
HY-Embodied
Collection
2 items • Updated • 6
An Enhanced Embodied Foundation Model for Real-World Agents
Tencent Robotics X × HY Vision Team
![]()
HY-Embodied-0.5-X is an enhanced open-source embodied foundation model
jointly released by Tencent Robotics X and the HY Vision Team. Built on
top of the HY-Embodied-0.5 MoT-2B architecture (4B total parameters with
only 2B activated), it is specifically optimized for the core loop of
real-world robotics — "understand, reason, and act".
The model reaches state-of-the-art performance on 10 mainstream embodied task-planning benchmarks, ranking 1st among edge-side domain models on 7 of them. Compared with HY-Embodied-0.5-X focuses more tightly on the problems that matter in real-world robot interaction, with dedicated improvements in fine-grained manipulation understanding, spatial reasoning, action prediction, risk assessment, multimodal reference grounding, and long-horizon planning — pushing the model from "seeing" to "doing".
[2026-04-24] 🚀 Released HY-Embodied-0.5-X, an embodied-focused
enhancement on top of HY-Embodied-0.5 MoT-2B, together with inference
and training code.| Item | Requirement |
|---|---|
| OS | Linux |
| Python | 3.12 |
| CUDA | 12.6 |
| PyTorch | 2.10.0 |
| GPU | NVIDIA GPU with ≥ 16 GB VRAM |
Install the specific transformers commit that natively registers
HY-Embodied, then the usual PyTorch / vision deps:
pip install git+https://github.com/huggingface/transformers@9293856c419762ebf98fbe2bd9440f9ce7069f1a
pip install torch==2.10.0 torchvision==0.25.0 --index-url https://download.pytorch.org/whl/cu126
pip install accelerate safetensors Pillow
Minimal single-image inference using plain transformers. The model is
auto-downloaded from the Hub on first use.
import torch
from transformers import AutoModelForImageTextToText, AutoProcessor
MODEL_PATH = "tencent/HY-Embodied-0.5-X"
DEVICE = "cuda"
THINKING_MODE = True
TEMPERATURE = 0.05
processor = AutoProcessor.from_pretrained(MODEL_PATH)
model = AutoModelForImageTextToText.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
).to(DEVICE).eval()
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "./demo.jpg"},
{"type": "text", "text": "Describe the image in detail."},
],
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
enable_thinking=THINKING_MODE,
).to(model.device)
with torch.no_grad():
generated_ids = model.generate(
**inputs,
max_new_tokens=32768,
use_cache=True,
temperature=TEMPERATURE,
do_sample=TEMPERATURE > 0,
)
output_ids = [out[len(inp):] for inp, out in zip(inputs.input_ids, generated_ids)]
print(processor.batch_decode(output_ids, skip_special_tokens=True)[0])
(x, y) or [(x1, y1), (x2, y2)][xmin, ymin, xmax, ymax]<think>[reasoning]</think><answer>[answer]</answer>.For SFT fine-tuning (single-node / multi-node, DeepSpeed ZeRO-2, FSDP),
batch inference, multi-image / video inputs, the packaged
HyEmbodiedPipeline API, CLI entry points, data format spec, and the full
training data mixture used in the release, please see the official GitHub
repository:
👉 https://github.com/Tencent-Hunyuan/HY-Embodied-0.5-X
Minimal fine-tuning snippet (after cloning the repo and setting up the env):
# Smoke-test on bundled samples
CUDA_VISIBLE_DEVICES=0 python -m hy_embodied.cli.train \
--config configs/sft/example_small_single_gpu.yaml
# 1 node × 8 GPUs with DeepSpeed ZeRO-2
bash scripts/run_sft_1node_8gpu.sh
See docs/training.md,
docs/inference.md,
and docs/data_format.md
for the full reference.
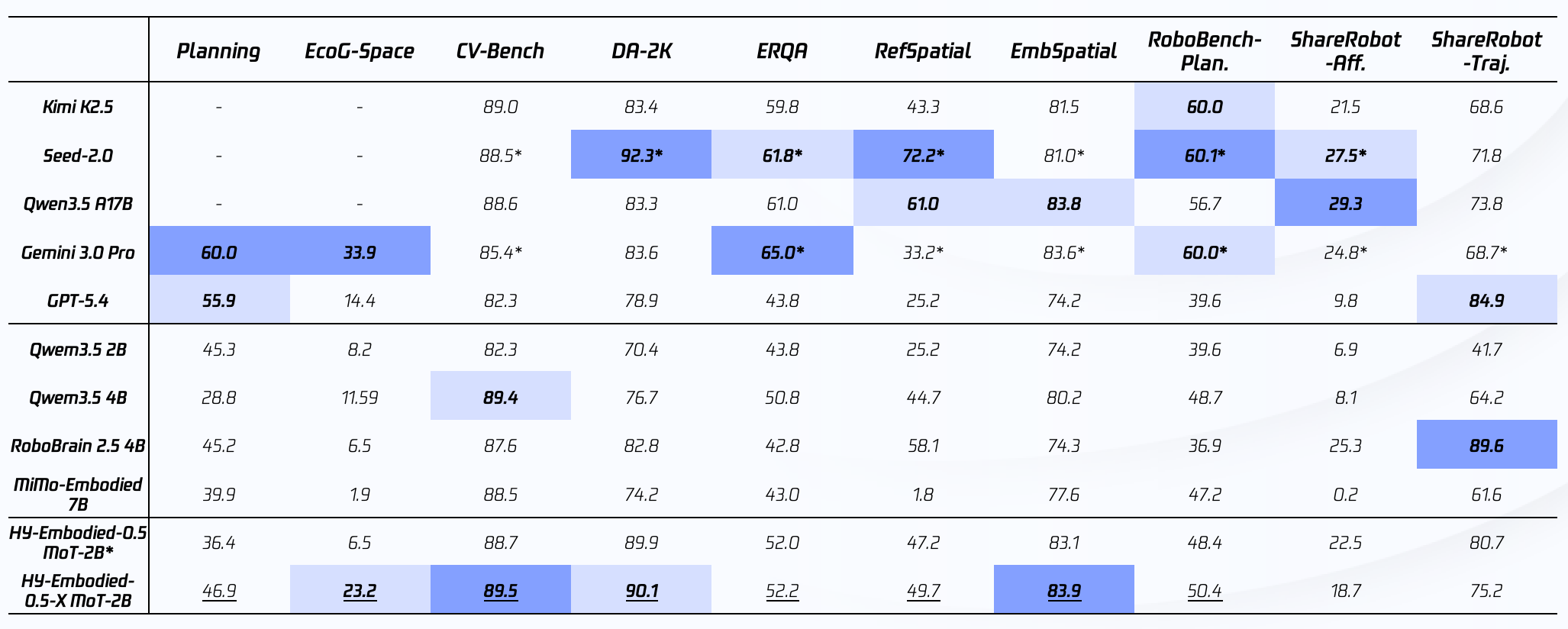
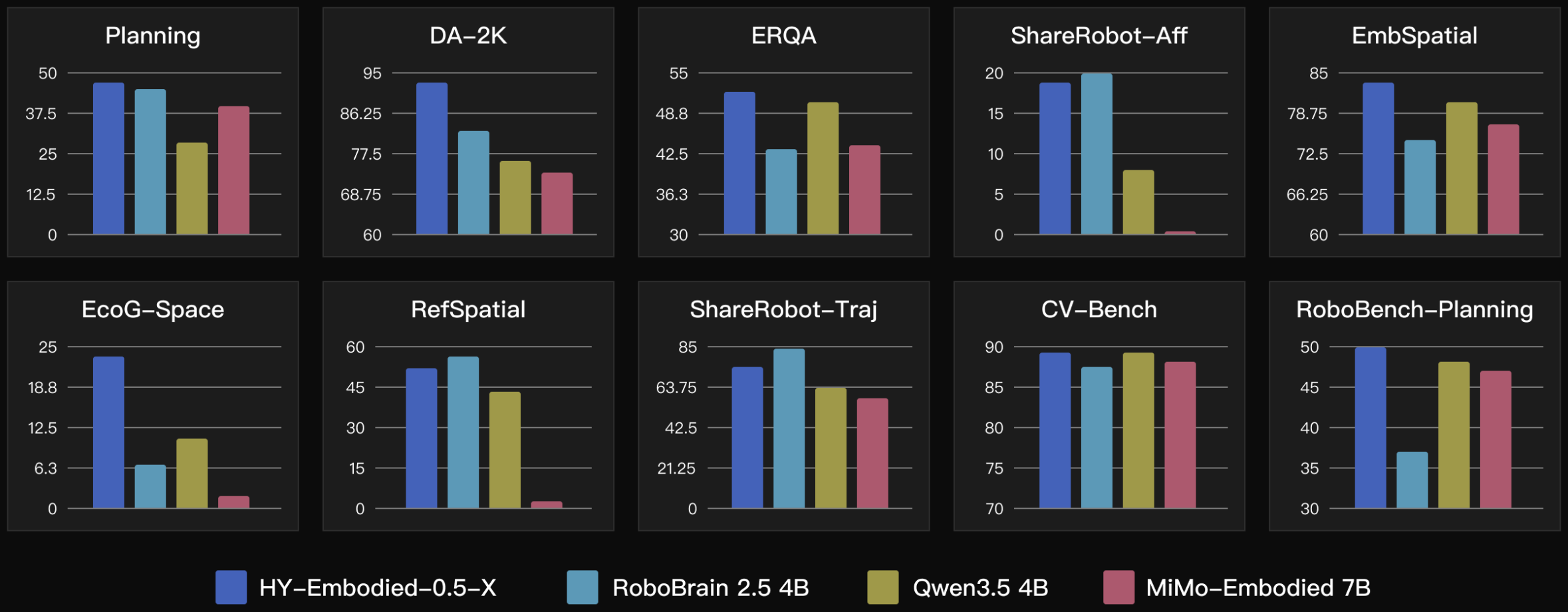
Across 10 open-source benchmarks covering planning, spatial reasoning, embodied QA, visual reference, and trajectory understanding, HY-Embodied-0.5-X stays in the top tier.
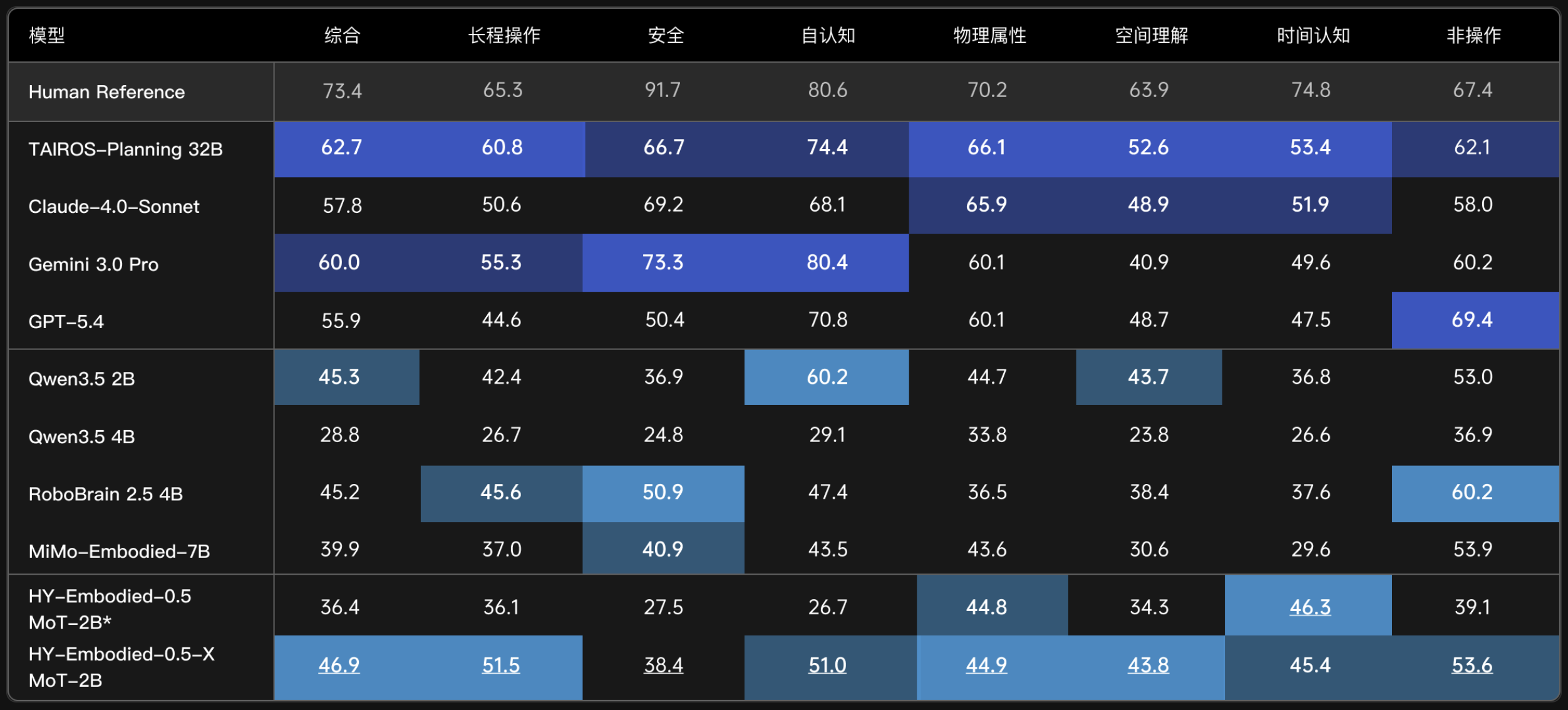
Additional results on an internal AI2Thor embodied-planning benchmark (1,011 tasks across four household scenes) show clear gains on long-horizon manipulation, self-awareness, and spatial understanding:
@article{tencent2026hyembodied05x,
title = {HY-Embodied-0.5-X: An Enhanced Embodied Foundation Model for Real-World Agents},
author = {Tencent Robotics X and HY Vision Team},
year = {2026}
}
Thanks to the Hugging Face community, and all open-source contributors. By open-sourcing HY-Embodied-0.5-X we hope to offer the embodied-AI community a more deployment-oriented foundation, and to push models from general understanding toward real-world execution.
Base model
tencent/HY-Embodied-0.5