text-generation-inference documentation
Text Generation Inference
Text Generation Inference
text-generation-inference is now in maintenance mode. Going forward, we will accept pull requests for minor bug fixes, documentation improvements and lightweight maintenance tasks.
TGI has initiated the movement for optimized inference engines to rely on a
transformersmodel architectures. This approach is now adopted by downstream inference engines, which we contribute to and recommend using going forward: vllm, SGLang, as well as local engines with inter-compatibility such as llama.cpp or MLX.
Text Generation Inference (TGI) is a toolkit for deploying and serving Large Language Models (LLMs). TGI enables high-performance text generation for the most popular open-source LLMs, including Llama, Falcon, StarCoder, BLOOM, GPT-NeoX, and T5.
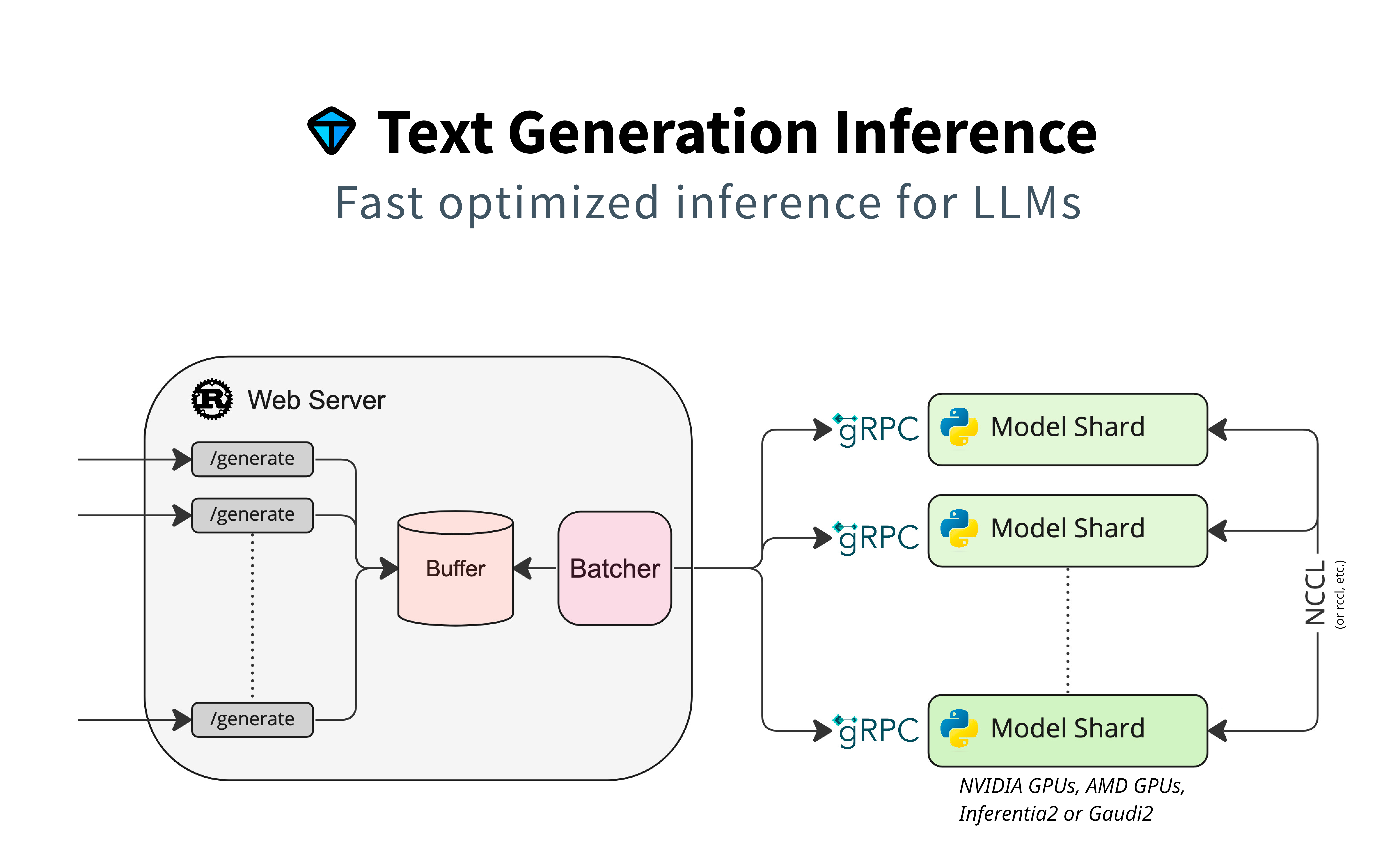
Text Generation Inference implements many optimizations and features, such as:
- Simple launcher to serve most popular LLMs
- Production ready (distributed tracing with Open Telemetry, Prometheus metrics)
- Tensor Parallelism for faster inference on multiple GPUs
- Token streaming using Server-Sent Events (SSE)
- Continuous batching of incoming requests for increased total throughput
- Optimized transformers code for inference using Flash Attention and Paged Attention on the most popular architectures
- Quantization with bitsandbytes and GPT-Q
- Safetensors weight loading
- Watermarking with A Watermark for Large Language Models
- Logits warper (temperature scaling, top-p, top-k, repetition penalty)
- Stop sequences
- Log probabilities
- Fine-tuning Support: Utilize fine-tuned models for specific tasks to achieve higher accuracy and performance.
- Guidance: Enable function calling and tool-use by forcing the model to generate structured outputs based on your own predefined output schemas.
Text Generation Inference is used in production by multiple projects, such as:
- Hugging Chat, an open-source interface for open-access models, such as Open Assistant and Llama
- OpenAssistant, an open-source community effort to train LLMs in the open
- nat.dev, a playground to explore and compare LLMs.