Get trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
MMBench-GUI: Hierarchical Multi-Platform Evaluation Framework for GUI Agents
We introduce MMBench-GUI, a hierarchical benchmark for evaluating GUI automation agents across Windows, macOS, Linux, iOS, Android, and Web platforms. It comprises four levels: GUI Content Understanding, Element Grounding, Task Automation, and Task Collaboration, covering essential skills for GUI agents. In addition, we propose a novel Efficiency-Quality Area (EQA) metric to assess GUI agent execution efficiency in online automation scenarios. Through MMBench-GUI, we identify accurate visual grounding as a critical determinant of overall task success, emphasizing the substantial benefits of modular frameworks that integrate specialized grounding modules. Furthermore, to achieve reliable GUI automation, an agent requires strong task planning and cross-platform generalization abilities, with long-context memory, a broad action space, and long-term reasoning playing a critical role. More important, task efficiency remains a critically underexplored dimension, and all models suffer from substantial inefficiencies, with excessive redundant steps even when tasks are ultimately completed. The integration of precise localization, effective planning, and early stopping strategies is indispensable to enable truly efficient and scalable GUI automation. Our benchmark code, evaluation data, and running environment will be publicly available at https://github.com/open-compass/MMBench-GUI.





FireRedChat: A Pluggable, Full-Duplex Voice Interaction System with Cascaded and Semi-Cascaded Implementations
Full-duplex voice interaction allows users and agents to speak simultaneously with controllable barge-in, enabling lifelike assistants and customer service. Existing solutions are either end-to-end, difficult to design and hard to control, or modular pipelines governed by turn-taking controllers that ease upgrades and per-module optimization; however, prior modular frameworks depend on non-open components and external providers, limiting holistic optimization. In this work, we present a complete, practical full-duplex voice interaction system comprising a turn-taking controller, an interaction module, and a dialogue manager. The controller integrates streaming personalized VAD (pVAD) to suppress false barge-ins from noise and non-primary speakers, precisely timestamp primary-speaker segments, and explicitly enable primary-speaker barge-ins; a semantic end-of-turn detector improves stop decisions. It upgrades heterogeneous half-duplex pipelines, cascaded, semi-cascaded, and speech-to-speech, to full duplex. Using internal models, we implement cascaded and semi-cascaded variants; the semi-cascaded one captures emotional and paralinguistic cues, yields more coherent responses, lowers latency and error propagation, and improves robustness. A dialogue manager extends capabilities via tool invocation and context management. We also propose three system-level metrics, barge-in, end-of-turn detection accuracy, and end-to-end latency, to assess naturalness, control accuracy, and efficiency. Experiments show fewer false interruptions, more accurate semantic ends, and lower latency approaching industrial systems, enabling robust, natural, real-time full-duplex interaction. Demos: https://fireredteam.github.io/demos/firered_chat.
Deep Research Agents: A Systematic Examination And Roadmap
The rapid progress of Large Language Models (LLMs) has given rise to a new category of autonomous AI systems, referred to as Deep Research (DR) agents. These agents are designed to tackle complex, multi-turn informational research tasks by leveraging a combination of dynamic reasoning, adaptive long-horizon planning, multi-hop information retrieval, iterative tool use, and the generation of structured analytical reports. In this paper, we conduct a detailed analysis of the foundational technologies and architectural components that constitute Deep Research agents. We begin by reviewing information acquisition strategies, contrasting API-based retrieval methods with browser-based exploration. We then examine modular tool-use frameworks, including code execution, multimodal input processing, and the integration of Model Context Protocols (MCPs) to support extensibility and ecosystem development. To systematize existing approaches, we propose a taxonomy that differentiates between static and dynamic workflows, and we classify agent architectures based on planning strategies and agent composition, including single-agent and multi-agent configurations. We also provide a critical evaluation of current benchmarks, highlighting key limitations such as restricted access to external knowledge, sequential execution inefficiencies, and misalignment between evaluation metrics and the practical objectives of DR agents. Finally, we outline open challenges and promising directions for future research. A curated and continuously updated repository of DR agent research is available at: {https://github.com/ai-agents-2030/awesome-deep-research-agent}.


LMTuner: An user-friendly and highly-integrable Training Framework for fine-tuning Large Language Models
With the burgeoning development in the realm of large language models (LLMs), the demand for efficient incremental training tailored to specific industries and domains continues to increase. Currently, the predominantly employed frameworks lack modular design, it often takes a lot of coding work to kickstart the training of LLM. To address this, we present "LMTuner", a highly usable, integrable, and scalable system for training LLMs expeditiously and with minimal user-input. LMTuner comprises three main modules - the Interaction, Training, and Inference Modules. We advocate that LMTuner's usability and integrality alleviate the complexities in training large language models. Remarkably, even a novice user could commence training large language models within five minutes. Furthermore, it integrates DeepSpeed frameworks and supports Efficient Fine-Tuning methodologies like Low Rank Adaptation (LoRA), Quantized LoRA (QLoRA), etc., enabling the training of language models scaling from 300M to a whopping 130B parameters using a single server. The LMTuner's homepage (https://wengsyx.github.io/LMTuner/)and screencast video (https://youtu.be/nsXmWOmN3rE) are now publicly available.


Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks
Retrieval-augmented Generation (RAG) has markedly enhanced the capabilities of Large Language Models (LLMs) in tackling knowledge-intensive tasks. The increasing demands of application scenarios have driven the evolution of RAG, leading to the integration of advanced retrievers, LLMs and other complementary technologies, which in turn has amplified the intricacy of RAG systems. However, the rapid advancements are outpacing the foundational RAG paradigm, with many methods struggling to be unified under the process of "retrieve-then-generate". In this context, this paper examines the limitations of the existing RAG paradigm and introduces the modular RAG framework. By decomposing complex RAG systems into independent modules and specialized operators, it facilitates a highly reconfigurable framework. Modular RAG transcends the traditional linear architecture, embracing a more advanced design that integrates routing, scheduling, and fusion mechanisms. Drawing on extensive research, this paper further identifies prevalent RAG patterns-linear, conditional, branching, and looping-and offers a comprehensive analysis of their respective implementation nuances. Modular RAG presents innovative opportunities for the conceptualization and deployment of RAG systems. Finally, the paper explores the potential emergence of new operators and paradigms, establishing a solid theoretical foundation and a practical roadmap for the continued evolution and practical deployment of RAG technologies.
torchdistill: A Modular, Configuration-Driven Framework for Knowledge Distillation
While knowledge distillation (transfer) has been attracting attentions from the research community, the recent development in the fields has heightened the need for reproducible studies and highly generalized frameworks to lower barriers to such high-quality, reproducible deep learning research. Several researchers voluntarily published frameworks used in their knowledge distillation studies to help other interested researchers reproduce their original work. Such frameworks, however, are usually neither well generalized nor maintained, thus researchers are still required to write a lot of code to refactor/build on the frameworks for introducing new methods, models, datasets and designing experiments. In this paper, we present our developed open-source framework built on PyTorch and dedicated for knowledge distillation studies. The framework is designed to enable users to design experiments by declarative PyYAML configuration files, and helps researchers complete the recently proposed ML Code Completeness Checklist. Using the developed framework, we demonstrate its various efficient training strategies, and implement a variety of knowledge distillation methods. We also reproduce some of their original experimental results on the ImageNet and COCO datasets presented at major machine learning conferences such as ICLR, NeurIPS, CVPR and ECCV, including recent state-of-the-art methods. All the source code, configurations, log files and trained model weights are publicly available at https://github.com/yoshitomo-matsubara/torchdistill .

Flow: A Modular Approach to Automated Agentic Workflow Generation
Multi-agent frameworks powered by large language models (LLMs) have demonstrated great success in automated planning and task execution. However, the effective adjustment of Agentic workflows during execution has not been well-studied. A effective workflow adjustment is crucial, as in many real-world scenarios, the initial plan must adjust to unforeseen challenges and changing conditions in real-time to ensure the efficient execution of complex tasks. In this paper, we define workflows as an activity-on-vertex (AOV) graphs. We continuously refine the workflow by dynamically adjusting task allocations based on historical performance and previous AOV with LLM agents. To further enhance system performance, we emphasize modularity in workflow design based on measuring parallelism and dependence complexity. Our proposed multi-agent framework achieved efficient sub-task concurrent execution, goal achievement, and error tolerance. Empirical results across different practical tasks demonstrate dramatic improvements in the efficiency of multi-agent frameworks through dynamic workflow updating and modularization.
A System for Comprehensive Assessment of RAG Frameworks
Retrieval Augmented Generation (RAG) has emerged as a standard paradigm for enhancing the factual accuracy and contextual relevance of Large Language Models (LLMs) by integrating retrieval mechanisms. However, existing evaluation frameworks fail to provide a holistic black-box approach to assessing RAG systems, especially in real-world deployment scenarios. To address this gap, we introduce SCARF (System for Comprehensive Assessment of RAG Frameworks), a modular and flexible evaluation framework designed to benchmark deployed RAG applications systematically. SCARF provides an end-to-end, black-box evaluation methodology, enabling a limited-effort comparison across diverse RAG frameworks. Our framework supports multiple deployment configurations and facilitates automated testing across vector databases and LLM serving strategies, producing a detailed performance report. Moreover, SCARF integrates practical considerations such as response coherence, providing a scalable and adaptable solution for researchers and industry professionals evaluating RAG applications. Using the REST APIs interface, we demonstrate how SCARF can be applied to real-world scenarios, showcasing its flexibility in assessing different RAG frameworks and configurations. SCARF is available at GitHub repository.
Amico: An Event-Driven Modular Framework for Persistent and Embedded Autonomy
Recent advances in large language models (LLMs) and autonomous agents have enabled systems capable of performing complex tasks across domains such as human-computer interaction, planning, and web navigation. However, many existing frameworks struggle in real-world or resource-constrained environments due to their reliance on cloud-based computation, limited robustness in dynamic contexts, and lack of persistent autonomy and environmental awareness. We present Amico, a modular, event-driven framework for building autonomous agents optimized for embedded systems. Written in Rust for safety and performance, Amico supports reactive, persistent agents that operate efficiently across embedded platforms and browser environments via WebAssembly. It provides clean abstractions for event handling, state management, behavior execution, and integration with reasoning modules. Amico delivers a unified infrastructure for constructing resilient, interactive agents suitable for deployment in settings with limited compute and intermittent connectivity.
Who's the MVP? A Game-Theoretic Evaluation Benchmark for Modular Attribution in LLM Agents
Large Language Model (LLM) agents frameworks often employ modular architectures, incorporating components such as planning, reasoning, action execution, and reflection to tackle complex tasks. However, quantifying the contribution of each module to overall system performance remains a significant challenge, impeding optimization and interpretability. To address this, we introduce CapaBench (Capability-level Assessment Benchmark), an evaluation framework grounded in cooperative game theory's Shapley Value, which systematically measures the marginal impact of individual modules and their interactions within an agent's architecture. By replacing default modules with test variants across all possible combinations, CapaBench provides a principle method for attributing performance contributions. Key contributions include: (1) We are the first to propose a Shapley Value-based methodology for quantifying the contributions of capabilities in LLM agents; (2) Modules with high Shapley Values consistently lead to predictable performance gains when combined, enabling targeted optimization; and (3) We build a multi-round dataset of over 1,500 entries spanning diverse domains and practical task scenarios, enabling comprehensive evaluation of agent capabilities. CapaBench bridges the gap between component-level evaluation and holistic system assessment, providing actionable insights for optimizing modular LLM agents and advancing their deployment in complex, real-world scenarios.
MC-CoT: A Modular Collaborative CoT Framework for Zero-shot Medical-VQA with LLM and MLLM Integration
In recent advancements, multimodal large language models (MLLMs) have been fine-tuned on specific medical image datasets to address medical visual question answering (Med-VQA) tasks. However, this common approach of task-specific fine-tuning is costly and necessitates separate models for each downstream task, limiting the exploration of zero-shot capabilities. In this paper, we introduce MC-CoT, a modular cross-modal collaboration Chain-of-Thought (CoT) framework designed to enhance the zero-shot performance of MLLMs in Med-VQA by leveraging large language models (LLMs). MC-CoT improves reasoning and information extraction by integrating medical knowledge and task-specific guidance, where LLM provides various complex medical reasoning chains and MLLM provides various observations of medical images based on instructions of the LLM. Our experiments on datasets such as SLAKE, VQA-RAD, and PATH-VQA show that MC-CoT surpasses standalone MLLMs and various multimodality CoT frameworks in recall rate and accuracy. These findings highlight the importance of incorporating background information and detailed guidance in addressing complex zero-shot Med-VQA tasks.

Converse: A Tree-Based Modular Task-Oriented Dialogue System
Creating a system that can have meaningful conversations with humans to help accomplish tasks is one of the ultimate goals of Artificial Intelligence (AI). It has defined the meaning of AI since the beginning. A lot has been accomplished in this area recently, with voice assistant products entering our daily lives and chat bot systems becoming commonplace in customer service. At first glance there seems to be no shortage of options for dialogue systems. However, the frequently deployed dialogue systems today seem to all struggle with a critical weakness - they are hard to build and harder to maintain. At the core of the struggle is the need to script every single turn of interactions between the bot and the human user. This makes the dialogue systems more difficult to maintain as the tasks become more complex and more tasks are added to the system. In this paper, we propose Converse, a flexible tree-based modular task-oriented dialogue system. Converse uses an and-or tree structure to represent tasks and offers powerful multi-task dialogue management. Converse supports task dependency and task switching, which are unique features compared to other open-source dialogue frameworks. At the same time, Converse aims to make the bot building process easy and simple, for both professional and non-professional software developers. The code is available at https://github.com/salesforce/Converse.





A Survey on LLM Test-Time Compute via Search: Tasks, LLM Profiling, Search Algorithms, and Relevant Frameworks
LLM test-time compute (or LLM inference) via search has emerged as a promising research area with rapid developments. However, current frameworks often adopt distinct perspectives on three key aspects (task definition, LLM profiling, and search procedures), making direct comparisons challenging. Moreover, the search algorithms employed often diverge from standard implementations, and their specific characteristics are not thoroughly specified. In this survey, we provide a comprehensive technical review that unifies task definitions and provides modular definitions of LLM profiling and search procedures. The definitions enable precise comparisons of various LLM inference frameworks while highlighting their departures from conventional search algorithms. We also discuss the applicability, performance, and efficiency of these methods. For further details and ongoing updates, please refer to our GitHub repository: https://github.com/xinzhel/LLM-Agent-Survey/blob/main/search.md

ReasonBENCH: Benchmarking the (In)Stability of LLM Reasoning
Large language models (LLMs) are increasingly deployed in settings where reasoning, such as multi-step problem solving and chain-of-thought, is essential. Yet, current evaluation practices overwhelmingly report single-run accuracy while ignoring the intrinsic uncertainty that naturally arises from stochastic decoding. This omission creates a blind spot because practitioners cannot reliably assess whether a method's reported performance is stable, reproducible, or cost-consistent. We introduce ReasonBENCH, the first benchmark designed to quantify the underlying instability in LLM reasoning. ReasonBENCH provides (i) a modular evaluation library that standardizes reasoning frameworks, models, and tasks, (ii) a multi-run protocol that reports statistically reliable metrics for both quality and cost, and (iii) a public leaderboard to encourage variance-aware reporting. Across tasks from different domains, we find that the vast majority of reasoning strategies and models exhibit high instability. Notably, even strategies with similar average performance can display confidence intervals up to four times wider, and the top-performing methods often incur higher and less stable costs. Such instability compromises reproducibility across runs and, consequently, the reliability of reported performance. To better understand these dynamics, we further analyze the impact of prompts, model families, and scale on the trade-off between solve rate and stability. Our results highlight reproducibility as a critical dimension for reliable LLM reasoning and provide a foundation for future reasoning methods and uncertainty quantification techniques. ReasonBENCH is publicly available at https://github.com/au-clan/ReasonBench .
pyhgf: A neural network library for predictive coding
Bayesian models of cognition have gained considerable traction in computational neuroscience and psychiatry. Their scopes are now expected to expand rapidly to artificial intelligence, providing general inference frameworks to support embodied, adaptable, and energy-efficient autonomous agents. A central theory in this domain is predictive coding, which posits that learning and behaviour are driven by hierarchical probabilistic inferences about the causes of sensory inputs. Biological realism constrains these networks to rely on simple local computations in the form of precision-weighted predictions and prediction errors. This can make this framework highly efficient, but its implementation comes with unique challenges on the software development side. Embedding such models in standard neural network libraries often becomes limiting, as these libraries' compilation and differentiation backends can force a conceptual separation between optimization algorithms and the systems being optimized. This critically departs from other biological principles such as self-monitoring, self-organisation, cellular growth and functional plasticity. In this paper, we introduce pyhgf: a Python package backed by JAX and Rust for creating, manipulating and sampling dynamic networks for predictive coding. We improve over other frameworks by enclosing the network components as transparent, modular and malleable variables in the message-passing steps. The resulting graphs can implement arbitrary computational complexities as beliefs propagation. But the transparency of core variables can also translate into inference processes that leverage self-organisation principles, and express structure learning, meta-learning or causal discovery as the consequence of network structural adaptation to surprising inputs. The code, tutorials and documentation are hosted at: https://github.com/ilabcode/pyhgf.

From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review
Large language models and autonomous AI agents have evolved rapidly, resulting in a diverse array of evaluation benchmarks, frameworks, and collaboration protocols. However, the landscape remains fragmented and lacks a unified taxonomy or comprehensive survey. Therefore, we present a side-by-side comparison of benchmarks developed between 2019 and 2025 that evaluate these models and agents across multiple domains. In addition, we propose a taxonomy of approximately 60 benchmarks that cover general and academic knowledge reasoning, mathematical problem-solving, code generation and software engineering, factual grounding and retrieval, domain-specific evaluations, multimodal and embodied tasks, task orchestration, and interactive assessments. Furthermore, we review AI-agent frameworks introduced between 2023 and 2025 that integrate large language models with modular toolkits to enable autonomous decision-making and multi-step reasoning. Moreover, we present real-world applications of autonomous AI agents in materials science, biomedical research, academic ideation, software engineering, synthetic data generation, chemical reasoning, mathematical problem-solving, geographic information systems, multimedia, healthcare, and finance. We then survey key agent-to-agent collaboration protocols, namely the Agent Communication Protocol (ACP), the Model Context Protocol (MCP), and the Agent-to-Agent Protocol (A2A). Finally, we discuss recommendations for future research, focusing on advanced reasoning strategies, failure modes in multi-agent LLM systems, automated scientific discovery, dynamic tool integration via reinforcement learning, integrated search capabilities, and security vulnerabilities in agent protocols.

Large Language Models to Enhance Bayesian Optimization
Bayesian optimization (BO) is a powerful approach for optimizing complex and expensive-to-evaluate black-box functions. Its importance is underscored in many applications, notably including hyperparameter tuning, but its efficacy depends on efficiently balancing exploration and exploitation. While there has been substantial progress in BO methods, striking this balance remains a delicate process. In this light, we present LLAMBO, a novel approach that integrates the capabilities of Large Language Models (LLM) within BO. At a high level, we frame the BO problem in natural language, enabling LLMs to iteratively propose and evaluate promising solutions conditioned on historical evaluations. More specifically, we explore how combining contextual understanding, few-shot learning proficiency, and domain knowledge of LLMs can improve model-based BO. Our findings illustrate that LLAMBO is effective at zero-shot warmstarting, and enhances surrogate modeling and candidate sampling, especially in the early stages of search when observations are sparse. Our approach is performed in context and does not require LLM finetuning. Additionally, it is modular by design, allowing individual components to be integrated into existing BO frameworks, or function cohesively as an end-to-end method. We empirically validate LLAMBO's efficacy on the problem of hyperparameter tuning, highlighting strong empirical performance across a range of diverse benchmarks, proprietary, and synthetic tasks.
EvoGit: Decentralized Code Evolution via Git-Based Multi-Agent Collaboration
We introduce EvoGit, a decentralized multi-agent framework for collaborative software development driven by autonomous code evolution. EvoGit deploys a population of independent coding agents, each proposing edits to a shared codebase without centralized coordination, explicit message passing, or shared memory. Instead, all coordination emerges through a Git-based phylogenetic graph that tracks the full version lineage and enables agents to asynchronously read from and write to the evolving code repository. This graph-based structure supports fine-grained branching, implicit concurrency, and scalable agent interaction while preserving a consistent historical record. Human involvement is minimal but strategic: users define high-level goals, periodically review the graph, and provide lightweight feedback to promote promising directions or prune unproductive ones. Experiments demonstrate EvoGit's ability to autonomously produce functional and modular software artifacts across two real-world tasks: (1) building a web application from scratch using modern frameworks, and (2) constructing a meta-level system that evolves its own language-model-guided solver for the bin-packing optimization problem. Our results underscore EvoGit's potential to establish a new paradigm for decentralized, automated, and continual software development. EvoGit is open-sourced at https://github.com/BillHuang2001/evogit.


Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
Reasoning lies at the heart of intelligence, shaping the ability to make decisions, draw conclusions, and generalize across domains. In artificial intelligence, as systems increasingly operate in open, uncertain, and multimodal environments, reasoning becomes essential for enabling robust and adaptive behavior. Large Multimodal Reasoning Models (LMRMs) have emerged as a promising paradigm, integrating modalities such as text, images, audio, and video to support complex reasoning capabilities and aiming to achieve comprehensive perception, precise understanding, and deep reasoning. As research advances, multimodal reasoning has rapidly evolved from modular, perception-driven pipelines to unified, language-centric frameworks that offer more coherent cross-modal understanding. While instruction tuning and reinforcement learning have improved model reasoning, significant challenges remain in omni-modal generalization, reasoning depth, and agentic behavior. To address these issues, we present a comprehensive and structured survey of multimodal reasoning research, organized around a four-stage developmental roadmap that reflects the field's shifting design philosophies and emerging capabilities. First, we review early efforts based on task-specific modules, where reasoning was implicitly embedded across stages of representation, alignment, and fusion. Next, we examine recent approaches that unify reasoning into multimodal LLMs, with advances such as Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning enabling richer and more structured reasoning chains. Finally, drawing on empirical insights from challenging benchmarks and experimental cases of OpenAI O3 and O4-mini, we discuss the conceptual direction of native large multimodal reasoning models (N-LMRMs), which aim to support scalable, agentic, and adaptive reasoning and planning in complex, real-world environments.

Value Kaleidoscope: Engaging AI with Pluralistic Human Values, Rights, and Duties
Human values are crucial to human decision-making. Value pluralism is the view that multiple correct values may be held in tension with one another (e.g., when considering lying to a friend to protect their feelings, how does one balance honesty with friendship?). As statistical learners, AI systems fit to averages by default, washing out these potentially irreducible value conflicts. To improve AI systems to better reflect value pluralism, the first-order challenge is to explore the extent to which AI systems can model pluralistic human values, rights, and duties as well as their interaction. We introduce ValuePrism, a large-scale dataset of 218k values, rights, and duties connected to 31k human-written situations. ValuePrism's contextualized values are generated by GPT-4 and deemed high-quality by human annotators 91% of the time. We conduct a large-scale study with annotators across diverse social and demographic backgrounds to try to understand whose values are represented. With ValuePrism, we build Kaleido, an open, light-weight, and structured language-based multi-task model that generates, explains, and assesses the relevance and valence (i.e., support or oppose) of human values, rights, and duties within a specific context. Humans prefer the sets of values output by our system over the teacher GPT-4, finding them more accurate and with broader coverage. In addition, we demonstrate that Kaleido can help explain variability in human decision-making by outputting contrasting values. Finally, we show that Kaleido's representations transfer to other philosophical frameworks and datasets, confirming the benefit of an explicit, modular, and interpretable approach to value pluralism. We hope that our work will serve as a step to making more explicit the implicit values behind human decision-making and to steering AI systems to make decisions that are more in accordance with them.


Promptomatix: An Automatic Prompt Optimization Framework for Large Language Models
Large Language Models (LLMs) perform best with well-crafted prompts, yet prompt engineering remains manual, inconsistent, and inaccessible to non-experts. We introduce Promptomatix, an automatic prompt optimization framework that transforms natural language task descriptions into high-quality prompts without requiring manual tuning or domain expertise. Promptomatix supports both a lightweight meta-prompt-based optimizer and a DSPy-powered compiler, with modular design enabling future extension to more advanced frameworks. The system analyzes user intent, generates synthetic training data, selects prompting strategies, and refines prompts using cost-aware objectives. Evaluated across 5 task categories, Promptomatix achieves competitive or superior performance compared to existing libraries, while reducing prompt length and computational overhead making prompt optimization scalable and efficient.

Latte: Cross-framework Python Package for Evaluation of Latent-Based Generative Models
Latte (for LATent Tensor Evaluation) is a Python library for evaluation of latent-based generative models in the fields of disentanglement learning and controllable generation. Latte is compatible with both PyTorch and TensorFlow/Keras, and provides both functional and modular APIs that can be easily extended to support other deep learning frameworks. Using NumPy-based and framework-agnostic implementation, Latte ensures reproducible, consistent, and deterministic metric calculations regardless of the deep learning framework of choice.



Optimizing the Interface Between Knowledge Graphs and LLMs for Complex Reasoning
Integrating Large Language Models (LLMs) with Knowledge Graphs (KGs) results in complex systems with numerous hyperparameters that directly affect performance. While such systems are increasingly common in retrieval-augmented generation, the role of systematic hyperparameter optimization remains underexplored. In this paper, we study this problem in the context of Cognee, a modular framework for end-to-end KG construction and retrieval. Using three multi-hop QA benchmarks (HotPotQA, TwoWikiMultiHop, and MuSiQue) we optimize parameters related to chunking, graph construction, retrieval, and prompting. Each configuration is scored using established metrics (exact match, F1, and DeepEval's LLM-based correctness metric). Our results demonstrate that meaningful gains can be achieved through targeted tuning. While the gains are consistent, they are not uniform, with performance varying across datasets and metrics. This variability highlights both the value of tuning and the limitations of standard evaluation measures. While demonstrating the immediate potential of hyperparameter tuning, we argue that future progress will depend not only on architectural advances but also on clearer frameworks for optimization and evaluation in complex, modular systems.
ISCS: Parameter-Guided Channel Ordering and Grouping for Learned Image Compression
Prior studies in learned image compression (LIC) consistently show that only a small subset of latent channels is critical for reconstruction, while many others carry limited information. Exploiting this imbalance could improve both coding and computational efficiency, yet existing approaches often rely on costly, dataset-specific ablation tests and typically analyze channels in isolation, ignoring their interdependencies. We propose a generalizable, dataset-agnostic method to identify and organize important channels in pretrained VAE-based LIC models. Instead of brute-force empirical evaluations, our approach leverages intrinsic parameter statistics-weight variances, bias magnitudes, and pairwise correlations-to estimate channel importance. This analysis reveals a consistent organizational structure, termed the Invariant Salient Channel Space (ISCS), where Salient-Core channels capture dominant structures and Salient-Auxiliary channels provide complementary details. Building on ISCS, we introduce a deterministic channel ordering and grouping strategy that enables slice-parallel decoding, reduces redundancy, and improves bitrate efficiency. Experiments across multiple LIC architectures demonstrate that our method effectively reduces bitrate and computation while maintaining reconstruction quality, providing a practical and modular enhancement to existing learned compression frameworks.
SCREWS: A Modular Framework for Reasoning with Revisions
Large language models (LLMs) can improve their accuracy on various tasks through iteratively refining and revising their output based on feedback. We observe that these revisions can introduce errors, in which case it is better to roll back to a previous result. Further, revisions are typically homogeneous: they use the same reasoning method that produced the initial answer, which may not correct errors. To enable exploration in this space, we present SCREWS, a modular framework for reasoning with revisions. It is comprised of three main modules: Sampling, Conditional Resampling, and Selection, each consisting of sub-modules that can be hand-selected per task. We show that SCREWS not only unifies several previous approaches under a common framework, but also reveals several novel strategies for identifying improved reasoning chains. We evaluate our framework with state-of-the-art LLMs (ChatGPT and GPT-4) on a diverse set of reasoning tasks and uncover useful new reasoning strategies for each: arithmetic word problems, multi-hop question answering, and code debugging. Heterogeneous revision strategies prove to be important, as does selection between original and revised candidates.



HoneyBee: A Scalable Modular Framework for Creating Multimodal Oncology Datasets with Foundational Embedding Models
Developing accurate machine learning models for oncology requires large-scale, high-quality multimodal datasets. However, creating such datasets remains challenging due to the complexity and heterogeneity of medical data. To address this challenge, we introduce HoneyBee, a scalable modular framework for building multimodal oncology datasets that leverages foundational models to generate representative embeddings. HoneyBee integrates various data modalities, including clinical records, imaging data, and patient outcomes. It employs data preprocessing techniques and transformer-based architectures to generate embeddings that capture the essential features and relationships within the raw medical data. The generated embeddings are stored in a structured format using Hugging Face datasets and PyTorch dataloaders for accessibility. Vector databases enable efficient querying and retrieval for machine learning applications. We demonstrate the effectiveness of HoneyBee through experiments assessing the quality and representativeness of the embeddings. The framework is designed to be extensible to other medical domains and aims to accelerate oncology research by providing high-quality, machine learning-ready datasets. HoneyBee is an ongoing open-source effort, and the code, datasets, and models are available at the project repository.



TractoEmbed: Modular Multi-level Embedding framework for white matter tract segmentation
White matter tract segmentation is crucial for studying brain structural connectivity and neurosurgical planning. However, segmentation remains challenging due to issues like class imbalance between major and minor tracts, structural similarity, subject variability, symmetric streamlines between hemispheres etc. To address these challenges, we propose TractoEmbed, a modular multi-level embedding framework, that encodes localized representations through learning tasks in respective encoders. In this paper, TractoEmbed introduces a novel hierarchical streamline data representation that captures maximum spatial information at each level i.e. individual streamlines, clusters, and patches. Experiments show that TractoEmbed outperforms state-of-the-art methods in white matter tract segmentation across different datasets, and spanning various age groups. The modular framework directly allows the integration of additional embeddings in future works.

Nerfstudio: A Modular Framework for Neural Radiance Field Development
Neural Radiance Fields (NeRF) are a rapidly growing area of research with wide-ranging applications in computer vision, graphics, robotics, and more. In order to streamline the development and deployment of NeRF research, we propose a modular PyTorch framework, Nerfstudio. Our framework includes plug-and-play components for implementing NeRF-based methods, which make it easy for researchers and practitioners to incorporate NeRF into their projects. Additionally, the modular design enables support for extensive real-time visualization tools, streamlined pipelines for importing captured in-the-wild data, and tools for exporting to video, point cloud and mesh representations. The modularity of Nerfstudio enables the development of Nerfacto, our method that combines components from recent papers to achieve a balance between speed and quality, while also remaining flexible to future modifications. To promote community-driven development, all associated code and data are made publicly available with open-source licensing at https://nerf.studio.
DeepA2: A Modular Framework for Deep Argument Analysis with Pretrained Neural Text2Text Language Models
In this paper, we present and implement a multi-dimensional, modular framework for performing deep argument analysis (DeepA2) using current pre-trained language models (PTLMs). ArgumentAnalyst -- a T5 model (Raffel et al. 2020) set up and trained within DeepA2 -- reconstructs argumentative texts, which advance an informal argumentation, as valid arguments: It inserts, e.g., missing premises and conclusions, formalizes inferences, and coherently links the logical reconstruction to the source text. We create a synthetic corpus for deep argument analysis, and evaluate ArgumentAnalyst on this new dataset as well as on existing data, specifically EntailmentBank (Dalvi et al. 2021). Our empirical findings vindicate the overall framework and highlight the advantages of a modular design, in particular its ability to emulate established heuristics (such as hermeneutic cycles), to explore the model's uncertainty, to cope with the plurality of correct solutions (underdetermination), and to exploit higher-order evidence.


Pico: A Modular Framework for Hypothesis-Driven Small Language Model Research
Building language models (LMs), especially small and medium ones, remains more art than science. While large LMs often improve by sheer scale, it is still unclear why many design choices work. For small LMs, this uncertainty is more limiting: tight parameter budgets make each decision critical, yet researchers still lack systematic, scientific ways to test and refine new ideas. We introduce Pico, a lightweight, modular framework that enables systematic, hypothesis-driven research for small and medium-scale language model development. Pico consists of two libraries that together provide a practical sandbox where researchers can make targeted changes to a model's architecture or training procedures and directly observe their effects on the model's behavior. To support reproducible experimentation, we also release a suite of baseline models, pico-decoder, trained under standardized conditions and open-sourced for the community. Case studies highlight how Pico can support iterative small LM design and analysis.

MoMa: A Modular Deep Learning Framework for Material Property Prediction
Deep learning methods for material property prediction have been widely explored to advance materials discovery. However, the prevailing pre-train then fine-tune paradigm often fails to address the inherent diversity and disparity of material tasks. To overcome these challenges, we introduce MoMa, a Modular framework for Materials that first trains specialized modules across a wide range of tasks and then adaptively composes synergistic modules tailored to each downstream scenario. Evaluation across 17 datasets demonstrates the superiority of MoMa, with a substantial 14% average improvement over the strongest baseline. Few-shot and continual learning experiments further highlight MoMa's potential for real-world applications. Pioneering a new paradigm of modular material learning, MoMa will be open-sourced to foster broader community collaboration.
PyTorch Frame: A Modular Framework for Multi-Modal Tabular Learning
We present PyTorch Frame, a PyTorch-based framework for deep learning over multi-modal tabular data. PyTorch Frame makes tabular deep learning easy by providing a PyTorch-based data structure to handle complex tabular data, introducing a model abstraction to enable modular implementation of tabular models, and allowing external foundation models to be incorporated to handle complex columns (e.g., LLMs for text columns). We demonstrate the usefulness of PyTorch Frame by implementing diverse tabular models in a modular way, successfully applying these models to complex multi-modal tabular data, and integrating our framework with PyTorch Geometric, a PyTorch library for Graph Neural Networks (GNNs), to perform end-to-end learning over relational databases.

Language hooks: a modular framework for augmenting LLM reasoning that decouples tool usage from the model and its prompt
Prompting and fine-tuning have emerged as two competing paradigms for augmenting language models with new capabilities, such as the use of tools. Prompting approaches are quick to set up but rely on providing explicit demonstrations of each tool's usage in the model's prompt, thus coupling tool use to the task at hand and limiting generalisation. Fine-tuning removes the need for task-specific demonstrations of tool usage at runtime; however, this ties new capabilities to a single model, thus making already-heavier setup costs a recurring expense. In this paper, we introduce language hooks, a novel framework for augmenting language models with new capabilities that is decoupled both from the model's task-specific prompt and from the model itself. The language hook algorithm interleaves text generation by the base model with the execution of modular programs that trigger conditionally based on the existing text and the available capabilities. Upon triggering, programs may call external tools, auxiliary language models (e.g. using tool specific prompts), and modify the existing context. We benchmark our method against state-of-the-art baselines, find that it outperforms task-aware approaches, and demonstrate its ability to generalise to novel tasks.
FreeEval: A Modular Framework for Trustworthy and Efficient Evaluation of Large Language Models
The rapid development of large language model (LLM) evaluation methodologies and datasets has led to a profound challenge: integrating state-of-the-art evaluation techniques cost-effectively while ensuring reliability, reproducibility, and efficiency. Currently, there is a notable absence of a unified and adaptable framework that seamlessly integrates various evaluation approaches. Moreover, the reliability of evaluation findings is often questionable due to potential data contamination, with the evaluation efficiency commonly overlooked when facing the substantial costs associated with LLM inference. In response to these challenges, we introduce FreeEval, a modular and scalable framework crafted to enable trustworthy and efficient automatic evaluations of LLMs. Firstly, FreeEval's unified abstractions simplify the integration and improve the transparency of diverse evaluation methodologies, encompassing dynamic evaluation that demand sophisticated LLM interactions. Secondly, the framework integrates meta-evaluation techniques like human evaluation and data contamination detection, which, along with dynamic evaluation modules in the platform, enhance the fairness of the evaluation outcomes. Lastly, FreeEval is designed with a high-performance infrastructure, including distributed computation and caching strategies, enabling extensive evaluations across multi-node, multi-GPU clusters for open-source and proprietary LLMs.
AnalogVNN: A fully modular framework for modeling and optimizing photonic neural networks
AnalogVNN, a simulation framework built on PyTorch which can simulate the effects of optoelectronic noise, limited precision, and signal normalization present in photonic neural network accelerators. We use this framework to train and optimize linear and convolutional neural networks with up to 9 layers and ~1.7 million parameters, while gaining insights into how normalization, activation function, reduced precision, and noise influence accuracy in analog photonic neural networks. By following the same layer structure design present in PyTorch, the AnalogVNN framework allows users to convert most digital neural network models to their analog counterparts with just a few lines of code, taking full advantage of the open-source optimization, deep learning, and GPU acceleration libraries available through PyTorch. Code is available at https://analogvnn.github.io

RAGLAB: A Modular and Research-Oriented Unified Framework for Retrieval-Augmented Generation
Large Language Models (LLMs) demonstrate human-level capabilities in dialogue, reasoning, and knowledge retention. However, even the most advanced LLMs face challenges such as hallucinations and real-time updating of their knowledge. Current research addresses this bottleneck by equipping LLMs with external knowledge, a technique known as Retrieval Augmented Generation (RAG). However, two key issues constrained the development of RAG. First, there is a growing lack of comprehensive and fair comparisons between novel RAG algorithms. Second, open-source tools such as LlamaIndex and LangChain employ high-level abstractions, which results in a lack of transparency and limits the ability to develop novel algorithms and evaluation metrics. To close this gap, we introduce RAGLAB, a modular and research-oriented open-source library. RAGLAB reproduces 6 existing algorithms and provides a comprehensive ecosystem for investigating RAG algorithms. Leveraging RAGLAB, we conduct a fair comparison of 6 RAG algorithms across 10 benchmarks. With RAGLAB, researchers can efficiently compare the performance of various algorithms and develop novel algorithms.
Agent AI with LangGraph: A Modular Framework for Enhancing Machine Translation Using Large Language Models
This paper explores the transformative role of Agent AI and LangGraph in advancing the automation and effectiveness of machine translation (MT). Agents are modular components designed to perform specific tasks, such as translating between particular languages, with specializations like TranslateEnAgent, TranslateFrenchAgent, and TranslateJpAgent for English, French, and Japanese translations, respectively. These agents leverage the powerful semantic capabilities of large language models (LLMs), such as GPT-4o, to ensure accurate, contextually relevant translations while maintaining modularity, scalability, and context retention. LangGraph, a graph-based framework built on LangChain, simplifies the creation and management of these agents and their workflows. It supports dynamic state management, enabling agents to maintain dialogue context and automates complex workflows by linking agents and facilitating their collaboration. With flexibility, open-source community support, and seamless integration with LLMs, LangGraph empowers agents to deliver high-quality translations. Together, Agent AI and LangGraph create a cohesive system where LangGraph orchestrates agent interactions, ensuring that user inputs are analyzed, routed, and processed efficiently. Experimental results demonstrate the potential of this system to enhance multilingual translation accuracy and scalability. By highlighting modular design and automated workflows, this paper sets the stage for further innovations in intelligent machine translation services.
SGL: Symbolic Goal Learning in a Hybrid, Modular Framework for Human Instruction Following
This paper investigates robot manipulation based on human instruction with ambiguous requests. The intent is to compensate for imperfect natural language via visual observations. Early symbolic methods, based on manually defined symbols, built modular framework consist of semantic parsing and task planning for producing sequences of actions from natural language requests. Modern connectionist methods employ deep neural networks to automatically learn visual and linguistic features and map to a sequence of low-level actions, in an endto-end fashion. These two approaches are blended to create a hybrid, modular framework: it formulates instruction following as symbolic goal learning via deep neural networks followed by task planning via symbolic planners. Connectionist and symbolic modules are bridged with Planning Domain Definition Language. The vision-and-language learning network predicts its goal representation, which is sent to a planner for producing a task-completing action sequence. For improving the flexibility of natural language, we further incorporate implicit human intents with explicit human instructions. To learn generic features for vision and language, we propose to separately pretrain vision and language encoders on scene graph parsing and semantic textual similarity tasks. Benchmarking evaluates the impacts of different components of, or options for, the vision-and-language learning model and shows the effectiveness of pretraining strategies. Manipulation experiments conducted in the simulator AI2THOR show the robustness of the framework to novel scenarios.
Modular Techniques for Synthetic Long-Context Data Generation in Language Model Training and Evaluation
The ability of large language models (LLMs) to process and reason over long textual inputs is critical for a wide range of real-world applications. However, progress in this area is significantly constrained by the absence of high-quality, diverse, and verifiable long-context datasets suitable for both training and evaluation. This work introduces a modular, extensible framework for synthetic long-context data generation via prompt-based interaction with LLMs. The framework supports multiple training and alignment objectives, including Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Group Relative Policy Optimization (GRPO). It encompasses four core generation paradigms: multi-turn conversational dialogues, document-grounded input-output pairs, verifiable instruction-response tasks, and long-context reasoning examples. Through templated prompting, a model-agnostic architecture, and metadata-enriched outputs, the proposed approach facilitates scalable, controllable, and purpose-aligned dataset creation for advancing long-context capabilities in LLMs.


EasyJailbreak: A Unified Framework for Jailbreaking Large Language Models
Jailbreak attacks are crucial for identifying and mitigating the security vulnerabilities of Large Language Models (LLMs). They are designed to bypass safeguards and elicit prohibited outputs. However, due to significant differences among various jailbreak methods, there is no standard implementation framework available for the community, which limits comprehensive security evaluations. This paper introduces EasyJailbreak, a unified framework simplifying the construction and evaluation of jailbreak attacks against LLMs. It builds jailbreak attacks using four components: Selector, Mutator, Constraint, and Evaluator. This modular framework enables researchers to easily construct attacks from combinations of novel and existing components. So far, EasyJailbreak supports 11 distinct jailbreak methods and facilitates the security validation of a broad spectrum of LLMs. Our validation across 10 distinct LLMs reveals a significant vulnerability, with an average breach probability of 60% under various jailbreaking attacks. Notably, even advanced models like GPT-3.5-Turbo and GPT-4 exhibit average Attack Success Rates (ASR) of 57% and 33%, respectively. We have released a wealth of resources for researchers, including a web platform, PyPI published package, screencast video, and experimental outputs.



TopoBenchmarkX: A Framework for Benchmarking Topological Deep Learning
This work introduces TopoBenchmarkX, a modular open-source library designed to standardize benchmarking and accelerate research in Topological Deep Learning (TDL). TopoBenchmarkX maps the TDL pipeline into a sequence of independent and modular components for data loading and processing, as well as model training, optimization, and evaluation. This modular organization provides flexibility for modifications and facilitates the adaptation and optimization of various TDL pipelines. A key feature of TopoBenchmarkX is that it allows for the transformation and lifting between topological domains. This enables, for example, to obtain richer data representations and more fine-grained analyses by mapping the topology and features of a graph to higher-order topological domains such as simplicial and cell complexes. The range of applicability of TopoBenchmarkX is demonstrated by benchmarking several TDL architectures for various tasks and datasets.


Modular Pluralism: Pluralistic Alignment via Multi-LLM Collaboration
While existing alignment paradigms have been integral in developing large language models (LLMs), LLMs often learn an averaged human preference and struggle to model diverse preferences across cultures, demographics, and communities. We propose Modular Pluralism, a modular framework based on multi-LLM collaboration for pluralistic alignment: it "plugs into" a base LLM a pool of smaller but specialized community LMs, where models collaborate in distinct modes to flexibility support three modes of pluralism: Overton, steerable, and distributional. Modular Pluralism is uniquely compatible with black-box LLMs and offers the modular control of adding new community LMs for previously underrepresented communities. We evaluate Modular Pluralism with six tasks and four datasets featuring questions/instructions with value-laden and perspective-informed responses. Extensive experiments demonstrate that Modular Pluralism advances the three pluralism objectives across six black-box and open-source LLMs. Further analysis reveals that LLMs are generally faithful to the inputs from smaller community LLMs, allowing seamless patching by adding a new community LM to better cover previously underrepresented communities.
Archon: An Architecture Search Framework for Inference-Time Techniques
Inference-time techniques are emerging as highly effective tools to enhance large language model (LLM) capabilities. However, best practices for developing systems that combine these techniques remain underdeveloped due to our limited understanding of the utility of individual inference-time techniques and the interactions between them. Additionally, efficiently and automatically searching the space of model choices, inference-time techniques, and their compositions is challenging due to the large design space. To address these challenges, we introduce Archon, a modular framework for selecting, combining, and stacking layers of inference-time techniques to construct optimized LLM systems for target benchmarks. Rather than relying on a single LLM called once, we leverage a diverse set of LLMs and inference-time techniques, creating LLM systems greater than the sum of their parts. Archon defines an extensible design space, encompassing techniques such as generation ensembling, repeated sampling, ranking, fusion, critiquing, verification, and unit testing. It transforms the problem of building LLM systems into a hyperparameter optimization objective. Given the available LLMs, inference-time techniques, and compute budget, Archon utilizes hyperparameter search techniques to discover optimized architectures for target benchmark(s). We evaluate Archon architectures across a range of instruction-following, reasoning, and coding benchmarks, including MT-Bench, Arena-Hard-Auto, AlpacaEval 2.0, MixEval, MixEval Hard, MATH, and CodeContests. Archon architectures outperform frontier models, such as GPT-4o and Claude 3.5 Sonnet, on these benchmarks, achieving an average accuracy increase of 15.1 percentage points by using all available LLMs. We make our code and datasets available publicly on Github: https://github.com/ScalingIntelligence/Archon.


SymbolicAI: A framework for logic-based approaches combining generative models and solvers
We introduce SymbolicAI, a versatile and modular framework employing a logic-based approach to concept learning and flow management in generative processes. SymbolicAI enables the seamless integration of generative models with a diverse range of solvers by treating large language models (LLMs) as semantic parsers that execute tasks based on both natural and formal language instructions, thus bridging the gap between symbolic reasoning and generative AI. We leverage probabilistic programming principles to tackle complex tasks, and utilize differentiable and classical programming paradigms with their respective strengths. The framework introduces a set of polymorphic, compositional, and self-referential operations for data stream manipulation, aligning LLM outputs with user objectives. As a result, we can transition between the capabilities of various foundation models endowed with zero- and few-shot learning capabilities and specialized, fine-tuned models or solvers proficient in addressing specific problems. In turn, the framework facilitates the creation and evaluation of explainable computational graphs. We conclude by introducing a quality measure and its empirical score for evaluating these computational graphs, and propose a benchmark that compares various state-of-the-art LLMs across a set of complex workflows. We refer to the empirical score as the "Vector Embedding for Relational Trajectory Evaluation through Cross-similarity", or VERTEX score for short. The framework codebase and benchmark are linked below.


FIRESPARQL: A LLM-based Framework for SPARQL Query Generation over Scholarly Knowledge Graphs
Question answering over Scholarly Knowledge Graphs (SKGs) remains a challenging task due to the complexity of scholarly content and the intricate structure of these graphs. Large Language Model (LLM) approaches could be used to translate natural language questions (NLQs) into SPARQL queries; however, these LLM-based approaches struggle with SPARQL query generation due to limited exposure to SKG-specific content and the underlying schema. We identified two main types of errors in the LLM-generated SPARQL queries: (i) structural inconsistencies, such as missing or redundant triples in the queries, and (ii) semantic inaccuracies, where incorrect entities or properties are shown in the queries despite a correct query structure. To address these issues, we propose FIRESPARQL, a modular framework that supports fine-tuned LLMs as a core component, with optional context provided via retrieval-augmented generation (RAG) and a SPARQL query correction layer. We evaluate the framework on the SciQA Benchmark using various configurations (zero-shot, zero-shot with RAG, one-shot, fine-tuning, and fine-tuning with RAG) and compare the performance with baseline and state-of-the-art approaches. We measure query accuracy using BLEU and ROUGE metrics, and query result accuracy using relaxed exact match(RelaxedEM), with respect to the gold standards containing the NLQs, SPARQL queries, and the results of the queries. Experimental results demonstrate that fine-tuning achieves the highest overall performance, reaching 0.90 ROUGE-L for query accuracy and 0.85 RelaxedEM for result accuracy on the test set.
PreGenie: An Agentic Framework for High-quality Visual Presentation Generation
Visual presentations are vital for effective communication. Early attempts to automate their creation using deep learning often faced issues such as poorly organized layouts, inaccurate text summarization, and a lack of image understanding, leading to mismatched visuals and text. These limitations restrict their application in formal contexts like business and scientific research. To address these challenges, we propose PreGenie, an agentic and modular framework powered by multimodal large language models (MLLMs) for generating high-quality visual presentations. PreGenie is built on the Slidev presentation framework, where slides are rendered from Markdown code. It operates in two stages: (1) Analysis and Initial Generation, which summarizes multimodal input and generates initial code, and (2) Review and Re-generation, which iteratively reviews intermediate code and rendered slides to produce final, high-quality presentations. Each stage leverages multiple MLLMs that collaborate and share information. Comprehensive experiments demonstrate that PreGenie excels in multimodal understanding, outperforming existing models in both aesthetics and content consistency, while aligning more closely with human design preferences.
POSTA: A Go-to Framework for Customized Artistic Poster Generation
Poster design is a critical medium for visual communication. Prior work has explored automatic poster design using deep learning techniques, but these approaches lack text accuracy, user customization, and aesthetic appeal, limiting their applicability in artistic domains such as movies and exhibitions, where both clear content delivery and visual impact are essential. To address these limitations, we present POSTA: a modular framework powered by diffusion models and multimodal large language models (MLLMs) for customized artistic poster generation. The framework consists of three modules. Background Diffusion creates a themed background based on user input. Design MLLM then generates layout and typography elements that align with and complement the background style. Finally, to enhance the poster's aesthetic appeal, ArtText Diffusion applies additional stylization to key text elements. The final result is a visually cohesive and appealing poster, with a fully modular process that allows for complete customization. To train our models, we develop the PosterArt dataset, comprising high-quality artistic posters annotated with layout, typography, and pixel-level stylized text segmentation. Our comprehensive experimental analysis demonstrates POSTA's exceptional controllability and design diversity, outperforming existing models in both text accuracy and aesthetic quality.

Infogent: An Agent-Based Framework for Web Information Aggregation
Despite seemingly performant web agents on the task-completion benchmarks, most existing methods evaluate the agents based on a presupposition: the web navigation task consists of linear sequence of actions with an end state that marks task completion. In contrast, our work focuses on web navigation for information aggregation, wherein the agent must explore different websites to gather information for a complex query. We consider web information aggregation from two different perspectives: (i) Direct API-driven Access relies on a text-only view of the Web, leveraging external tools such as Google Search API to navigate the web and a scraper to extract website contents. (ii) Interactive Visual Access uses screenshots of the webpages and requires interaction with the browser to navigate and access information. Motivated by these diverse information access settings, we introduce Infogent, a novel modular framework for web information aggregation involving three distinct components: Navigator, Extractor and Aggregator. Experiments on different information access settings demonstrate Infogent beats an existing SOTA multi-agent search framework by 7% under Direct API-Driven Access on FRAMES, and improves over an existing information-seeking web agent by 4.3% under Interactive Visual Access on AssistantBench.

Modular Embedding Recomposition for Incremental Learning
The advent of pre-trained Vision-Language Models (VLMs) has significantly transformed Continual Learning (CL), mainly due to their zero-shot classification abilities. Such proficiency makes VLMs well-suited for real-world applications, enabling robust performance on novel unseen classes without requiring adaptation. However, fine-tuning remains essential when downstream tasks deviate significantly from the pre-training domain. Prior CL approaches primarily focus on preserving the zero-shot capabilities of VLMs during incremental fine-tuning on a downstream task. We take a step further by devising an approach that transforms preservation into enhancement of the zero-shot capabilities of VLMs. Our approach, named MoDular Embedding Recomposition (MoDER), introduces a modular framework that trains multiple textual experts, each specialized in a single seen class, and stores them in a foundational hub. At inference time, for each unseen class, we query the hub and compose the retrieved experts to synthesize a refined prototype that improves classification. We show the effectiveness of our method across two popular zero-shot incremental protocols, Class-IL and MTIL, comprising a total of 14 datasets. The codebase is available at https://github.com/aimagelab/mammoth.

FlashRAG: A Modular Toolkit for Efficient Retrieval-Augmented Generation Research
With the advent of Large Language Models (LLMs), the potential of Retrieval Augmented Generation (RAG) techniques have garnered considerable research attention. Numerous novel algorithms and models have been introduced to enhance various aspects of RAG systems. However, the absence of a standardized framework for implementation, coupled with the inherently intricate RAG process, makes it challenging and time-consuming for researchers to compare and evaluate these approaches in a consistent environment. Existing RAG toolkits like LangChain and LlamaIndex, while available, are often heavy and unwieldy, failing to meet the personalized needs of researchers. In response to this challenge, we propose FlashRAG, an efficient and modular open-source toolkit designed to assist researchers in reproducing existing RAG methods and in developing their own RAG algorithms within a unified framework. Our toolkit implements 12 advanced RAG methods and has gathered and organized 32 benchmark datasets. Our toolkit has various features, including customizable modular framework, rich collection of pre-implemented RAG works, comprehensive datasets, efficient auxiliary pre-processing scripts, and extensive and standard evaluation metrics. Our toolkit and resources are available at https://github.com/RUC-NLPIR/FlashRAG.



From Words to Structured Visuals: A Benchmark and Framework for Text-to-Diagram Generation and Editing
We introduce the task of text-to-diagram generation, which focuses on creating structured visual representations directly from textual descriptions. Existing approaches in text-to-image and text-to-code generation lack the logical organization and flexibility needed to produce accurate, editable diagrams, often resulting in outputs that are either unstructured or difficult to modify. To address this gap, we introduce DiagramGenBenchmark, a comprehensive evaluation framework encompassing eight distinct diagram categories, including flowcharts, model architecture diagrams, and mind maps. Additionally, we present DiagramAgent, an innovative framework with four core modules-Plan Agent, Code Agent, Check Agent, and Diagram-to-Code Agent-designed to facilitate both the generation and refinement of complex diagrams. Our extensive experiments, which combine objective metrics with human evaluations, demonstrate that DiagramAgent significantly outperforms existing baseline models in terms of accuracy, structural coherence, and modifiability. This work not only establishes a foundational benchmark for the text-to-diagram generation task but also introduces a powerful toolset to advance research and applications in this emerging area.



Domain-Specific Data Generation Framework for RAG Adaptation
Retrieval-Augmented Generation (RAG) combines the language understanding and reasoning power of large language models (LLMs) with external retrieval to enable domain-grounded responses. Effectively adapting RAG systems to domain-specific settings requires specialized, context-rich training data beyond general-purpose question-answering. Here, we propose RAGen, a scalable and modular framework for generating domain-grounded question-answer-context (QAC) triples tailored to diverse RAG adaptation approaches. RAGen produces these QAC triples by identifying key concepts in documents, generating diverse questions guided by Bloom's Taxonomy-inspired principles, and pairing them with precise answers extracted from relevant contexts. RAGen supports multiple RAG adaptation strategies, including the optimization of key components such as the LLM, retriever, and embedding model, etc. Its modular pipeline features semantic chunking, hierarchical concept extraction, and multi-chunk retrieval, along with the introduction of curated distractor contexts to promote robust reasoning. Designed for scalability, RAGen efficiently handles large and evolving document corpora without redundant processing, making it especially suitable for dynamic evolving domains such as scientific research and enterprise knowledge bases.
$\text{M}^{\text{3}}$: A Modular World Model over Streams of Tokens
Token-based world models emerged as a promising modular framework, modeling dynamics over token streams while optimizing tokenization separately. While successful in visual environments with discrete actions (e.g., Atari games), their broader applicability remains uncertain. In this paper, we introduce M^{3}, a modular world model that extends this framework, enabling flexible combinations of observation and action modalities through independent modality-specific components. M^{3} integrates several improvements from existing literature to enhance agent performance. Through extensive empirical evaluation across diverse benchmarks, M^{3} achieves state-of-the-art sample efficiency for planning-free world models. Notably, among these methods, it is the first to reach a human-level median score on Atari 100K, with superhuman performance on 13 games. We https://github.com/leor-c/M3{open-source our code and weights}.
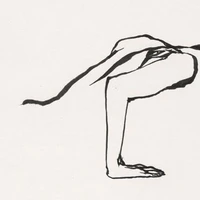
VoiceShop: A Unified Speech-to-Speech Framework for Identity-Preserving Zero-Shot Voice Editing
We present VoiceShop, a novel speech-to-speech framework that can modify multiple attributes of speech, such as age, gender, accent, and speech style, in a single forward pass while preserving the input speaker's timbre. Previous works have been constrained to specialized models that can only edit these attributes individually and suffer from the following pitfalls: the magnitude of the conversion effect is weak, there is no zero-shot capability for out-of-distribution speakers, or the synthesized outputs exhibit undesirable timbre leakage. Our work proposes solutions for each of these issues in a simple modular framework based on a conditional diffusion backbone model with optional normalizing flow-based and sequence-to-sequence speaker attribute-editing modules, whose components can be combined or removed during inference to meet a wide array of tasks without additional model finetuning. Audio samples are available at https://voiceshopai.github.io.

Multi-Head Explainer: A General Framework to Improve Explainability in CNNs and Transformers
In this study, we introduce the Multi-Head Explainer (MHEX), a versatile and modular framework that enhances both the explainability and accuracy of Convolutional Neural Networks (CNNs) and Transformer-based models. MHEX consists of three core components: an Attention Gate that dynamically highlights task-relevant features, Deep Supervision that guides early layers to capture fine-grained details pertinent to the target class, and an Equivalent Matrix that unifies refined local and global representations to generate comprehensive saliency maps. Our approach demonstrates superior compatibility, enabling effortless integration into existing residual networks like ResNet and Transformer architectures such as BERT with minimal modifications. Extensive experiments on benchmark datasets in medical imaging and text classification show that MHEX not only improves classification accuracy but also produces highly interpretable and detailed saliency scores.
Yet Another ICU Benchmark: A Flexible Multi-Center Framework for Clinical ML
Medical applications of machine learning (ML) have experienced a surge in popularity in recent years. The intensive care unit (ICU) is a natural habitat for ML given the abundance of available data from electronic health records. Models have been proposed to address numerous ICU prediction tasks like the early detection of complications. While authors frequently report state-of-the-art performance, it is challenging to verify claims of superiority. Datasets and code are not always published, and cohort definitions, preprocessing pipelines, and training setups are difficult to reproduce. This work introduces Yet Another ICU Benchmark (YAIB), a modular framework that allows researchers to define reproducible and comparable clinical ML experiments; we offer an end-to-end solution from cohort definition to model evaluation. The framework natively supports most open-access ICU datasets (MIMIC III/IV, eICU, HiRID, AUMCdb) and is easily adaptable to future ICU datasets. Combined with a transparent preprocessing pipeline and extensible training code for multiple ML and deep learning models, YAIB enables unified model development. Our benchmark comes with five predefined established prediction tasks (mortality, acute kidney injury, sepsis, kidney function, and length of stay) developed in collaboration with clinicians. Adding further tasks is straightforward by design. Using YAIB, we demonstrate that the choice of dataset, cohort definition, and preprocessing have a major impact on the prediction performance - often more so than model class - indicating an urgent need for YAIB as a holistic benchmarking tool. We provide our work to the clinical ML community to accelerate method development and enable real-world clinical implementations. Software Repository: https://github.com/rvandewater/YAIB.

SocialGPT: Prompting LLMs for Social Relation Reasoning via Greedy Segment Optimization
Social relation reasoning aims to identify relation categories such as friends, spouses, and colleagues from images. While current methods adopt the paradigm of training a dedicated network end-to-end using labeled image data, they are limited in terms of generalizability and interpretability. To address these issues, we first present a simple yet well-crafted framework named {\name}, which combines the perception capability of Vision Foundation Models (VFMs) and the reasoning capability of Large Language Models (LLMs) within a modular framework, providing a strong baseline for social relation recognition. Specifically, we instruct VFMs to translate image content into a textual social story, and then utilize LLMs for text-based reasoning. {\name} introduces systematic design principles to adapt VFMs and LLMs separately and bridge their gaps. Without additional model training, it achieves competitive zero-shot results on two databases while offering interpretable answers, as LLMs can generate language-based explanations for the decisions. The manual prompt design process for LLMs at the reasoning phase is tedious and an automated prompt optimization method is desired. As we essentially convert a visual classification task into a generative task of LLMs, automatic prompt optimization encounters a unique long prompt optimization issue. To address this issue, we further propose the Greedy Segment Prompt Optimization (GSPO), which performs a greedy search by utilizing gradient information at the segment level. Experimental results show that GSPO significantly improves performance, and our method also generalizes to different image styles. The code is available at https://github.com/Mengzibin/SocialGPT.


NAVSIM: Data-Driven Non-Reactive Autonomous Vehicle Simulation and Benchmarking
Benchmarking vision-based driving policies is challenging. On one hand, open-loop evaluation with real data is easy, but these results do not reflect closed-loop performance. On the other, closed-loop evaluation is possible in simulation, but is hard to scale due to its significant computational demands. Further, the simulators available today exhibit a large domain gap to real data. This has resulted in an inability to draw clear conclusions from the rapidly growing body of research on end-to-end autonomous driving. In this paper, we present NAVSIM, a middle ground between these evaluation paradigms, where we use large datasets in combination with a non-reactive simulator to enable large-scale real-world benchmarking. Specifically, we gather simulation-based metrics, such as progress and time to collision, by unrolling bird's eye view abstractions of the test scenes for a short simulation horizon. Our simulation is non-reactive, i.e., the evaluated policy and environment do not influence each other. As we demonstrate empirically, this decoupling allows open-loop metric computation while being better aligned with closed-loop evaluations than traditional displacement errors. NAVSIM enabled a new competition held at CVPR 2024, where 143 teams submitted 463 entries, resulting in several new insights. On a large set of challenging scenarios, we observe that simple methods with moderate compute requirements such as TransFuser can match recent large-scale end-to-end driving architectures such as UniAD. Our modular framework can potentially be extended with new datasets, data curation strategies, and metrics, and will be continually maintained to host future challenges. Our code is available at https://github.com/autonomousvision/navsim.





GenKnowSub: Improving Modularity and Reusability of LLMs through General Knowledge Subtraction
Large language models often struggle with zero-shot generalization, and several modular approaches have been proposed to address this challenge. Yet, we hypothesize that a key limitation remains: the entanglement of general knowledge and task-specific adaptations. To overcome this, we propose a modular framework that disentangles these components by constructing a library of task-specific LoRA modules alongside a general-domain LoRA. By subtracting this general knowledge component from each task-specific module, we obtain residual modules that focus more exclusively on task-relevant information, a method we call general knowledge subtraction (GenKnowSub). Leveraging the refined task-specific modules and the Arrow routing algorithm ostapenko2024towards, we dynamically select and combine modules for new inputs without additional training. Our studies on the Phi-3 model and standard Arrow as baselines reveal that using general knowledge LoRAs derived from diverse languages, including English, French, and German, yields consistent performance gains in both monolingual and cross-lingual settings across a wide set of benchmarks. Further experiments on Phi-2 demonstrate how GenKnowSub generalizes to weaker LLMs. The complete code and data are available at https://github.com/saharsamr/Modular-LLM.


Small LLMs Are Weak Tool Learners: A Multi-LLM Agent
Large Language Model (LLM) agents significantly extend the capabilities of standalone LLMs, empowering them to interact with external tools (e.g., APIs, functions) and complete complex tasks in a self-directed fashion. The challenge of tool use demands that LLMs not only understand user queries and generate answers but also excel in task planning, memory management, tool invocation, and result summarization. While traditional approaches focus on training a single LLM with all these capabilities, performance limitations become apparent, particularly with smaller models. Moreover, the entire LLM may require retraining when tools are updated. To overcome these challenges, we propose a novel strategy that decomposes the aforementioned capabilities into a planner, caller, and summarizer. Each component is implemented by a single LLM that focuses on a specific capability and collaborates with other components to accomplish the task. This modular framework facilitates individual updates and the potential use of smaller LLMs for building each capability. To effectively train this framework, we introduce a two-stage training paradigm. First, we fine-tune a backbone LLM on the entire dataset without discriminating sub-tasks, providing the model with a comprehensive understanding of the task. Second, the fine-tuned LLM is used to instantiate the planner, caller, and summarizer respectively, which are continually fine-tuned on respective sub-tasks. Evaluation across various tool-use benchmarks illustrates that our proposed multi-LLM framework surpasses the traditional single-LLM approach, highlighting its efficacy and advantages in tool learning.

Hierarchical Spatial Algorithms for High-Resolution Image Quantization and Feature Extraction
This study introduces a modular framework for spatial image processing, integrating grayscale quantization, color and brightness enhancement, image sharpening, bidirectional transformation pipelines, and geometric feature extraction. A stepwise intensity transformation quantizes grayscale images into eight discrete levels, producing a posterization effect that simplifies representation while preserving structural detail. Color enhancement is achieved via histogram equalization in both RGB and YCrCb color spaces, with the latter improving contrast while maintaining chrominance fidelity. Brightness adjustment is implemented through HSV value-channel manipulation, and image sharpening is performed using a 3 * 3 convolution kernel to enhance high-frequency details. A bidirectional transformation pipeline that integrates unsharp masking, gamma correction, and noise amplification achieved accuracy levels of 76.10% and 74.80% for the forward and reverse processes, respectively. Geometric feature extraction employed Canny edge detection, Hough-based line estimation (e.g., 51.50{\deg} for billiard cue alignment), Harris corner detection, and morphological window localization. Cue isolation further yielded 81.87\% similarity against ground truth images. Experimental evaluation across diverse datasets demonstrates robust and deterministic performance, highlighting its potential for real-time image analysis and computer vision.

Agent WARPP: Workflow Adherence via Runtime Parallel Personalization
Large language models (LLMs) are increasingly applied in task-oriented dialogue (TOD) systems but often struggle with long, conditional workflows that involve external tool calls and depend on user-specific information. We present Workflow Adherence via Runtime Parallel Personalization, or WARPP, a training-free, modular framework that combines multi-agent orchestration with runtime personalization to improve workflow adherence in LLM-based systems. By dynamically pruning conditional branches based on user attributes, the framework reduces reasoning overhead and narrows tool selection at runtime. WARPP deploys a parallelized architecture where a dedicated Personalizer agent operates alongside modular, domain-specific agents to dynamically tailor execution paths in real time. The framework is evaluated across five representative user intents of varying complexity within three domains: banking, flights, and healthcare. Our evaluation leverages synthetic datasets and LLM-powered simulated users to test scenarios with conditional dependencies. Our results demonstrate that WARPP outperforms both the non-personalized method and the ReAct baseline, achieving increasingly larger gains in parameter fidelity and tool accuracy as intent complexity grows, while also reducing average token usage, without any additional training.
SUCEA: Reasoning-Intensive Retrieval for Adversarial Fact-checking through Claim Decomposition and Editing
Automatic fact-checking has recently received more attention as a means of combating misinformation. Despite significant advancements, fact-checking systems based on retrieval-augmented language models still struggle to tackle adversarial claims, which are intentionally designed by humans to challenge fact-checking systems. To address these challenges, we propose a training-free method designed to rephrase the original claim, making it easier to locate supporting evidence. Our modular framework, SUCEA, decomposes the task into three steps: 1) Claim Segmentation and Decontextualization that segments adversarial claims into independent sub-claims; 2) Iterative Evidence Retrieval and Claim Editing that iteratively retrieves evidence and edits the subclaim based on the retrieved evidence; 3) Evidence Aggregation and Label Prediction that aggregates all retrieved evidence and predicts the entailment label. Experiments on two challenging fact-checking datasets demonstrate that our framework significantly improves on both retrieval and entailment label accuracy, outperforming four strong claim-decomposition-based baselines.

Controlling Large Language Model-based Agents for Large-Scale Decision-Making: An Actor-Critic Approach
The remarkable progress in Large Language Models (LLMs) opens up new avenues for addressing planning and decision-making problems in Multi-Agent Systems (MAS). However, as the number of agents increases, the issues of hallucination in LLMs and coordination in MAS have become increasingly prominent. Additionally, the efficient utilization of tokens emerges as a critical consideration when employing LLMs to facilitate the interactions among a substantial number of agents. In this paper, we develop a modular framework called LLaMAC to mitigate these challenges. LLaMAC implements a value distribution encoding similar to that found in the human brain, utilizing internal and external feedback mechanisms to facilitate collaboration and iterative reasoning among its modules. Through evaluations involving system resource allocation and robot grid transportation, we demonstrate the considerable advantages afforded by our proposed approach.

LIBMoE: A Library for comprehensive benchmarking Mixture of Experts in Large Language Models
Mixture of Experts (MoEs) plays an important role in the development of more efficient and effective large language models (LLMs). Due to the enormous resource requirements, studying large scale MoE algorithms remain in-accessible to many researchers. This work develops LibMoE, a comprehensive and modular framework to streamline the research, training, and evaluation of MoE algorithms. Built upon three core principles: (i) modular design, (ii) efficient training; (iii) comprehensive evaluation, LibMoE brings MoE in LLMs more accessible to a wide range of researchers by standardizing the training and evaluation pipelines. Using LibMoE, we extensively benchmarked five state-of-the-art MoE algorithms over three different LLMs and 11 datasets under the zero-shot setting. The results show that despite the unique characteristics, all MoE algorithms perform roughly similar when averaged across a wide range of tasks. With the modular design and extensive evaluation, we believe LibMoE will be invaluable for researchers to make meaningful progress towards the next generation of MoE and LLMs. Project page: https://fsoft-aic.github.io/fsoft-LibMoE.github.io.


Recipe for a General, Powerful, Scalable Graph Transformer
We propose a recipe on how to build a general, powerful, scalable (GPS) graph Transformer with linear complexity and state-of-the-art results on a diverse set of benchmarks. Graph Transformers (GTs) have gained popularity in the field of graph representation learning with a variety of recent publications but they lack a common foundation about what constitutes a good positional or structural encoding, and what differentiates them. In this paper, we summarize the different types of encodings with a clearer definition and categorize them as being local, global or relative. The prior GTs are constrained to small graphs with a few hundred nodes, here we propose the first architecture with a complexity linear in the number of nodes and edges O(N+E) by decoupling the local real-edge aggregation from the fully-connected Transformer. We argue that this decoupling does not negatively affect the expressivity, with our architecture being a universal function approximator on graphs. Our GPS recipe consists of choosing 3 main ingredients: (i) positional/structural encoding, (ii) local message-passing mechanism, and (iii) global attention mechanism. We provide a modular framework GraphGPS that supports multiple types of encodings and that provides efficiency and scalability both in small and large graphs. We test our architecture on 16 benchmarks and show highly competitive results in all of them, show-casing the empirical benefits gained by the modularity and the combination of different strategies.

OpenNRE: An Open and Extensible Toolkit for Neural Relation Extraction
OpenNRE is an open-source and extensible toolkit that provides a unified framework to implement neural models for relation extraction (RE). Specifically, by implementing typical RE methods, OpenNRE not only allows developers to train custom models to extract structured relational facts from the plain text but also supports quick model validation for researchers. Besides, OpenNRE provides various functional RE modules based on both TensorFlow and PyTorch to maintain sufficient modularity and extensibility, making it becomes easy to incorporate new models into the framework. Besides the toolkit, we also release an online system to meet real-time extraction without any training and deploying. Meanwhile, the online system can extract facts in various scenarios as well as aligning the extracted facts to Wikidata, which may benefit various downstream knowledge-driven applications (e.g., information retrieval and question answering). More details of the toolkit and online system can be obtained from http://github.com/thunlp/OpenNRE.

LEGO-GraphRAG: Modularizing Graph-based Retrieval-Augmented Generation for Design Space Exploration
GraphRAG addresses significant challenges in Retrieval-Augmented Generation (RAG) by leveraging graphs with embedded knowledge to enhance the reasoning capabilities of Large Language Models (LLMs). Despite its promising potential, the GraphRAG community currently lacks a unified framework for fine-grained decomposition of the graph-based knowledge retrieval process. Furthermore, there is no systematic categorization or evaluation of existing solutions within the retrieval process. In this paper, we present LEGO-GraphRAG, a modular framework that decomposes the retrieval process of GraphRAG into three interconnected modules: subgraph-extraction, path-filtering, and path-refinement. We systematically summarize and classify the algorithms and neural network (NN) models relevant to each module, providing a clearer understanding of the design space for GraphRAG instances. Additionally, we identify key design factors, such as Graph Coupling and Computational Cost, that influence the effectiveness of GraphRAG implementations. Through extensive empirical studies, we construct high-quality GraphRAG instances using a representative selection of solutions and analyze their impact on retrieval and reasoning performance. Our findings offer critical insights into optimizing GraphRAG instance design, ultimately contributing to the advancement of more accurate and contextually relevant LLM applications.

Spacerini: Plug-and-play Search Engines with Pyserini and Hugging Face
We present Spacerini, a modular framework for seamless building and deployment of interactive search applications, designed to facilitate the qualitative analysis of large scale research datasets. Spacerini integrates features from both the Pyserini toolkit and the Hugging Face ecosystem to ease the indexing text collections and deploy them as search engines for ad-hoc exploration and to make the retrieval of relevant data points quick and efficient. The user-friendly interface enables searching through massive datasets in a no-code fashion, making Spacerini broadly accessible to anyone looking to qualitatively audit their text collections. This is useful both to IR~researchers aiming to demonstrate the capabilities of their indexes in a simple and interactive way, and to NLP~researchers looking to better understand and audit the failure modes of large language models. The framework is open source and available on GitHub: https://github.com/castorini/hf-spacerini, and includes utilities to load, pre-process, index, and deploy local and web search applications. A portfolio of applications created with Spacerini for a multitude of use cases can be found by visiting https://hf.co/spacerini.




Terrarium: Revisiting the Blackboard for Multi-Agent Safety, Privacy, and Security Studies
A multi-agent system (MAS) powered by large language models (LLMs) can automate tedious user tasks such as meeting scheduling that requires inter-agent collaboration. LLMs enable nuanced protocols that account for unstructured private data, user constraints, and preferences. However, this design introduces new risks, including misalignment and attacks by malicious parties that compromise agents or steal user data. In this paper, we propose the Terrarium framework for fine-grained study on safety, privacy, and security in LLM-based MAS. We repurpose the blackboard design, an early approach in multi-agent systems, to create a modular, configurable testbed for multi-agent collaboration. We identify key attack vectors such as misalignment, malicious agents, compromised communication, and data poisoning. We implement three collaborative MAS scenarios with four representative attacks to demonstrate the framework's flexibility. By providing tools to rapidly prototype, evaluate, and iterate on defenses and designs, Terrarium aims to accelerate progress toward trustworthy multi-agent systems.
PromptFlow: Training Prompts Like Neural Networks
Large Language Models (LLMs) have demonstrated profound impact on Natural Language Processing (NLP) tasks. However, their effective deployment across diverse domains often require domain-specific adaptation strategies, as generic models may underperform when faced with specialized data distributions. Recent advances in prompt engineering (PE) offer a promising alternative to extensive retraining by refining input instructions to align LLM outputs with task objectives. This paradigm has emerged as a rapid and versatile approach for model fine-tuning. Despite its potential, manual prompt design remains labor-intensive and heavily depends on specialized expertise, often requiring iterative human effort to achieve optimal formulations. To address this limitation, automated prompt engineering methodologies have been developed to systematically generate task-specific prompts. However, current implementations predominantly employ static update rules and lack mechanisms for dynamic strategy selection, resulting in suboptimal adaptation to varying NLP task requirements. Furthermore, most methods treat and update the whole prompts at each step, without considering editing prompt sections at a finer granularity. At last, in particular, the problem of how to recycle experience in LLM is still underexplored. To this end, we propose the PromptFlow, a modular training framework inspired by TensorFlow, which integrates meta-prompts, operators, optimization, and evaluator. Our framework can be equipped with the latest optimization methods and autonomously explores optimal prompt refinement trajectories through gradient-based meta-learning, requiring minimal task-specific training data. Specifically, we devise a reinforcement learning method to recycle experience for LLM in the PE process. Finally, we conduct extensive experiments on various datasets, and demonstrate the effectiveness of PromptFlow.
NEXUS: Network Exploration for eXploiting Unsafe Sequences in Multi-Turn LLM Jailbreaks
Large Language Models (LLMs) have revolutionized natural language processing but remain vulnerable to jailbreak attacks, especially multi-turn jailbreaks that distribute malicious intent across benign exchanges and bypass alignment mechanisms. Existing approaches often explore the adversarial space poorly, rely on hand-crafted heuristics, or lack systematic query refinement. We present NEXUS (Network Exploration for eXploiting Unsafe Sequences), a modular framework for constructing, refining, and executing optimized multi-turn attacks. NEXUS comprises: (1) ThoughtNet, which hierarchically expands a harmful intent into a structured semantic network of topics, entities, and query chains; (2) a feedback-driven Simulator that iteratively refines and prunes these chains through attacker-victim-judge LLM collaboration using harmfulness and semantic-similarity benchmarks; and (3) a Network Traverser that adaptively navigates the refined query space for real-time attacks. This pipeline uncovers stealthy, high-success adversarial paths across LLMs. On several closed-source and open-source LLMs, NEXUS increases attack success rate by 2.1% to 19.4% over prior methods. Code: https://github.com/inspire-lab/NEXUS
GraphDART: Graph Distillation for Efficient Advanced Persistent Threat Detection
Cyber-physical-social systems (CPSSs) have emerged in many applications over recent decades, requiring increased attention to security concerns. The rise of sophisticated threats like Advanced Persistent Threats (APTs) makes ensuring security in CPSSs particularly challenging. Provenance graph analysis has proven effective for tracing and detecting anomalies within systems, but the sheer size and complexity of these graphs hinder the efficiency of existing methods, especially those relying on graph neural networks (GNNs). To address these challenges, we present GraphDART, a modular framework designed to distill provenance graphs into compact yet informative representations, enabling scalable and effective anomaly detection. GraphDART can take advantage of diverse graph distillation techniques, including classic and modern graph distillation methods, to condense large provenance graphs while preserving essential structural and contextual information. This approach significantly reduces computational overhead, allowing GNNs to learn from distilled graphs efficiently and enhance detection performance. Extensive evaluations on benchmark datasets demonstrate the robustness of GraphDART in detecting malicious activities across cyber-physical-social systems. By optimizing computational efficiency, GraphDART provides a scalable and practical solution to safeguard interconnected environments against APTs.
DeFine: Decision-Making with Analogical Reasoning over Factor Profiles
LLMs are ideal for decision-making thanks to their ability to reason over long contexts. However, challenges arise when processing speech transcripts that describe complex scenarios, as they are verbose and include repetition, hedging, and vagueness. E.g., during a company's earnings call, an executive might project a positive revenue outlook to reassure investors, despite uncertainty regarding future earnings. It is crucial for LLMs to incorporate this uncertainty systematically when making decisions. In this paper, we introduce DeFine, a modular framework that constructs probabilistic factor profiles from complex scenarios. It then integrates these profiles with analogical reasoning, leveraging insights from similar past experiences to guide LLMs in making critical decisions in new situations. Our framework separates the tasks of quantifying uncertainty and incorporating it into LLM decision-making. This approach is particularly useful in areas such as consulting and financial deliberation, where making decisions under uncertainty is vital.

BIRCO: A Benchmark of Information Retrieval Tasks with Complex Objectives
We present the Benchmark of Information Retrieval (IR) tasks with Complex Objectives (BIRCO). BIRCO evaluates the ability of IR systems to retrieve documents given multi-faceted user objectives. The benchmark's complexity and compact size make it suitable for evaluating large language model (LLM)-based information retrieval systems. We present a modular framework for investigating factors that may influence LLM performance on retrieval tasks, and identify a simple baseline model which matches or outperforms existing approaches and more complex alternatives. No approach achieves satisfactory performance on all benchmark tasks, suggesting that stronger models and new retrieval protocols are necessary to address complex user needs.
VerlTool: Towards Holistic Agentic Reinforcement Learning with Tool Use
Reinforcement Learning with Verifiable Rewards (RLVR) has demonstrated success in enhancing LLM reasoning capabilities, but remains limited to single-turn interactions without tool integration. While recent Agentic Reinforcement Learning with Tool use (ARLT) approaches have emerged to address multi-turn tool interactions, existing works develop task-specific codebases that suffer from fragmentation, synchronous execution bottlenecks, and limited extensibility across domains. These inefficiencies hinder broader community adoption and algorithmic innovation. We introduce VerlTool, a unified and modular framework that addresses these limitations through systematic design principles. VerlTool provides four key contributions: (1) upstream alignment with VeRL ensuring compatibility and simplified maintenance, (2) unified tool management via standardized APIs supporting diverse modalities including code execution, search, SQL databases, and vision processing, (3) asynchronous rollout execution achieving near 2times speedup by eliminating synchronization bottlenecks, and (4) comprehensive evaluation demonstrating competitive performance across 6 ARLT domains. Our framework formalizes ARLT as multi-turn trajectories with multi-modal observation tokens (text/image/video), extending beyond single-turn RLVR paradigms. We train and evaluate models on mathematical reasoning, knowledge QA, SQL generation, visual reasoning, web search, and software engineering tasks, achieving results comparable to specialized systems while providing unified training infrastructure. The modular plugin architecture enables rapid tool integration requiring only lightweight Python definitions, significantly reducing development overhead and providing a scalable foundation for tool-augmented RL research. Our code is open-sourced at https://github.com/TIGER-AI-Lab/verl-tool.

Adaptive Confidence Smoothing for Generalized Zero-Shot Learning
Generalized zero-shot learning (GZSL) is the problem of learning a classifier where some classes have samples and others are learned from side information, like semantic attributes or text description, in a zero-shot learning fashion (ZSL). Training a single model that operates in these two regimes simultaneously is challenging. Here we describe a probabilistic approach that breaks the model into three modular components, and then combines them in a consistent way. Specifically, our model consists of three classifiers: A "gating" model that makes soft decisions if a sample is from a "seen" class, and two experts: a ZSL expert, and an expert model for seen classes. We address two main difficulties in this approach: How to provide an accurate estimate of the gating probability without any training samples for unseen classes; and how to use expert predictions when it observes samples outside of its domain. The key insight to our approach is to pass information between the three models to improve each one's accuracy, while maintaining the modular structure. We test our approach, adaptive confidence smoothing (COSMO), on four standard GZSL benchmark datasets and find that it largely outperforms state-of-the-art GZSL models. COSMO is also the first model that closes the gap and surpasses the performance of generative models for GZSL, even-though it is a light-weight model that is much easier to train and tune. Notably, COSMO offers a new view for developing zero-shot models. Thanks to COSMO's modular structure, instead of trying to perform well both on seen and on unseen classes, models can focus on accurate classification of unseen classes, and later consider seen class models.
To Adapt or Not to Adapt? Real-Time Adaptation for Semantic Segmentation
The goal of Online Domain Adaptation for semantic segmentation is to handle unforeseeable domain changes that occur during deployment, like sudden weather events. However, the high computational costs associated with brute-force adaptation make this paradigm unfeasible for real-world applications. In this paper we propose HAMLET, a Hardware-Aware Modular Least Expensive Training framework for real-time domain adaptation. Our approach includes a hardware-aware back-propagation orchestration agent (HAMT) and a dedicated domain-shift detector that enables active control over when and how the model is adapted (LT). Thanks to these advancements, our approach is capable of performing semantic segmentation while simultaneously adapting at more than 29FPS on a single consumer-grade GPU. Our framework's encouraging accuracy and speed trade-off is demonstrated on OnDA and SHIFT benchmarks through experimental results.





SeeingEye: Agentic Information Flow Unlocks Multimodal Reasoning In Text-only LLMs
Recent advances in text-only large language models (LLMs), such as DeepSeek-R1, demonstrate remarkable reasoning ability. However, these models remain fragile or entirely incapable when extended to multi-modal tasks. Existing approaches largely rely on single-form captions, which lack diversity and often fail to adapt across different types of Visual Question Answering (VQA) benchmarks. As a result, they provide no principled or efficient channel for transmitting fine-grained visual information. We introduce Seeing Eye, a modular framework that unlocks multimodal reasoning in text-only LLMs through an agent-based small VLM translator. This translator acts as a perception agent: it can invoke specialized tools (e.g., OCR and crop) and iteratively distill multimodal inputs into structured intermediate representations (SIRs) tailored to the question. These SIRs are then passed to the text-only LLM, which serves as a reasoning agent. Crucially, the translator and reasoner engage in multi-round feedback and interaction, enabling the extraction of targeted visual details and yielding more confident answers. Experiments on knowledge-intensive VQA benchmarks, including MMMU and MIA-Bench, demonstrate that Seeing Eye not only reduces inference cost but also surpasses much larger end-to-end VLMs. For example, an instantiation combining a 3B-parameter vision translator with an 8B-parameter language reasoner outperforms a monolithic 32B VLM on challenging knowledge-based questions. Our results highlight that decoupling perception from reasoning via agent information flow offers a scalable and plug-and-play pathway to multimodal reasoning, allowing strong text-only LLMs to fully leverage their reasoning capabilities. Code is available at: https://github.com/ulab-uiuc/SeeingEye

ReviewerToo: Should AI Join The Program Committee? A Look At The Future of Peer Review
Peer review is the cornerstone of scientific publishing, yet it suffers from inconsistencies, reviewer subjectivity, and scalability challenges. We introduce ReviewerToo, a modular framework for studying and deploying AI-assisted peer review to complement human judgment with systematic and consistent assessments. ReviewerToo supports systematic experiments with specialized reviewer personas and structured evaluation criteria, and can be partially or fully integrated into real conference workflows. We validate ReviewerToo on a carefully curated dataset of 1,963 paper submissions from ICLR 2025, where our experiments with the gpt-oss-120b model achieves 81.8% accuracy for the task of categorizing a paper as accept/reject compared to 83.9% for the average human reviewer. Additionally, ReviewerToo-generated reviews are rated as higher quality than the human average by an LLM judge, though still trailing the strongest expert contributions. Our analysis highlights domains where AI reviewers excel (e.g., fact-checking, literature coverage) and where they struggle (e.g., assessing methodological novelty and theoretical contributions), underscoring the continued need for human expertise. Based on these findings, we propose guidelines for integrating AI into peer-review pipelines, showing how AI can enhance consistency, coverage, and fairness while leaving complex evaluative judgments to domain experts. Our work provides a foundation for systematic, hybrid peer-review systems that scale with the growth of scientific publishing.
Steer-MoE: Efficient Audio-Language Alignment with a Mixture-of-Experts Steering Module
Aligning pretrained audio encoders and Large Language Models (LLMs) offers a promising, parameter-efficient path to building powerful multimodal agents. However, existing methods often require costly full-model finetuning or rely on static adapters that may lack expressive power. Drawing inspiration from the Platonic Representation Hypothesis, we introduce SteerMoE, a novel and modular framework for audio-language alignment. SteerMoE freezes both the audio encoder and the LLM decoder, training only a lightweight steering module integrated within the encoder's layers. This module uses a Mixture-of-Experts (MoE) router to dynamically select and apply learned steering vectors, progressively transforming continuous audio representations into a space comprehensible to the LLM. By operating entirely in the continuous embedding space, our approach requires no modifications to the LLM's vocabulary and preserves its advanced reasoning and agentic capabilities. We demonstrate through experiments on ASR, audio understanding, and a qualitative function-calling task that SteerMoE achieves strong performance while remaining highly modular and computationally efficient, offering a robust new paradigm for developing sophisticated audio-language systems.
GraphSearch: An Agentic Deep Searching Workflow for Graph Retrieval-Augmented Generation
Graph Retrieval-Augmented Generation (GraphRAG) enhances factual reasoning in LLMs by structurally modeling knowledge through graph-based representations. However, existing GraphRAG approaches face two core limitations: shallow retrieval that fails to surface all critical evidence, and inefficient utilization of pre-constructed structural graph data, which hinders effective reasoning from complex queries. To address these challenges, we propose GraphSearch, a novel agentic deep searching workflow with dual-channel retrieval for GraphRAG. GraphSearch organizes the retrieval process into a modular framework comprising six modules, enabling multi-turn interactions and iterative reasoning. Furthermore, GraphSearch adopts a dual-channel retrieval strategy that issues semantic queries over chunk-based text data and relational queries over structural graph data, enabling comprehensive utilization of both modalities and their complementary strengths. Experimental results across six multi-hop RAG benchmarks demonstrate that GraphSearch consistently improves answer accuracy and generation quality over the traditional strategy, confirming GraphSearch as a promising direction for advancing graph retrieval-augmented generation.

Video Generators are Robot Policies
Despite tremendous progress in dexterous manipulation, current visuomotor policies remain fundamentally limited by two challenges: they struggle to generalize under perceptual or behavioral distribution shifts, and their performance is constrained by the size of human demonstration data. In this paper, we use video generation as a proxy for robot policy learning to address both limitations simultaneously. We propose Video Policy, a modular framework that combines video and action generation that can be trained end-to-end. Our results demonstrate that learning to generate videos of robot behavior allows for the extraction of policies with minimal demonstration data, significantly improving robustness and sample efficiency. Our method shows strong generalization to unseen objects, backgrounds, and tasks, both in simulation and the real world. We further highlight that task success is closely tied to the generated video, with action-free video data providing critical benefits for generalizing to novel tasks. By leveraging large-scale video generative models, we achieve superior performance compared to traditional behavior cloning, paving the way for more scalable and data-efficient robot policy learning.
VEGGIE: Instructional Editing and Reasoning of Video Concepts with Grounded Generation
Recent video diffusion models have enhanced video editing, but it remains challenging to handle instructional editing and diverse tasks (e.g., adding, removing, changing) within a unified framework. In this paper, we introduce VEGGIE, a Video Editor with Grounded Generation from Instructions, a simple end-to-end framework that unifies video concept editing, grounding, and reasoning based on diverse user instructions. Specifically, given a video and text query, VEGGIE first utilizes an MLLM to interpret user intentions in instructions and ground them to the video contexts, generating frame-specific grounded task queries for pixel-space responses. A diffusion model then renders these plans and generates edited videos that align with user intent. To support diverse tasks and complex instructions, we employ a curriculum learning strategy: first aligning the MLLM and video diffusion model with large-scale instructional image editing data, followed by end-to-end fine-tuning on high-quality multitask video data. Additionally, we introduce a novel data synthesis pipeline to generate paired instructional video editing data for model training. It transforms static image data into diverse, high-quality video editing samples by leveraging Image-to-Video models to inject dynamics. VEGGIE shows strong performance in instructional video editing with different editing skills, outperforming the best instructional baseline as a versatile model, while other models struggle with multi-tasking. VEGGIE also excels in video object grounding and reasoning segmentation, where other baselines fail. We further reveal how the multiple tasks help each other and highlight promising applications like zero-shot multimodal instructional and in-context video editing.

FactCheXcker: Mitigating Measurement Hallucinations in Chest X-ray Report Generation Models
Medical vision-language models often struggle with generating accurate quantitative measurements in radiology reports, leading to hallucinations that undermine clinical reliability. We introduce FactCheXcker, a modular framework that de-hallucinates radiology report measurements by leveraging an improved query-code-update paradigm. Specifically, FactCheXcker employs specialized modules and the code generation capabilities of large language models to solve measurement queries generated based on the original report. After extracting measurable findings, the results are incorporated into an updated report. We evaluate FactCheXcker on endotracheal tube placement, which accounts for an average of 78% of report measurements, using the MIMIC-CXR dataset and 11 medical report-generation models. Our results show that FactCheXcker significantly reduces hallucinations, improves measurement precision, and maintains the quality of the original reports. Specifically, FactCheXcker improves the performance of 10/11 models and achieves an average improvement of 135.0% in reducing measurement hallucinations measured by mean absolute error. Code is available at https://github.com/rajpurkarlab/FactCheXcker.
FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding
In this work, we propose Few Shot Domain Adapting Graph (FS-DAG), a scalable and efficient model architecture for visually rich document understanding (VRDU) in few-shot settings. FS-DAG leverages domain-specific and language/vision specific backbones within a modular framework to adapt to diverse document types with minimal data. The model is robust to practical challenges such as handling OCR errors, misspellings, and domain shifts, which are critical in real-world deployments. FS-DAG is highly performant with less than 90M parameters, making it well-suited for complex real-world applications for Information Extraction (IE) tasks where computational resources are limited. We demonstrate FS-DAG's capability through extensive experiments for information extraction task, showing significant improvements in convergence speed and performance compared to state-of-the-art methods. Additionally, this work highlights the ongoing progress in developing smaller, more efficient models that do not compromise on performance. Code : https://github.com/oracle-samples/fs-dag

Fin-ExBERT: User Intent based Text Extraction in Financial Context using Graph-Augmented BERT and trainable Plugin
Financial dialogue transcripts pose a unique challenge for sentence-level information extraction due to their informal structure, domain-specific vocabulary, and variable intent density. We introduce Fin-ExBERT, a lightweight and modular framework for extracting user intent-relevant sentences from annotated financial service calls. Our approach builds on a domain-adapted BERT (Bidirectional Encoder Representations from Transformers) backbone enhanced with LoRA (Low-Rank Adaptation) adapters, enabling efficient fine-tuning using limited labeled data. We propose a two-stage training strategy with progressive unfreezing: initially training a classifier head while freezing the backbone, followed by gradual fine-tuning of the entire model with differential learning rates. To ensure robust extraction under uncertainty, we adopt a dynamic thresholding strategy based on probability curvature (elbow detection), avoiding fixed cutoff heuristics. Empirical results show strong precision and F1 performance on real-world transcripts, with interpretable output suitable for downstream auditing and question-answering workflows. The full framework supports batched evaluation, visualization, and calibrated export, offering a deployable solution for financial dialogue mining.
AutoRAG-LoRA: Hallucination-Triggered Knowledge Retuning via Lightweight Adapters
Large Language Models (LLMs) have demonstrated remarkable fluency across a range of natural language tasks, yet remain vulnerable to hallucinations - factual inaccuracies that undermine trust in real world deployment. We present AutoRAG-LoRA, a modular framework for Retrieval-Augmented Generation (RAG) that tackles hallucination in large language models through lightweight LoRA-based adapters and KL-regularized training. Our pipeline integrates automated prompt rewriting, hybrid retrieval, and low-rank adapter tuning to ground responses in retrieved evidence. A hallucination detection module, using both classifier-based and self-evaluation techniques, assigns confidence scores to generated outputs, triggering an optional feedback correction loop. This loop enforces factual alignment via contrastive KL loss and adapter fine tuning. We demonstrate that AutoRAG-LoRA significantly reduces the factual drift while preserving the efficiency and modularity of the model.
Reasoning Language Models: A Blueprint
Reasoning language models (RLMs), also known as Large Reasoning Models (LRMs), such as OpenAI's o1 and o3, DeepSeek-V3, and Alibaba's QwQ, have redefined AI's problem-solving capabilities by extending large language models (LLMs) with advanced reasoning mechanisms. Yet, their high costs, proprietary nature, and complex architectures - uniquely combining Reinforcement Learning (RL), search heuristics, and LLMs - present accessibility and scalability challenges. To address these, we propose a comprehensive blueprint that organizes RLM components into a modular framework, based on a survey and analysis of all RLM works. This blueprint incorporates diverse reasoning structures (chains, trees, graphs, and nested forms), reasoning strategies (e.g., Monte Carlo Tree Search, Beam Search), RL concepts (policy, value models and others), and supervision schemes (Output-Based and Process-Based Supervision). We also provide detailed mathematical formulations and algorithmic specifications to simplify RLM implementation. By showing how schemes like LLaMA-Berry, QwQ, Journey Learning, and Graph of Thoughts fit as special cases, we demonstrate the blueprint's versatility and unifying potential. To illustrate its utility, we introduce x1, a modular implementation for rapid RLM prototyping and experimentation. Using x1 and a literature review, we provide key insights, such as multi-phase training for policy and value models, and the importance of familiar training distributions. Finally, we outline how RLMs can integrate with a broader LLM ecosystem, including tools and databases. Our work demystifies RLM construction, democratizes advanced reasoning capabilities, and fosters innovation, aiming to mitigate the gap between "rich AI" and "poor AI" by lowering barriers to RLM development and experimentation.





WritingBench: A Comprehensive Benchmark for Generative Writing
Recent advancements in large language models (LLMs) have significantly enhanced text generation capabilities, yet evaluating their performance in generative writing remains a challenge. Existing benchmarks primarily focus on generic text generation or limited in writing tasks, failing to capture the diverse requirements of high-quality written contents across various domains. To bridge this gap, we present WritingBench, a comprehensive benchmark designed to evaluate LLMs across 6 core writing domains and 100 subdomains, encompassing creative, persuasive, informative, and technical writing. We further propose a query-dependent evaluation framework that empowers LLMs to dynamically generate instance-specific assessment criteria. This framework is complemented by a fine-tuned critic model for criteria-aware scoring, enabling evaluations in style, format and length. The framework's validity is further demonstrated by its data curation capability, which enables 7B-parameter models to approach state-of-the-art (SOTA) performance. We open-source the benchmark, along with evaluation tools and modular framework components, to advance the development of LLMs in writing.

MuSLR: Multimodal Symbolic Logical Reasoning
Multimodal symbolic logical reasoning, which aims to deduce new facts from multimodal input via formal logic, is critical in high-stakes applications such as autonomous driving and medical diagnosis, as its rigorous, deterministic reasoning helps prevent serious consequences. To evaluate such capabilities of current state-of-the-art vision language models (VLMs), we introduce the first benchmark MuSLR for multimodal symbolic logical reasoning grounded in formal logical rules. MuSLR comprises 1,093 instances across 7 domains, including 35 atomic symbolic logic and 976 logical combinations, with reasoning depths ranging from 2 to 9. We evaluate 7 state-of-the-art VLMs on MuSLR and find that they all struggle with multimodal symbolic reasoning, with the best model, GPT-4.1, achieving only 46.8%. Thus, we propose LogiCAM, a modular framework that applies formal logical rules to multimodal inputs, boosting GPT-4.1's Chain-of-Thought performance by 14.13%, and delivering even larger gains on complex logics such as first-order logic. We also conduct a comprehensive error analysis, showing that around 70% of failures stem from logical misalignment between modalities, offering key insights to guide future improvements. All data and code are publicly available at https://llm-symbol.github.io/MuSLR.


SynLLM: A Comparative Analysis of Large Language Models for Medical Tabular Synthetic Data Generation via Prompt Engineering
Access to real-world medical data is often restricted due to privacy regulations, posing a significant barrier to the advancement of healthcare research. Synthetic data offers a promising alternative; however, generating realistic, clinically valid, and privacy-conscious records remains a major challenge. Recent advancements in Large Language Models (LLMs) offer new opportunities for structured data generation; however, existing approaches frequently lack systematic prompting strategies and comprehensive, multi-dimensional evaluation frameworks. In this paper, we present SynLLM, a modular framework for generating high-quality synthetic medical tabular data using 20 state-of-the-art open-source LLMs, including LLaMA, Mistral, and GPT variants, guided by structured prompts. We propose four distinct prompt types, ranging from example-driven to rule-based constraints, that encode schema, metadata, and domain knowledge to control generation without model fine-tuning. Our framework features a comprehensive evaluation pipeline that rigorously assesses generated data across statistical fidelity, clinical consistency, and privacy preservation. We evaluate SynLLM across three public medical datasets, including Diabetes, Cirrhosis, and Stroke, using 20 open-source LLMs. Our results show that prompt engineering significantly impacts data quality and privacy risk, with rule-based prompts achieving the best privacy-quality balance. SynLLM establishes that, when guided by well-designed prompts and evaluated with robust, multi-metric criteria, LLMs can generate synthetic medical data that is both clinically plausible and privacy-aware, paving the way for safer and more effective data sharing in healthcare research.
Modular Deep Learning
Transfer learning has recently become the dominant paradigm of machine learning. Pre-trained models fine-tuned for downstream tasks achieve better performance with fewer labelled examples. Nonetheless, it remains unclear how to develop models that specialise towards multiple tasks without incurring negative interference and that generalise systematically to non-identically distributed tasks. Modular deep learning has emerged as a promising solution to these challenges. In this framework, units of computation are often implemented as autonomous parameter-efficient modules. Information is conditionally routed to a subset of modules and subsequently aggregated. These properties enable positive transfer and systematic generalisation by separating computation from routing and updating modules locally. We offer a survey of modular architectures, providing a unified view over several threads of research that evolved independently in the scientific literature. Moreover, we explore various additional purposes of modularity, including scaling language models, causal inference, programme induction, and planning in reinforcement learning. Finally, we report various concrete applications where modularity has been successfully deployed such as cross-lingual and cross-modal knowledge transfer. Related talks and projects to this survey, are available at https://www.modulardeeplearning.com/.


PandaGuard: Systematic Evaluation of LLM Safety against Jailbreaking Attacks
Large language models (LLMs) have achieved remarkable capabilities but remain vulnerable to adversarial prompts known as jailbreaks, which can bypass safety alignment and elicit harmful outputs. Despite growing efforts in LLM safety research, existing evaluations are often fragmented, focused on isolated attack or defense techniques, and lack systematic, reproducible analysis. In this work, we introduce PandaGuard, a unified and modular framework that models LLM jailbreak safety as a multi-agent system comprising attackers, defenders, and judges. Our framework implements 19 attack methods and 12 defense mechanisms, along with multiple judgment strategies, all within a flexible plugin architecture supporting diverse LLM interfaces, multiple interaction modes, and configuration-driven experimentation that enhances reproducibility and practical deployment. Built on this framework, we develop PandaBench, a comprehensive benchmark that evaluates the interactions between these attack/defense methods across 49 LLMs and various judgment approaches, requiring over 3 billion tokens to execute. Our extensive evaluation reveals key insights into model vulnerabilities, defense cost-performance trade-offs, and judge consistency. We find that no single defense is optimal across all dimensions and that judge disagreement introduces nontrivial variance in safety assessments. We release the code, configurations, and evaluation results to support transparent and reproducible research in LLM safety.
Reducing Hallucinations in Language Model-based SPARQL Query Generation Using Post-Generation Memory Retrieval
The ability to generate SPARQL queries from natural language questions is crucial for ensuring efficient and accurate retrieval of structured data from knowledge graphs (KG). While large language models (LLMs) have been widely adopted for SPARQL query generation, they are often susceptible to hallucinations and out-of-distribution errors when producing KG elements like Uniform Resource Identifiers (URIs) based on internal parametric knowledge. This often results in content that appears plausible but is factually incorrect, posing significant challenges for their use in real-world information retrieval (IR) applications. This has led to increased research aimed at detecting and mitigating such errors. In this paper, we introduce PGMR (Post-Generation Memory Retrieval), a modular framework that incorporates a non-parametric memory module to retrieve KG elements and enhance LLM-based SPARQL query generation. Our experimental results indicate that PGMR consistently delivers strong performance across diverse datasets, data distributions, and LLMs. Notably, PGMR significantly mitigates URI hallucinations, nearly eliminating the problem in several scenarios.



AnywhereVLA: Language-Conditioned Exploration and Mobile Manipulation
We address natural language pick-and-place in unseen, unpredictable indoor environments with AnywhereVLA, a modular framework for mobile manipulation. A user text prompt serves as an entry point and is parsed into a structured task graph that conditions classical SLAM with LiDAR and cameras, metric semantic mapping, and a task-aware frontier exploration policy. An approach planner then selects visibility and reachability aware pre grasp base poses. For interaction, a compact SmolVLA manipulation head is fine tuned on platform pick and place trajectories for the SO-101 by TheRobotStudio, grounding local visual context and sub-goals into grasp and place proposals. The full system runs fully onboard on consumer-level hardware, with Jetson Orin NX for perception and VLA and an Intel NUC for SLAM, exploration, and control, sustaining real-time operation. We evaluated AnywhereVLA in a multi-room lab under static scenes and normal human motion. In this setting, the system achieves a 46% overall task success rate while maintaining throughput on embedded compute. By combining a classical stack with a fine-tuned VLA manipulation, the system inherits the reliability of geometry-based navigation with the agility and task generalization of language-conditioned manipulation.
ExPO: Unlocking Hard Reasoning with Self-Explanation-Guided Reinforcement Learning
Recent advances in large language models have been driven by reinforcement learning (RL)-style post-training, which improves reasoning by optimizing model outputs based on reward or preference signals. GRPO-style approaches implement this by using self-generated samples labeled by an outcome-based verifier. However, these methods depend heavily on the model's initial ability to produce positive samples. They primarily refine what the model already knows (distribution sharpening) rather than enabling the model to solve problems where it initially fails. This limitation is especially problematic in early-stage RL training and on challenging reasoning tasks, where positive samples are unlikely to be generated. To unlock reasoning ability in such settings, the model must explore new reasoning trajectories beyond its current output distribution. Such exploration requires access to sufficiently good positive samples to guide the learning. While expert demonstrations seem like a natural solution, we find that they are often ineffective in RL post-training. Instead, we identify two key properties of effective positive samples: they should (1) be likely under the current policy, and (2) increase the model's likelihood of predicting the correct answer. Based on these insights, we propose Self-Explanation Policy Optimization (ExPO)-a simple and modular framework that generates such samples by conditioning on the ground-truth answer. ExPO enables efficient exploration and guides the model to produce reasoning trajectories more aligned with its policy than expert-written CoTs, while ensuring higher quality than its own (incorrect) samples. Experiments show that ExPO improves both learning efficiency and final performance on reasoning benchmarks, surpassing expert-demonstration-based methods in challenging settings such as MATH level-5, where the model initially struggles the most.
ReasonGraph: Visualisation of Reasoning Paths
Large Language Models (LLMs) reasoning processes are challenging to analyze due to their complexity and the lack of organized visualization tools. We present ReasonGraph, a web-based platform for visualizing and analyzing LLM reasoning processes. It supports both sequential and tree-based reasoning methods while integrating with major LLM providers and over fifty state-of-the-art models. ReasonGraph incorporates an intuitive UI with meta reasoning method selection, configurable visualization parameters, and a modular framework that facilitates efficient extension. Our evaluation shows high parsing reliability, efficient processing, and strong usability across various downstream applications. By providing a unified visualization framework, ReasonGraph reduces cognitive load in analyzing complex reasoning paths, improves error detection in logical processes, and enables more effective development of LLM-based applications. The platform is open-source, promoting accessibility and reproducibility in LLM reasoning analysis.
High and Low Resolution Tradeoffs in Roadside Multimodal Sensing
Balancing cost and performance is crucial when choosing high- versus low-resolution point-cloud roadside sensors. For example, LiDAR delivers dense point cloud, while 4D millimeter-wave radar, though spatially sparser, embeds velocity cues that help distinguish objects and come at a lower price. Unfortunately, the sensor placement strategies will influence point cloud density and distribution across the coverage area. Compounding the first challenge is the fact that different sensor mixtures often demand distinct neural network architectures to maximize their complementary strengths. Without an evaluation framework that establishes a benchmark for comparison, it is imprudent to make claims regarding whether marginal gains result from higher resolution and new sensing modalities or from the algorithms. We present an ex-ante evaluation that addresses the two challenges. First, we realized a simulation tool that builds on integer programming to automatically compare different sensor placement strategies against coverage and cost jointly. Additionally, inspired by human multi-sensory integration, we propose a modular framework to assess whether reductions in spatial resolution can be compensated by informational richness in detecting traffic participants. Extensive experimental testing on the proposed framework shows that fusing velocity-encoded radar with low-resolution LiDAR yields marked gains (14 percent AP for pedestrians and an overall mAP improvement of 1.5 percent across six categories) at lower cost than high-resolution LiDAR alone. Notably, these marked gains hold regardless of the specific deep neural modules employed in our frame. The result challenges the prevailing assumption that high resolution are always superior to low-resolution alternatives.

DANLI: Deliberative Agent for Following Natural Language Instructions
Recent years have seen an increasing amount of work on embodied AI agents that can perform tasks by following human language instructions. However, most of these agents are reactive, meaning that they simply learn and imitate behaviors encountered in the training data. These reactive agents are insufficient for long-horizon complex tasks. To address this limitation, we propose a neuro-symbolic deliberative agent that, while following language instructions, proactively applies reasoning and planning based on its neural and symbolic representations acquired from past experience (e.g., natural language and egocentric vision). We show that our deliberative agent achieves greater than 70% improvement over reactive baselines on the challenging TEACh benchmark. Moreover, the underlying reasoning and planning processes, together with our modular framework, offer impressive transparency and explainability to the behaviors of the agent. This enables an in-depth understanding of the agent's capabilities, which shed light on challenges and opportunities for future embodied agents for instruction following. The code is available at https://github.com/sled-group/DANLI.



Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
Large pretrained (e.g., "foundation") models exhibit distinct capabilities depending on the domain of data they are trained on. While these domains are generic, they may only barely overlap. For example, visual-language models (VLMs) are trained on Internet-scale image captions, but large language models (LMs) are further trained on Internet-scale text with no images (e.g., spreadsheets, SAT questions, code). As a result, these models store different forms of commonsense knowledge across different domains. In this work, we show that this diversity is symbiotic, and can be leveraged through Socratic Models (SMs): a modular framework in which multiple pretrained models may be composed zero-shot i.e., via multimodal-informed prompting, to exchange information with each other and capture new multimodal capabilities, without requiring finetuning. With minimal engineering, SMs are not only competitive with state-of-the-art zero-shot image captioning and video-to-text retrieval, but also enable new applications such as (i) answering free-form questions about egocentric video, (ii) engaging in multimodal assistive dialogue with people (e.g., for cooking recipes) by interfacing with external APIs and databases (e.g., web search), and (iii) robot perception and planning.
Towards a Reinforcement Learning Environment Toolbox for Intelligent Electric Motor Control
Electric motors are used in many applications and their efficiency is strongly dependent on their control. Among others, PI approaches or model predictive control methods are well-known in the scientific literature and industrial practice. A novel approach is to use reinforcement learning (RL) to have an agent learn electric drive control from scratch merely by interacting with a suitable control environment. RL achieved remarkable results with super-human performance in many games (e.g. Atari classics or Go) and also becomes more popular in control tasks like cartpole or swinging pendulum benchmarks. In this work, the open-source Python package gym-electric-motor (GEM) is developed for ease of training of RL-agents for electric motor control. Furthermore, this package can be used to compare the trained agents with other state-of-the-art control approaches. It is based on the OpenAI Gym framework that provides a widely used interface for the evaluation of RL-agents. The initial package version covers different DC motor variants and the prevalent permanent magnet synchronous motor as well as different power electronic converters and a mechanical load model. Due to the modular setup of the proposed toolbox, additional motor, load, and power electronic devices can be easily extended in the future. Furthermore, different secondary effects like controller interlocking time or noise are considered. An intelligent controller example based on the deep deterministic policy gradient algorithm which controls a series DC motor is presented and compared to a cascaded PI-controller as a baseline for future research. Fellow researchers are encouraged to use the framework in their RL investigations or to contribute to the functional scope (e.g. further motor types) of the package.
Fractal Generative Models
Modularization is a cornerstone of computer science, abstracting complex functions into atomic building blocks. In this paper, we introduce a new level of modularization by abstracting generative models into atomic generative modules. Analogous to fractals in mathematics, our method constructs a new type of generative model by recursively invoking atomic generative modules, resulting in self-similar fractal architectures that we call fractal generative models. As a running example, we instantiate our fractal framework using autoregressive models as the atomic generative modules and examine it on the challenging task of pixel-by-pixel image generation, demonstrating strong performance in both likelihood estimation and generation quality. We hope this work could open a new paradigm in generative modeling and provide a fertile ground for future research. Code is available at https://github.com/LTH14/fractalgen.

MOD-X: A Modular Open Decentralized eXchange Framework proposal for Heterogeneous Interoperable Artificial Agents
As Artificial Intelligence systems evolve from monolithic models to ecosystems of specialized agents, the need for standardized communication protocols becomes increasingly critical. This paper introduces MOD-X (Modular Open Decentralized eXchange), a novel architectural framework proposal for agent interoperability that addresses key limitations of existing protocols. Unlike current approaches, MOD-X proposes a layered architecture with a Universal Message Bus, thorough state management, translation capabilities, and blockchain-based security mechanisms. We present MOD-X's architecture, compare it with existing protocols, and demonstrate its application through a worked example how it enables integration between heterogeneous specialist agents (agents with different architectures, vendors, capabilities, and knowledge representations--including rule-based systems, neural networks, symbolic reasoning engines, and legacy software with agent wrappers). MOD-X's key innovations include a publish-subscribe communication model, semantic capability discovery, and dynamic workflow orchestration--providing a framework that bridges theoretical formalism with practical implementation. This architecture addresses the growing need for truly decentralized, interoperable agent ecosystems that can scale effectively without the need for central coordination.

Configurable Foundation Models: Building LLMs from a Modular Perspective
Advancements in LLMs have recently unveiled challenges tied to computational efficiency and continual scalability due to their requirements of huge parameters, making the applications and evolution of these models on devices with limited computation resources and scenarios requiring various abilities increasingly cumbersome. Inspired by modularity within the human brain, there is a growing tendency to decompose LLMs into numerous functional modules, allowing for inference with part of modules and dynamic assembly of modules to tackle complex tasks, such as mixture-of-experts. To highlight the inherent efficiency and composability of the modular approach, we coin the term brick to represent each functional module, designating the modularized structure as configurable foundation models. In this paper, we offer a comprehensive overview and investigation of the construction, utilization, and limitation of configurable foundation models. We first formalize modules into emergent bricks - functional neuron partitions that emerge during the pre-training phase, and customized bricks - bricks constructed via additional post-training to improve the capabilities and knowledge of LLMs. Based on diverse functional bricks, we further present four brick-oriented operations: retrieval and routing, merging, updating, and growing. These operations allow for dynamic configuration of LLMs based on instructions to handle complex tasks. To verify our perspective, we conduct an empirical analysis on widely-used LLMs. We find that the FFN layers follow modular patterns with functional specialization of neurons and functional neuron partitions. Finally, we highlight several open issues and directions for future research. Overall, this paper aims to offer a fresh modular perspective on existing LLM research and inspire the future creation of more efficient and scalable foundational models.

MRAG: A Modular Retrieval Framework for Time-Sensitive Question Answering
Understanding temporal relations and answering time-sensitive questions is crucial yet a challenging task for question-answering systems powered by large language models (LLMs). Existing approaches either update the parametric knowledge of LLMs with new facts, which is resource-intensive and often impractical, or integrate LLMs with external knowledge retrieval (i.e., retrieval-augmented generation). However, off-the-shelf retrievers often struggle to identify relevant documents that require intensive temporal reasoning. To systematically study time-sensitive question answering, we introduce the TempRAGEval benchmark, which repurposes existing datasets by incorporating temporal perturbations and gold evidence labels. As anticipated, all existing retrieval methods struggle with these temporal reasoning-intensive questions. We further propose Modular Retrieval (MRAG), a trainless framework that includes three modules: (1) Question Processing that decomposes question into a main content and a temporal constraint; (2) Retrieval and Summarization that retrieves evidence and uses LLMs to summarize according to the main content; (3) Semantic-Temporal Hybrid Ranking that scores each evidence summarization based on both semantic and temporal relevance. On TempRAGEval, MRAG significantly outperforms baseline retrievers in retrieval performance, leading to further improvements in final answer accuracy.

A Probabilistic Framework for Modular Continual Learning
Modular approaches, which use a different composition of modules for each problem and avoid forgetting by design, have been shown to be a promising direction in continual learning (CL). However, searching through the large, discrete space of possible module compositions is a challenge because evaluating a composition's performance requires a round of neural network training. To address this challenge, we develop a modular CL framework, called PICLE, that accelerates search by using a probabilistic model to cheaply compute the fitness of each composition. The model combines prior knowledge about good module compositions with dataset-specific information. Its use is complemented by splitting up the search space into subsets, such as perceptual and latent subsets. We show that PICLE is the first modular CL algorithm to achieve different types of transfer while scaling to large search spaces. We evaluate it on two benchmark suites designed to capture different desiderata of CL techniques. On these benchmarks, PICLE offers significantly better performance than state-of-the-art CL baselines.
(Almost) Free Modality Stitching of Foundation Models
Foundation multi-modal models are often designed by stitching of multiple existing pretrained uni-modal models: for example, an image classifier with an text model. This stitching process is performed by training a connector module that aims to align the representation spaces of these uni-modal models towards a multi-modal objective. However, given the complexity of training such connectors on large scale web-based datasets coupled with the ever-increasing number of available pretrained uni-modal models, the task of uni-modal models selection and subsequent connector module training becomes computationally demanding. To address this under-studied critical problem, we propose Hypernetwork Model Alignment (Hyma), a novel all-in-one solution for optimal uni-modal model selection and connector training by leveraging hypernetworks. Specifically, our framework utilizes the parameter prediction capability of a hypernetwork to obtain jointly trained connector modules for N times M combinations of uni-modal models. In our experiments, Hyma reduces the cost of searching for the best performing uni-modal model pair by 10times, while matching the ranking and trained connector performance obtained via grid search across a suite of diverse multi-modal benchmarks.
TorchGAN: A Flexible Framework for GAN Training and Evaluation
TorchGAN is a PyTorch based framework for writing succinct and comprehensible code for training and evaluation of Generative Adversarial Networks. The framework's modular design allows effortless customization of the model architecture, loss functions, training paradigms, and evaluation metrics. The key features of TorchGAN are its extensibility, built-in support for a large number of popular models, losses and evaluation metrics, and zero overhead compared to vanilla PyTorch. By using the framework to implement several popular GAN models, we demonstrate its extensibility and ease of use. We also benchmark the training time of our framework for said models against the corresponding baseline PyTorch implementations and observe that TorchGAN's features bear almost zero overhead.

Discovering modular solutions that generalize compositionally
Many complex tasks can be decomposed into simpler, independent parts. Discovering such underlying compositional structure has the potential to enable compositional generalization. Despite progress, our most powerful systems struggle to compose flexibly. It therefore seems natural to make models more modular to help capture the compositional nature of many tasks. However, it is unclear under which circumstances modular systems can discover hidden compositional structure. To shed light on this question, we study a teacher-student setting with a modular teacher where we have full control over the composition of ground truth modules. This allows us to relate the problem of compositional generalization to that of identification of the underlying modules. In particular we study modularity in hypernetworks representing a general class of multiplicative interactions. We show theoretically that identification up to linear transformation purely from demonstrations is possible without having to learn an exponential number of module combinations. We further demonstrate empirically that under the theoretically identified conditions, meta-learning from finite data can discover modular policies that generalize compositionally in a number of complex environments.
Polymorphic Combinatorial Frameworks (PCF): Guiding the Design of Mathematically-Grounded, Adaptive AI Agents
The Polymorphic Combinatorial Framework (PCF) leverages Large Language Models (LLMs) and mathematical frameworks to guide the meta-prompt enabled design of solution spaces and adaptive AI agents for complex, dynamic environments. Unlike static agent architectures, PCF enables real-time parameter reconfiguration through mathematically-grounded combinatorial spaces, allowing agents to adapt their core behavioral traits dynamically. Grounded in combinatorial logic, topos theory, and rough fuzzy set theory, PCF defines a multidimensional SPARK parameter space (Skills, Personalities, Approaches, Resources, Knowledge) to capture agent behaviors. This paper demonstrates how LLMs can parameterize complex spaces and estimate likely parameter values/variabilities. Using PCF, we parameterized mock caf\'e domains (five levels of complexity), estimated variables/variabilities, and conducted over 1.25 million Monte Carlo simulations. The results revealed trends in agent adaptability and performance across the five complexity tiers, with diminishing returns at higher complexity levels highlighting thresholds for scalable designs. PCF enables the generation of optimized agent configurations for specific scenarios while maintaining logical consistency. This framework supports scalable, dynamic, explainable, and ethical AI applications in domains like customer service, healthcare, robotics, and collaborative systems, paving the way for adaptable and cooperative next-generation polymorphic agents.

CLAX: Fast and Flexible Neural Click Models in JAX
CLAX is a JAX-based library that implements classic click models using modern gradient-based optimization. While neural click models have emerged over the past decade, complex click models based on probabilistic graphical models (PGMs) have not systematically adopted gradient-based optimization, preventing practitioners from leveraging modern deep learning frameworks while preserving the interpretability of classic models. CLAX addresses this gap by replacing EM-based optimization with direct gradient-based optimization in a numerically stable manner. The framework's modular design enables the integration of any component, from embeddings and deep networks to custom modules, into classic click models for end-to-end optimization. We demonstrate CLAX's efficiency by running experiments on the full Baidu-ULTR dataset comprising over a billion user sessions in approx 2 hours on a single GPU, orders of magnitude faster than traditional EM approaches. CLAX implements ten classic click models, serving both industry practitioners seeking to understand user behavior and improve ranking performance at scale and researchers developing new click models. CLAX is available at: https://github.com/philipphager/clax
EoS-FM: Can an Ensemble of Specialist Models act as a Generalist Feature Extractor?
Recent advances in foundation models have shown great promise in domains such as natural language processing and computer vision, and similar efforts are now emerging in the Earth Observation community. These models aim to generalize across tasks with limited supervision, reducing the need for training separate models for each task. However, current strategies, which largely focus on scaling model size and dataset volume, require prohibitive computational and data resources, limiting accessibility to only a few large institutions. Moreover, this paradigm of ever-larger models stands in stark contrast with the principles of sustainable and environmentally responsible AI, as it leads to immense carbon footprints and resource inefficiency. In this work, we present a novel and efficient alternative: an Ensemble-of-Specialists framework for building Remote Sensing Foundation Models (RSFMs). Our method decomposes the training process into lightweight, task-specific ConvNeXtV2 specialists that can be frozen and reused. This modular approach offers strong advantages in efficiency, interpretability, and extensibility. Moreover, it naturally supports federated training, pruning, and continuous specialist integration, making it particularly well-suited for collaborative and resource-constrained settings. Our framework sets a new direction for building scalable and efficient RSFMs. All codes and pretrained models are available at https://github.com/pierreadorni/EoS-FM.
MOFDiff: Coarse-grained Diffusion for Metal-Organic Framework Design
Metal-organic frameworks (MOFs) are of immense interest in applications such as gas storage and carbon capture due to their exceptional porosity and tunable chemistry. Their modular nature has enabled the use of template-based methods to generate hypothetical MOFs by combining molecular building blocks in accordance with known network topologies. However, the ability of these methods to identify top-performing MOFs is often hindered by the limited diversity of the resulting chemical space. In this work, we propose MOFDiff: a coarse-grained (CG) diffusion model that generates CG MOF structures through a denoising diffusion process over the coordinates and identities of the building blocks. The all-atom MOF structure is then determined through a novel assembly algorithm. Equivariant graph neural networks are used for the diffusion model to respect the permutational and roto-translational symmetries. We comprehensively evaluate our model's capability to generate valid and novel MOF structures and its effectiveness in designing outstanding MOF materials for carbon capture applications with molecular simulations.

Master-ASR: Achieving Multilingual Scalability and Low-Resource Adaptation in ASR with Modular Learning
Despite the impressive performance recently achieved by automatic speech recognition (ASR), we observe two primary challenges that hinder its broader applications: (1) The difficulty of introducing scalability into the model to support more languages with limited training, inference, and storage overhead; (2) The low-resource adaptation ability that enables effective low-resource adaptation while avoiding over-fitting and catastrophic forgetting issues. Inspired by recent findings, we hypothesize that we can address the above challenges with modules widely shared across languages. To this end, we propose an ASR framework, dubbed \METHODNS, that, for the first time, simultaneously achieves strong multilingual scalability and low-resource adaptation ability thanks to its modularize-then-assemble strategy. Specifically, \METHOD learns a small set of generalizable sub-modules and adaptively assembles them for different languages to reduce the multilingual overhead and enable effective knowledge transfer for low-resource adaptation. Extensive experiments and visualizations demonstrate that \METHOD can effectively discover language similarity and improve multilingual and low-resource ASR performance over state-of-the-art (SOTA) methods, e.g., under multilingual-ASR, our framework achieves a 0.13sim2.41 lower character error rate (CER) with 30\% smaller inference overhead over SOTA solutions on multilingual ASR and a comparable CER, with nearly 50 times fewer trainable parameters over SOTA solutions on low-resource tuning, respectively.


pfl-research: simulation framework for accelerating research in Private Federated Learning
Federated learning (FL) is an emerging machine learning (ML) training paradigm where clients own their data and collaborate to train a global model, without revealing any data to the server and other participants. Researchers commonly perform experiments in a simulation environment to quickly iterate on ideas. However, existing open-source tools do not offer the efficiency required to simulate FL on larger and more realistic FL datasets. We introduce pfl-research, a fast, modular, and easy-to-use Python framework for simulating FL. It supports TensorFlow, PyTorch, and non-neural network models, and is tightly integrated with state-of-the-art privacy algorithms. We study the speed of open-source FL frameworks and show that pfl-research is 7-72times faster than alternative open-source frameworks on common cross-device setups. Such speedup will significantly boost the productivity of the FL research community and enable testing hypotheses on realistic FL datasets that were previously too resource intensive. We release a suite of benchmarks that evaluates an algorithm's overall performance on a diverse set of realistic scenarios. The code is available on GitHub at https://github.com/apple/pfl-research.

LoRA-Mixer: Coordinate Modular LoRA Experts Through Serial Attention Routing
Recent efforts to combine low-rank adaptation (LoRA) with mixture-of-experts (MoE) for adapting large language models (LLMs) to multiple tasks still exhibit prevailing limitations: they either swap entire attention/feed-forward layers for switch experts or bolt on parallel expert branches, diluting parameter efficiency and task fidelity. We propose the LoRA-Mixer, a modular and lightweight MoE framework that integrates LoRA experts. Our core innovation lies in replacing the projection matrices of the attention module's input/output linear layers with dynamically routed, task-specific LoRA experts. This design ensures seamless compatibility with diverse foundation models, including transformers and state space models (SSMs), by leveraging their inherent linear projection structures. The framework supports two operational paradigms: (1) joint optimization of LoRA experts and routing mechanisms via a novel hard-soft routing strategy, or (2) direct deployment of pre-trained, frozen LoRA modules sourced from external repositories. To enable robust router training with limited data while ensuring stable routing decisions and maximizing expert reuse, we introduce an adaptive Specialization Balance Loss (SBL) that jointly optimizes expert balance and task-specific alignment. Extensive experiments on seven benchmark datasets, including MedQA, CoLA, SST-2, GSM8K, ARC-E, ARC-C, and HumanEval, demonstrate the effectiveness of LoRA-Mixer. On datasets such as GSM8K, HumanEval, and MedQA, LoRA-Mixer achieves significant improvements of 7.61%, 4.88%, and 3.08% over the base models, respectively. Compared with state-of-the-art methods, LoRA-Mixer achieves additional improvements of 1.09%, 1.45%, and 1.68%, respectively, using only 48% of the parameters, demonstrating its efficiency and strong performance.
MoReVQA: Exploring Modular Reasoning Models for Video Question Answering
This paper addresses the task of video question answering (videoQA) via a decomposed multi-stage, modular reasoning framework. Previous modular methods have shown promise with a single planning stage ungrounded in visual content. However, through a simple and effective baseline, we find that such systems can lead to brittle behavior in practice for challenging videoQA settings. Thus, unlike traditional single-stage planning methods, we propose a multi-stage system consisting of an event parser, a grounding stage, and a final reasoning stage in conjunction with an external memory. All stages are training-free, and performed using few-shot prompting of large models, creating interpretable intermediate outputs at each stage. By decomposing the underlying planning and task complexity, our method, MoReVQA, improves over prior work on standard videoQA benchmarks (NExT-QA, iVQA, EgoSchema, ActivityNet-QA) with state-of-the-art results, and extensions to related tasks (grounded videoQA, paragraph captioning).
Emergent Mixture-of-Experts: Can Dense Pre-trained Transformers Benefit from Emergent Modular Structures?
Incorporating modular designs into neural networks demonstrates superior out-of-generalization, learning efficiency, etc. Existing modular neural networks are generally explicit because their modular architectures are pre-defined, and individual modules are expected to implement distinct functions. Conversely, recent works reveal that there exist implicit modular structures in standard pre-trained transformers, namely Emergent Modularity. They indicate that such modular structures exhibit during the early pre-training phase and are totally spontaneous. However, most transformers are still treated as monolithic models with their modular natures underutilized. Therefore, given the excellent properties of explicit modular architecture, we explore whether and how dense pre-trained transformers can benefit from emergent modular structures. To study this question, we construct Emergent Mixture-of-Experts (EMoE). Without introducing additional parameters, EMoE can be seen as the modular counterpart of the original model and can be effortlessly incorporated into downstream tuning. Extensive experiments (we tune 1785 models) on various downstream tasks (vision and language) and models (22M to1.5B) demonstrate that EMoE effectively boosts in-domain and out-of-domain generalization abilities. Further analysis and ablation study suggest that EMoE mitigates negative knowledge transfer and is robust to various configurations. Code is available at https://github.com/qiuzh20/EMoE

