
File size: 10,653 Bytes
927b51b 5ac7876 927b51b a377976 927b51b 1563148 5ec3e7e 1563148 927b51b a377976 927b51b a377976 927b51b a377976 927b51b a377976 927b51b a377976 927b51b a377976 927b51b a377976 927b51b 3819636 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 |
---
license: apache-2.0
language:
- en
- de
- es
- fr
- it
- pt
- pl
- nl
- tr
- sv
- cs
- el
- hu
- ro
- fi
- uk
- sl
- sk
- da
- lt
- lv
- et
- bg
- 'no'
- ca
- hr
- ga
- mt
- gl
- zh
- ru
- ko
- ja
- ar
- hi
library_name: transformers
base_model:
- utter-project/EuroLLM-22B-2512
---
# Model Card for EuroLLM-22B-Instruct
This is the model card for EuroLLM-22B-Instruct. You can also check the pre-trained version: [EuroLLM-22B-2515](https://huggingface.co/utter-project/EuroLLM-22B-2512).
- **Developed by:** Instituto Superior Técnico - University of Lisbon, Instituto de Telecomunicações, University of Edinburgh, Aveni, Unbabel, University of Paris-Saclay, Artefact Research Center, University of Amsterdam, Naver Labs, Sorbonne Université.
- **Funded by:** European Union.
- **Model type:** A 22B parameter multilingual transfomer LLM.
- **Language(s) (NLP):** Bulgarian, Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, German, Greek, Hungarian, Irish, Italian, Latvian, Lithuanian, Maltese, Polish, Portuguese, Romanian, Slovak, Slovenian, Spanish, Swedish, Arabic, Catalan, Chinese, Galician, Hindi, Japanese, Korean, Norwegian, Russian, Turkish, and Ukrainian.
- **License:** Apache License 2.0.
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.12.2`
```yaml
auto_resume_from_checkpoints: true
use_tensorboard: true
base_model: utter-project/EuroLLM-22B-2512
model_type: AutoModelForCausalLM
tokenizer_type: AutoTokenizer
load_in_8bit: false
load_in_4bit: false
strict: false
dataset_processes: 64
datasets:
- path: utter-project/EuroBlocks-SFT-2512
type: chat_template
split: train
conversation: chatml
field_messages: conversations
message_field_role: role
message_field_content: content
roles_to_train: ["assistant"]
train_on_eos: all
chat_template_jinja: "{% for message in messages %}{% if message['role'] == 'assistant' %}{% set role = 'assistant' %}{% else %}{% set role = message['role'] %}{% endif %}<|im_start|>{{ role }}\n{{ message['content'] | trim }}<|im_end|>\n{% endfor %}{% if add_generation_prompt %}{{'<|im_start|>assistant\n'}}{% endif %}"
output_dir: checkpoints
val_set_size: 0
sequence_len: 32768
sample_packing: true
pad_to_sequence_len: true
# sequence_parallel_degree: 4
# heads_k_stride: 1
# ring_attn_func:
plugins:
- axolotl.integrations.liger.LigerPlugin
liger_rope: true
liger_rms_norm: true
liger_glu_activation: true
liger_layer_norm: true
liger_fused_linear_cross_entropy: true
# N_GPUS * GRAD_ACC_STEPS * MICRO_BATCH_SIZE * SEQ_LEN = tokens/step ->
# Assuming 32 gpus (32 * 2 * 2 * 32k = 4 096 000 tokens/step)
gradient_accumulation_steps: 2
micro_batch_size: 2
eval_batch_size: 1
num_epochs: 5
optimizer: adamw_torch
lr_scheduler: cosine
learning_rate: 1e-5
train_on_inputs: false
group_by_length: false
bf16: true
fp16: false
tf32: false
gradient_checkpointing: true
logging_steps: 1
flash_attention: true
flash_attn_cross_entropy: false
flash_attn_rms_norm: false
flash_attn_fuse_qkv: false
flash_attn_fuse_mlp: false
warmup_steps: 125
eval_sample_packing: False
save_steps: 500
save_total_limit: 2
deepspeed: deepspeed_configs/zero3_bf16.json
weight_decay: 0.01
special_tokens:
eos_token: "<|im_end|>"
```
</details><br>
## Model Details
The EuroLLM project has the goal of creating a suite of LLMs capable of understanding and generating text in all European Union languages as well as some additional relevant languages.
EuroLLM-22B is a 22B parameter model trained on 4 trillion tokens divided across the considered languages and several data sources: Web data, parallel data (en-xx and xx-en), and high-quality datasets.
EuroLLM-22B-Instruct was further instruction tuned on EuroBlocks, an instruction tuning dataset with focus on general instruction-following and machine translation.
### Architecture
EuroLLM uses a standard, dense Transformer architecture withgrouped query attention (GQA), pre-layer normalization with RMSNorm, SwiGLU activations and rotary positional embeddings (RoPE) in every layer. Here is a summary of the model hyper-parameters:
| | |
|--------------------------------------|----------------------|
| Sequence Length | 32,768 |
| Number of Layers | 56 |
| Embedding Size | 6,144 |
| FFN Hidden Size | 16,384 |
| Number of Heads | 48 |
| Number of KV Heads (GQA) | 8 |
| Activation Function | SwiGLU |
| Position Encodings | RoPE (\Theta=1,000,000) |
| Layer Norm | RMSNorm |
| Tied Embeddings | No |
| Embedding Parameters | 0.786B |
| LM Head Parameters | 0.786B |
| Non-embedding Parameters | 21.067B |
| Total Parameters | 22.639B |
### Pre-training
EuroLLM-22B was trained on approximately 4 trillion tokens, using 400 Nvidia H100 GPUs on the MareNostrum5 supercomputer, thanks to an EuroHPC extreme-scale access grant. The training process was carefully structured into three key phases:
<ol>
<li>Initial Pre-training (3.6 trillion tokens)
This phase includes the warm-up and constant learning rate stages, during which the model is trained on a mixture of web data alongside higher quality sources such as parallel data, Wikipedia, Arxiv, books, math, code and Apollo datasets. This balanced mix helps the model build a strong multilingual foundation.</li>
<li>Annealing (400 billion tokens) During this phase, there is a linear decay of the learning rate and we adjust the data mix to reduce the proportion of web data while increasing the multilingual content and select the highest quality data—by making use of quality filters such as [CometKiwi-22](https://huggingface.co/Unbabel/wmt22-cometkiwi-da) and [EuroFilter](https://huggingface.co/utter-project/EuroFilter-v1). This shift helps the model refine its understanding across diverse languages and domains.</li>
<li>Annealing to Zero (100 billion tokens) In this final stage, the learning rate decays linearly to zero. In this phase, the data mix was optimized to be of even higher quality, in order to polish the model's performance, and long context data sources were upsampled to increase the model context window to 32k tokens.</li>
</ol>
### Post-training
During post-training, we adapt EuroLLM to be an instruction-following model capable of handling multi-turn conversations. We start by regenerating the final responses from publicly available datasets using several open models, and keep the best candidate using a reward model. To this data, we add records from other datasets (Nemotron, Hermes-3 and Tulu 3), removing duplicates based on the first prompt. This pipeline shows how EuroLLM can be easily adapted for your use-cases.
The model excels at translation tasks being capable of translating across all official EU languages, matching or outperforming strong models like Gemma-3-27B, Qwen-3-32B and Apertus-70B. Furthermore, when it comes to general benchmarks, it is the best EU-made fully open model.
## Run the model
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "utter-project/EuroLLM-22B-Instruct-2512"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": "You are EuroLLM --- an AI assistant specialized in European languages that provides safe, educational and helpful answers.",
},
{
"role": "user", "content": "What is the capital of Portugal? How would you describe it?"
},
]
inputs = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=1024)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
## Results
### Multilingual

**Table 1:** Comparison of fully open and open-weight LLMs on a suite of multilingual benchmarks, averaging over all languages supported by EuroLLM-22B that are present in each benchmark. The table reports scores on HellaSwag, MMLU, MMLU-Pro, ARC-Challenge, MGSM, FLORES, and WMT24++. The Borda Count (Colombo et al., 2022) reflects the average ranking of each model across all benchmarks. <b>Bold</b> values indicate the best overall system for each benchmark, while <u>underscored</u> values denote the best fully open system.
### English
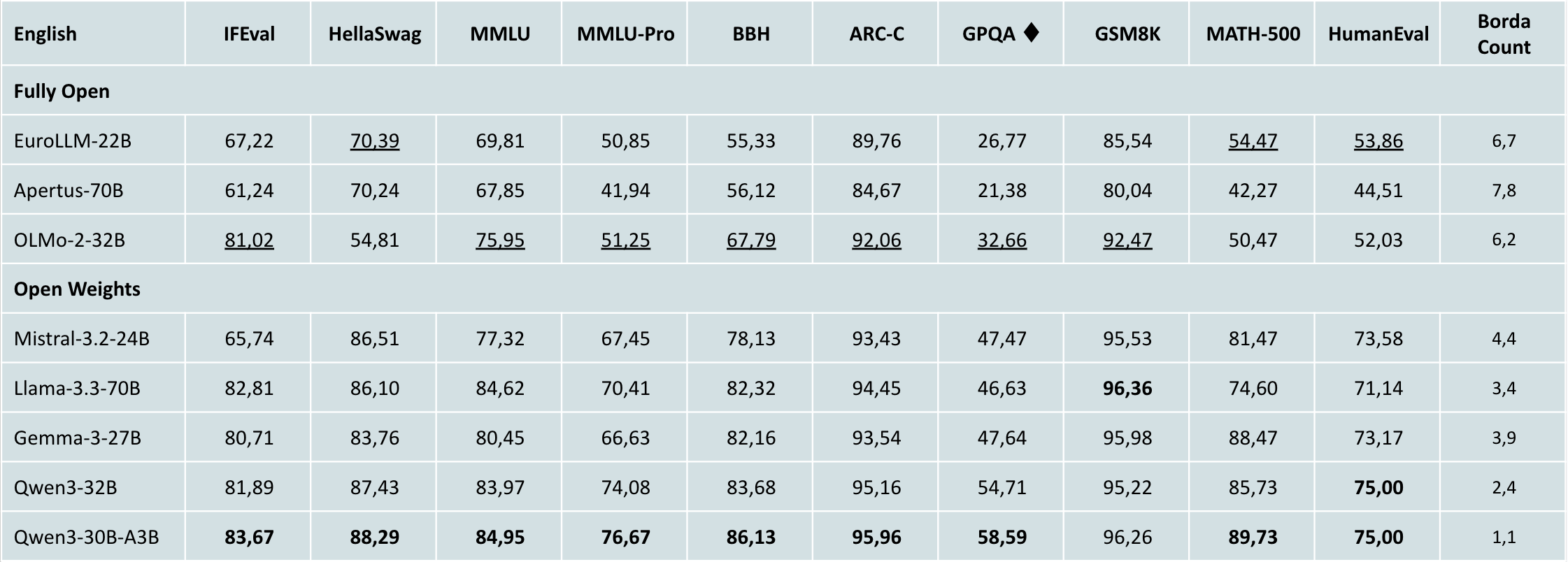
**Table 2:** Comparison of fully open and open-weight LLMs on a suite of English benchmarks. The table reports scores on IFEval, HellaSwag, MMLU, MMLU-Pro, BBH, ARC-Challenge, GPQA, GSM8K, MATH-500, and HumanEval. The Borda Count reflects the average ranking of each model across all benchmarks. <b>Bold</b> values indicate the best overall system for each benchmark, while <u>underscored</u> values denote the best fully open system.
## Bias, Risks, and Limitations
EuroLLM-22B has not been aligned to human preferences, so the model may generate problematic outputs (e.g., hallucinations, harmful content, or false statements).
## Citation
If you use our work, please cite:
```
@misc{ramos2026eurollm22btechnicalreport,
title={EuroLLM-22B: Technical Report},
author={Miguel Moura Ramos and Duarte M. Alves and Hippolyte Gisserot-Boukhlef and João Alves and Pedro Henrique Martins and Patrick Fernandes and José Pombal and Nuno M. Guerreiro and Ricardo Rei and Nicolas Boizard and Amin Farajian and Mateusz Klimaszewski and José G. C. de Souza and Barry Haddow and François Yvon and Pierre Colombo and Alexandra Birch and André F. T. Martins},
year={2026},
eprint={2602.05879},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2602.05879},
}
``` |