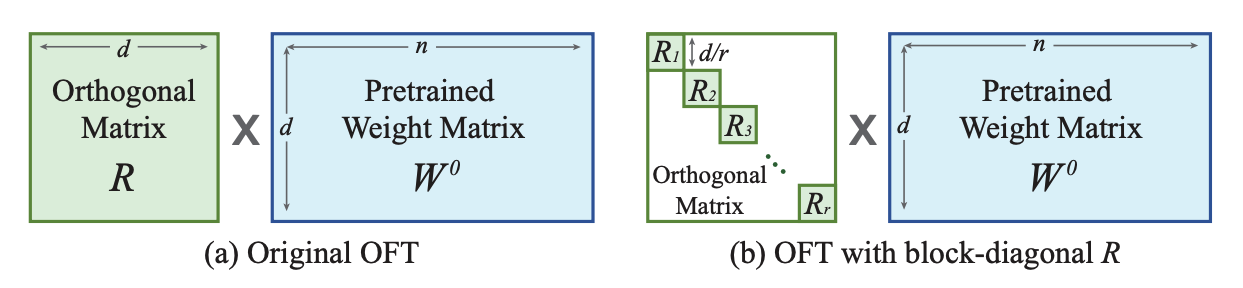
Orthogonal Finetuning (OFT) and OFTv2 is a method developed for adapting text-to-image diffusion models. It works by reparameterizing the pretrained weight matrices with its orthogonal matrix to preserve information in the pretrained model. To reduce the number of parameters, OFT introduces a block-diagonal structure in the orthogonal matrix. The method primarily focuses on preserving a pretrained model’s generative performance in the finetuned model. It tries to maintain the same cosine similarity (hyperspherical energy) between all pairwise neurons in a layer because this better captures the semantic information among neurons. This means OFT is more capable at preserving the subject and it is better for controllable generation (similar to ControlNet).
The abstract from the paper is:
Large text-to-image diffusion models have impressive capabilities in generating photorealistic images from text prompts. How to effectively guide or control these powerful models to perform different downstream tasks becomes an important open problem. To tackle this challenge, we introduce a principled finetuning method — Orthogonal Finetuning (OFT), for adapting text-to-image diffusion models to downstream tasks. Unlike existing methods, OFT can provably preserve hyperspherical energy which characterizes the pairwise neuron relationship on the unit hypersphere. We find that this property is crucial for preserving the semantic generation ability of text-to-image diffusion models. To improve finetuning stability, we further propose Constrained Orthogonal Finetuning (COFT) which imposes an additional radius constraint to the hypersphere. Specifically, we consider two important finetuning text-to-image tasks: subject-driven generation where the goal is to generate subject-specific images given a few images of a subject and a text prompt, and controllable generation where the goal is to enable the model to take in additional control signals. We empirically show that our OFT framework outperforms existing methods in generation quality and convergence speed.
OFT preserves the hyperspherical energy by learning an orthogonal transformation for neurons to keep the cosine similarity between them unchanged, potentially leading to less forgetting of previous learnt knowledge. In practice, this means taking the matrix product of an orthogonal matrix with the pretrained weight matrix. However, to be parameter-efficient, the orthogonal matrix is represented as a block-diagonal matrix with rank r blocks. Whereas LoRA reduces the number of trainable parameters with low-rank structures, OFT reduces the number of trainable parameters with a sparse block-diagonal matrix structure.
Benchmark overview
Merge OFT weights into the base model
Similar to LoRA, the weights learned by OFT can be integrated into the pretrained weight matrices using the [~OFTModel.merge_and_unload() function. This function merges the adapter weights with the base model which allows you to effectively use the newly merged model as a standalone model.
OFT Example Usage
For using OFT for quantized finetuning with TRL for SFT, PPO, or DPO fine-tuning, follow the following outline:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from trl import SFTTrainer
from peft import OFTConfig
if use_quantization:
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_storage=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(
"model_name",
quantization_config=bnb_config
)
tokenizer = AutoTokenizer.from_pretrained("model_name")
# Configure OFT
peft_config = OFTConfig(
oft_block_size=32,
use_cayley_neumann=True,
target_modules="all-linear",
bias="none",
task_type="CAUSAL_LM"
)
trainer = SFTTrainer(
model=model,
train_dataset=ds['train'],
peft_config=peft_config,
processing_class=tokenizer,
args=training_arguments,
data_collator=collator,
)
trainer.train()API
OFTConfig
class peft.OFTConfig
< source >( task_type: Optional[Union[str, TaskType]] = None peft_type: Optional[Union[str, PeftType]] = None auto_mapping: Optional[dict] = None peft_version: Optional[str] = None base_model_name_or_path: Optional[str] = None revision: Optional[str] = None inference_mode: bool = False r: int = 0 oft_block_size: int = 32 module_dropout: float = 0.0 target_modules: Optional[Union[list[str], str]] = None fan_in_fan_out: bool = False bias: Literal['none', 'all', 'oft_only'] = 'none' exclude_modules: Optional[Union[list[str], str]] = None init_weights: bool = True layers_to_transform: Optional[Union[list[int], int]] = None layers_pattern: Optional[Union[list[str], str]] = None modules_to_save: Optional[list[str]] = None coft: bool = False eps: float = 6e-05 block_share: bool = False use_cayley_neumann: bool = True num_cayley_neumann_terms: int = 5 )
Parameters
- r (
int) — OFT rank, number of OFT blocks per injected layer. Biggerrresults in more sparse update matrices with fewer trainable paramters. You can only specify eitherroroft_block_size, but not both simultaneously, becauser×oft_block_size= layer dimension. For simplicity, we let you speficy eitherroroft_block_sizeand infer the other one. Default set tor = 0, the user is advised to set theoft_block_sizeinstead for better clarity. - oft_block_size (
int) — OFT block size across different layers. Biggeroft_block_sizeresults in more dense update matrices with more trainable parameters. Chooseoft_block_sizeto be divisible by layer’s input dimension (in_features), e.g., 4, 8, 16. You can only specify eitherroroft_block_size, but not both simultaneously, becauser×oft_block_size= layer dimension. For simplicity, we let you speficy eitherroroft_block_sizeand infer the other one. Default set tooft_block_size = 32. - use_cayley_neumann (bool) — Specifies whether to use the Cayley-Neumann parameterization (efficient but
approximate) or the vanilla Cayley parameterization (exact but computationally expensive because of matrix
inverse). We recommend to set it to
Truefor better efficiency, but performance may be slightly worse because of the approximation error. Please test both settings (TrueandFalse) depending on your needs. Default isFalse. - module_dropout (
float) — The multiplicative dropout probability, by setting OFT blocks to identity during training, similar to the dropout layer in LoRA. - target_modules (
Optional[Union[list[str], str]]) — The names of the modules to apply the adapter to. If this is specified, only the modules with the specified names will be replaced. When passing a string, a regex match will be performed. When passing a list of strings, either an exact match will be performed or it is checked if the name of the module ends with any of the passed strings. If this is specified as ‘all-linear’, then all linear modules are chosen, excluding the output layer. If this is not specified, modules will be chosen according to the model architecture. If the architecture is not known, an error will be raised — in this case, you should specify the target modules manually. - fan_in_fan_out (
bool) — Set this to True if the layer to replace stores weight like (fan_in, fan_out). - bias (
str) — Bias type for OFT. Can be ‘none’, ‘all’ or ‘oft_only’. If ‘all’ or ‘oft_only’, the corresponding biases will be updated during training. Be aware that this means that, even when disabling the adapters, the model will not produce the same output as the base model would have without adaptation. - exclude_modules (
Optional[Union[List[str], str]]) — The names of the modules to not apply the adapter. When passing a string, a regex match will be performed. When passing a list of strings, either an exact match will be performed or it is checked if the name of the module ends with any of the passed strings. - init_weights (
bool) — Whether to perform initialization of OFT weights. - layers_to_transform (
Union[List[int], int]) — The layer indices to transform. If a list of ints is passed, it will apply the adapter to the layer indices that are specified in this list. If a single integer is passed, it will apply the transformations on the layer at this index. - layers_pattern (
Optional[Union[List[str], str]]) — The layer pattern name, used only iflayers_to_transformis different fromNone. This should target thenn.ModuleListof the model, which is often called'layers'or'h'. - modules_to_save (
List[str]) — List of modules apart from adapter layers to be set as trainable and saved in the final checkpoint. - coft (
bool) — Whether to use the constrained variant of OFT or not, off by default. - eps (
float) — The control strength of COFT. The freedom of rotation. Only has an effect ifcoftis set to True. - block_share (
bool) — Whether to share the OFT parameters between blocks or not. This isFalseby default.
This is the configuration class to store the configuration of a OFTModel.
check_kwargs
< source >( **kwargs )
Check if the kwargs are valid for the configuration.
OFTModel
class peft.OFTModel
< source >( model peft_config: Union[PeftConfig, dict[str, PeftConfig]] adapter_name: str low_cpu_mem_usage: bool = False state_dict: Optional[dict[str, torch.Tensor]] = None ) → torch.nn.Module
Parameters
- model (
torch.nn.Module) — The model to which the adapter tuner layers will be attached. - config (OFTConfig) — The configuration of the OFT model.
- adapter_name (
str) — The name of the adapter, defaults to"default". - low_cpu_mem_usage (
bool,optional, defaults toFalse) — Create empty adapter weights on meta device. Useful to speed up the loading process.
Returns
torch.nn.Module
The OFT model.
Creates Orthogonal Finetuning model from a pretrained model. The method is described in https://huggingface.co/papers/2306.07280
Example:
>>> from diffusers import StableDiffusionPipeline
>>> from peft import OFTModel, OFTConfig
>>> config_te = OFTConfig(
... r=8,
... target_modules=["k_proj", "q_proj", "v_proj", "out_proj", "fc1", "fc2"],
... module_dropout=0.0,
... init_weights=True,
... )
>>> config_unet = OFTConfig(
... r=8,
... target_modules=[
... "proj_in",
... "proj_out",
... "to_k",
... "to_q",
... "to_v",
... "to_out.0",
... "ff.net.0.proj",
... "ff.net.2",
... ],
... module_dropout=0.0,
... init_weights=True,
... )
>>> model = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
>>> model.text_encoder = OFTModel(model.text_encoder, config_te, "default")
>>> model.unet = OFTModel(model.unet, config_unet, "default")Attributes:
- model (
~torch.nn.Module) — The model to be adapted. - peft_config (OFTConfig): The configuration of the OFT model.