Get trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
GenCompositor: Generative Video Compositing with Diffusion Transformer
Video compositing combines live-action footage to create video production, serving as a crucial technique in video creation and film production. Traditional pipelines require intensive labor efforts and expert collaboration, resulting in lengthy production cycles and high manpower costs. To address this issue, we automate this process with generative models, called generative video compositing. This new task strives to adaptively inject identity and motion information of foreground video to the target video in an interactive manner, allowing users to customize the size, motion trajectory, and other attributes of the dynamic elements added in final video. Specifically, we designed a novel Diffusion Transformer (DiT) pipeline based on its intrinsic properties. To maintain consistency of the target video before and after editing, we revised a light-weight DiT-based background preservation branch with masked token injection. As to inherit dynamic elements from other sources, a DiT fusion block is proposed using full self-attention, along with a simple yet effective foreground augmentation for training. Besides, for fusing background and foreground videos with different layouts based on user control, we developed a novel position embedding, named Extended Rotary Position Embedding (ERoPE). Finally, we curated a dataset comprising 61K sets of videos for our new task, called VideoComp. This data includes complete dynamic elements and high-quality target videos. Experiments demonstrate that our method effectively realizes generative video compositing, outperforming existing possible solutions in fidelity and consistency.



OThink-MR1: Stimulating multimodal generalized reasoning capabilities via dynamic reinforcement learning
Multimodal Large Language Models (MLLMs) have gained significant traction for their ability to process diverse input data types and generate coherent, contextually relevant outputs across various applications. While supervised fine-tuning (SFT) has been the predominant approach to enhance MLLM capabilities in task-specific optimization, it often falls short in fostering crucial generalized reasoning abilities. Although reinforcement learning (RL) holds great promise in overcoming these limitations, it encounters two significant challenges: (1) its generalized capacities in multimodal tasks remain largely unexplored, and (2) its training constraints, including the constant Kullback-Leibler divergence or the clamp strategy, often result in suboptimal bottlenecks. To address these challenges, we propose OThink-MR1, an advanced MLLM equipped with profound comprehension and reasoning capabilities across multimodal tasks. Specifically, we introduce Group Relative Policy Optimization with a dynamic Kullback-Leibler strategy (GRPO-D), which markedly enhances reinforcement learning (RL) performance. For Qwen2-VL-2B-Instruct, GRPO-D achieves a relative improvement of more than 5.72% over SFT and more than 13.59% over GRPO in same-task evaluation on two adapted datasets. Furthermore, GRPO-D demonstrates remarkable cross-task generalization capabilities, with an average relative improvement of more than 61.63% over SFT in cross-task evaluation. These results highlight that the MLLM trained with GRPO-D on one multimodal task can be effectively transferred to another task, underscoring the superior generalized reasoning capabilities of our proposed OThink-MR1 model.



FlowLoss: Dynamic Flow-Conditioned Loss Strategy for Video Diffusion Models
Video Diffusion Models (VDMs) can generate high-quality videos, but often struggle with producing temporally coherent motion. Optical flow supervision is a promising approach to address this, with prior works commonly employing warping-based strategies that avoid explicit flow matching. In this work, we explore an alternative formulation, FlowLoss, which directly compares flow fields extracted from generated and ground-truth videos. To account for the unreliability of flow estimation under high-noise conditions in diffusion, we propose a noise-aware weighting scheme that modulates the flow loss across denoising steps. Experiments on robotic video datasets suggest that FlowLoss improves motion stability and accelerates convergence in early training stages. Our findings offer practical insights for incorporating motion-based supervision into noise-conditioned generative models.
Dynamic Pricing for Airline Ancillaries with Customer Context
Ancillaries have become a major source of revenue and profitability in the travel industry. Yet, conventional pricing strategies are based on business rules that are poorly optimized and do not respond to changing market conditions. This paper describes the dynamic pricing model developed by Deepair solutions, an AI technology provider for travel suppliers. We present a pricing model that provides dynamic pricing recommendations specific to each customer interaction and optimizes expected revenue per customer. The unique nature of personalized pricing provides the opportunity to search over the market space to find the optimal price-point of each ancillary for each customer, without violating customer privacy. In this paper, we present and compare three approaches for dynamic pricing of ancillaries, with increasing levels of sophistication: (1) a two-stage forecasting and optimization model using a logistic mapping function; (2) a two-stage model that uses a deep neural network for forecasting, coupled with a revenue maximization technique using discrete exhaustive search; (3) a single-stage end-to-end deep neural network that recommends the optimal price. We describe the performance of these models based on both offline and online evaluations. We also measure the real-world business impact of these approaches by deploying them in an A/B test on an airline's internet booking website. We show that traditional machine learning techniques outperform human rule-based approaches in an online setting by improving conversion by 36% and revenue per offer by 10%. We also provide results for our offline experiments which show that deep learning algorithms outperform traditional machine learning techniques for this problem. Our end-to-end deep learning model is currently being deployed by the airline in their booking system.

Safe & Accurate at Speed with Tendons: A Robot Arm for Exploring Dynamic Motion
Operating robots precisely and at high speeds has been a long-standing goal of robotics research. Balancing these competing demands is key to enabling the seamless collaboration of robots and humans and increasing task performance. However, traditional motor-driven systems often fall short in this balancing act. Due to their rigid and often heavy design exacerbated by positioning the motors into the joints, faster motions of such robots transfer high forces at impact. To enable precise and safe dynamic motions, we introduce a four degree-of-freedom~(DoF) tendon-driven robot arm. Tendons allow placing the actuation at the base to reduce the robot's inertia, which we show significantly reduces peak collision forces compared to conventional robots with motors placed near the joints. Pairing our robot with pneumatic muscles allows generating high forces and highly accelerated motions, while benefiting from impact resilience through passive compliance. Since tendons are subject to additional friction and hence prone to wear and tear, we validate the reliability of our robotic arm on various experiments, including long-term dynamic motions. We also demonstrate its ease of control by quantifying the nonlinearities of the system and the performance on a challenging dynamic table tennis task learned from scratch using reinforcement learning. We open-source the entire hardware design, which can be largely 3D printed, the control software, and a proprioceptive dataset of 25 days of diverse robot motions at webdav.tuebingen.mpg.de/pamy2.
DESIRE: Dynamic Knowledge Consolidation for Rehearsal-Free Continual Learning
Continual learning aims to equip models with the ability to retain previously learned knowledge like a human. Recent work incorporating Parameter-Efficient Fine-Tuning has revitalized the field by introducing lightweight extension modules. However, existing methods usually overlook the issue of information leakage caused by the fact that the experiment data have been used in pre-trained models. Once these duplicate data are removed in the pre-training phase, their performance can be severely affected. In this paper, we propose a new LoRA-based rehearsal-free method named DESIRE. Our method avoids imposing additional constraints during training to mitigate catastrophic forgetting, thereby maximizing the learning of new classes. To integrate knowledge from old and new tasks, we propose two efficient post-processing modules. On the one hand, we retain only two sets of LoRA parameters for merging and propose dynamic representation consolidation to calibrate the merged feature representation. On the other hand, we propose decision boundary refinement to address classifier bias when training solely on new class data. Extensive experiments demonstrate that our method achieves state-of-the-art performance on multiple datasets and strikes an effective balance between stability and plasticity. Our code will be publicly available.

VideoRF: Rendering Dynamic Radiance Fields as 2D Feature Video Streams
Neural Radiance Fields (NeRFs) excel in photorealistically rendering static scenes. However, rendering dynamic, long-duration radiance fields on ubiquitous devices remains challenging, due to data storage and computational constraints. In this paper, we introduce VideoRF, the first approach to enable real-time streaming and rendering of dynamic radiance fields on mobile platforms. At the core is a serialized 2D feature image stream representing the 4D radiance field all in one. We introduce a tailored training scheme directly applied to this 2D domain to impose the temporal and spatial redundancy of the feature image stream. By leveraging the redundancy, we show that the feature image stream can be efficiently compressed by 2D video codecs, which allows us to exploit video hardware accelerators to achieve real-time decoding. On the other hand, based on the feature image stream, we propose a novel rendering pipeline for VideoRF, which has specialized space mappings to query radiance properties efficiently. Paired with a deferred shading model, VideoRF has the capability of real-time rendering on mobile devices thanks to its efficiency. We have developed a real-time interactive player that enables online streaming and rendering of dynamic scenes, offering a seamless and immersive free-viewpoint experience across a range of devices, from desktops to mobile phones.



HOT: Higher-Order Dynamic Graph Representation Learning with Efficient Transformers
Many graph representation learning (GRL) problems are dynamic, with millions of edges added or removed per second. A fundamental workload in this setting is dynamic link prediction: using a history of graph updates to predict whether a given pair of vertices will become connected. Recent schemes for link prediction in such dynamic settings employ Transformers, modeling individual graph updates as single tokens. In this work, we propose HOT: a model that enhances this line of works by harnessing higher-order (HO) graph structures; specifically, k-hop neighbors and more general subgraphs containing a given pair of vertices. Harnessing such HO structures by encoding them into the attention matrix of the underlying Transformer results in higher accuracy of link prediction outcomes, but at the expense of increased memory pressure. To alleviate this, we resort to a recent class of schemes that impose hierarchy on the attention matrix, significantly reducing memory footprint. The final design offers a sweetspot between high accuracy and low memory utilization. HOT outperforms other dynamic GRL schemes, for example achieving 9%, 7%, and 15% higher accuracy than - respectively - DyGFormer, TGN, and GraphMixer, for the MOOC dataset. Our design can be seamlessly extended towards other dynamic GRL workloads.
DAT++: Spatially Dynamic Vision Transformer with Deformable Attention
Transformers have shown superior performance on various vision tasks. Their large receptive field endows Transformer models with higher representation power than their CNN counterparts. Nevertheless, simply enlarging the receptive field also raises several concerns. On the one hand, using dense attention in ViT leads to excessive memory and computational cost, and features can be influenced by irrelevant parts that are beyond the region of interests. On the other hand, the handcrafted attention adopted in PVT or Swin Transformer is data agnostic and may limit the ability to model long-range relations. To solve this dilemma, we propose a novel deformable multi-head attention module, where the positions of key and value pairs in self-attention are adaptively allocated in a data-dependent way. This flexible scheme enables the proposed deformable attention to dynamically focus on relevant regions while maintains the representation power of global attention. On this basis, we present Deformable Attention Transformer (DAT), a general vision backbone efficient and effective for visual recognition. We further build an enhanced version DAT++. Extensive experiments show that our DAT++ achieves state-of-the-art results on various visual recognition benchmarks, with 85.9% ImageNet accuracy, 54.5 and 47.0 MS-COCO instance segmentation mAP, and 51.5 ADE20K semantic segmentation mIoU.
Generating Long Videos of Dynamic Scenes
We present a video generation model that accurately reproduces object motion, changes in camera viewpoint, and new content that arises over time. Existing video generation methods often fail to produce new content as a function of time while maintaining consistencies expected in real environments, such as plausible dynamics and object persistence. A common failure case is for content to never change due to over-reliance on inductive biases to provide temporal consistency, such as a single latent code that dictates content for the entire video. On the other extreme, without long-term consistency, generated videos may morph unrealistically between different scenes. To address these limitations, we prioritize the time axis by redesigning the temporal latent representation and learning long-term consistency from data by training on longer videos. To this end, we leverage a two-phase training strategy, where we separately train using longer videos at a low resolution and shorter videos at a high resolution. To evaluate the capabilities of our model, we introduce two new benchmark datasets with explicit focus on long-term temporal dynamics.

Long-Context Modeling with Dynamic Hierarchical Sparse Attention for On-Device LLMs
The quadratic cost of attention hinders the scalability of long-context LLMs, especially in resource-constrained settings. Existing static sparse methods such as sliding windows or global tokens utilizes the sparsity of attention to reduce the cost of attention, but poorly adapts to the content-dependent variations in attention due to their staticity. While previous work has proposed several dynamic approaches to improve flexibility, they still depend on predefined templates or heuristic mechanisms. Such strategies reduce generality and prune tokens that remain contextually important, limiting their accuracy across diverse tasks. To tackle these bottlenecks of existing methods for long-context modeling, we introduce Dynamic Hierarchical Sparse Attention (DHSA), a data-driven framework that dynamically predicts attention sparsity online without retraining. Our proposed DHSA adaptively segments sequences into variable-length chunks, then computes chunk representations by aggregating the token embeddings within each chunk. To avoid the bias introduced by varying chunk lengths, we apply length-normalized aggregation that scales the averaged embeddings by the square root of the chunk size. Finally, DHSA upsamples the chunk-level similarity scores to token level similarities to calculate importance scores that determine which token-level interactions should be preserved. Our experiments on Gemma2 with Needle-in-a-Haystack Test and LongBench show that DHSA matches dense attention in accuracy, while reducing prefill latency by 20-60% and peak memory usage by 35%. Compared to other representative baselines such as block sparse attention, DHSA achieves consistently higher accuracy (6-18% relative gains) with comparable or lower cost, offering an efficient and adaptable solution for long-context on-device LLMs.
DyGait: Exploiting Dynamic Representations for High-performance Gait Recognition
Gait recognition is a biometric technology that recognizes the identity of humans through their walking patterns. Compared with other biometric technologies, gait recognition is more difficult to disguise and can be applied to the condition of long-distance without the cooperation of subjects. Thus, it has unique potential and wide application for crime prevention and social security. At present, most gait recognition methods directly extract features from the video frames to establish representations. However, these architectures learn representations from different features equally but do not pay enough attention to dynamic features, which refers to a representation of dynamic parts of silhouettes over time (e.g. legs). Since dynamic parts of the human body are more informative than other parts (e.g. bags) during walking, in this paper, we propose a novel and high-performance framework named DyGait. This is the first framework on gait recognition that is designed to focus on the extraction of dynamic features. Specifically, to take full advantage of the dynamic information, we propose a Dynamic Augmentation Module (DAM), which can automatically establish spatial-temporal feature representations of the dynamic parts of the human body. The experimental results show that our DyGait network outperforms other state-of-the-art gait recognition methods. It achieves an average Rank-1 accuracy of 71.4% on the GREW dataset, 66.3% on the Gait3D dataset, 98.4% on the CASIA-B dataset and 98.3% on the OU-MVLP dataset.

Dynamic data sampler for cross-language transfer learning in large language models
Large Language Models (LLMs) have gained significant attention in the field of natural language processing (NLP) due to their wide range of applications. However, training LLMs for languages other than English poses significant challenges, due to the difficulty in acquiring large-scale corpus and the requisite computing resources. In this paper, we propose ChatFlow, a cross-language transfer-based LLM, to address these challenges and train large Chinese language models in a cost-effective manner. We employ a mix of Chinese, English, and parallel corpus to continuously train the LLaMA2 model, aiming to align cross-language representations and facilitate the knowledge transfer specifically to the Chinese language model. In addition, we use a dynamic data sampler to progressively transition the model from unsupervised pre-training to supervised fine-tuning. Experimental results demonstrate that our approach accelerates model convergence and achieves superior performance. We evaluate ChatFlow on popular Chinese and English benchmarks, the results indicate that it outperforms other Chinese models post-trained on LLaMA-2-7B.

Dynamic LLM-Agent Network: An LLM-agent Collaboration Framework with Agent Team Optimization
Large language model (LLM) agents have been shown effective on a wide range of tasks, and by ensembling multiple LLM agents, their performances could be further improved. Existing approaches employ a fixed set of agents to interact with each other in a static architecture, which limits their generalizability to various tasks and requires strong human prior in designing these agents. In this work, we propose to construct a strategic team of agents communicating in a dynamic interaction architecture based on the task query. Specifically, we build a framework named Dynamic LLM-Agent Network (DyLAN) for LLM-agent collaboration on complicated tasks like reasoning and code generation. DyLAN enables agents to interact for multiple rounds in a dynamic architecture with inference-time agent selection and an early-stopping mechanism to improve performance and efficiency. We further design an automatic agent team optimization algorithm based on an unsupervised metric termed Agent Importance Score, enabling the selection of best agents based on the contribution each agent makes. Empirically, we demonstrate that DyLAN performs well in both reasoning and code generation tasks with reasonable computational cost. DyLAN achieves 13.0% and 13.3% improvement on MATH and HumanEval, respectively, compared to a single execution on GPT-35-turbo. On specific subjects of MMLU, agent team optimization in DyLAN increases accuracy by up to 25.0%.



IntrinsicAvatar: Physically Based Inverse Rendering of Dynamic Humans from Monocular Videos via Explicit Ray Tracing
We present IntrinsicAvatar, a novel approach to recovering the intrinsic properties of clothed human avatars including geometry, albedo, material, and environment lighting from only monocular videos. Recent advancements in human-based neural rendering have enabled high-quality geometry and appearance reconstruction of clothed humans from just monocular videos. However, these methods bake intrinsic properties such as albedo, material, and environment lighting into a single entangled neural representation. On the other hand, only a handful of works tackle the problem of estimating geometry and disentangled appearance properties of clothed humans from monocular videos. They usually achieve limited quality and disentanglement due to approximations of secondary shading effects via learned MLPs. In this work, we propose to model secondary shading effects explicitly via Monte-Carlo ray tracing. We model the rendering process of clothed humans as a volumetric scattering process, and combine ray tracing with body articulation. Our approach can recover high-quality geometry, albedo, material, and lighting properties of clothed humans from a single monocular video, without requiring supervised pre-training using ground truth materials. Furthermore, since we explicitly model the volumetric scattering process and ray tracing, our model naturally generalizes to novel poses, enabling animation of the reconstructed avatar in novel lighting conditions.
Unveiling LLMs: The Evolution of Latent Representations in a Dynamic Knowledge Graph
Large Language Models (LLMs) demonstrate an impressive capacity to recall a vast range of factual knowledge. However, understanding their underlying reasoning and internal mechanisms in exploiting this knowledge remains a key research area. This work unveils the factual information an LLM represents internally for sentence-level claim verification. We propose an end-to-end framework to decode factual knowledge embedded in token representations from a vector space to a set of ground predicates, showing its layer-wise evolution using a dynamic knowledge graph. Our framework employs activation patching, a vector-level technique that alters a token representation during inference, to extract encoded knowledge. Accordingly, we neither rely on training nor external models. Using factual and common-sense claims from two claim verification datasets, we showcase interpretability analyses at local and global levels. The local analysis highlights entity centrality in LLM reasoning, from claim-related information and multi-hop reasoning to representation errors causing erroneous evaluation. On the other hand, the global reveals trends in the underlying evolution, such as word-based knowledge evolving into claim-related facts. By interpreting semantics from LLM latent representations and enabling graph-related analyses, this work enhances the understanding of the factual knowledge resolution process.

Beyond Benchmarks: Dynamic, Automatic And Systematic Red-Teaming Agents For Trustworthy Medical Language Models
Ensuring the safety and reliability of large language models (LLMs) in clinical practice is critical to prevent patient harm and promote trustworthy healthcare applications of AI. However, LLMs are advancing so rapidly that static safety benchmarks often become obsolete upon publication, yielding only an incomplete and sometimes misleading picture of model trustworthiness. We demonstrate that a Dynamic, Automatic, and Systematic (DAS) red-teaming framework that continuously stress-tests LLMs can reveal significant weaknesses of current LLMs across four safety-critical domains: robustness, privacy, bias/fairness, and hallucination. A suite of adversarial agents is applied to autonomously mutate test cases, identify/evolve unsafe-triggering strategies, and evaluate responses, uncovering vulnerabilities in real time without human intervention. Applying DAS to 15 proprietary and open-source LLMs revealed a stark contrast between static benchmark performance and vulnerability under adversarial pressure. Despite a median MedQA accuracy exceeding 80\%, 94\% of previously correct answers failed our dynamic robustness tests. We observed similarly high failure rates across other domains: privacy leaks were elicited in 86\% of scenarios, cognitive-bias priming altered clinical recommendations in 81\% of fairness tests, and we identified hallucination rates exceeding 66\% in widely used models. Such profound residual risks are incompatible with routine clinical practice. By converting red-teaming from a static checklist into a dynamic stress-test audit, DAS red-teaming offers the surveillance that hospitals/regulators/technology vendors require as LLMs become embedded in patient chatbots, decision-support dashboards, and broader healthcare workflows. Our framework delivers an evolvable, scalable, and reliable safeguard for the next generation of medical AI.
Beyond Robustness: Learning Unknown Dynamic Load Adaptation for Quadruped Locomotion on Rough Terrain
Unknown dynamic load carrying is one important practical application for quadruped robots. Such a problem is non-trivial, posing three major challenges in quadruped locomotion control. First, how to model or represent the dynamics of the load in a generic manner. Second, how to make the robot capture the dynamics without any external sensing. Third, how to enable the robot to interact with load handling the mutual effect and stabilizing the load. In this work, we propose a general load modeling approach called load characteristics modeling to capture the dynamics of the load. We integrate this proposed modeling technique and leverage recent advances in Reinforcement Learning (RL) based locomotion control to enable the robot to infer the dynamics of load movement and interact with the load indirectly to stabilize it and realize the sim-to-real deployment to verify its effectiveness in real scenarios. We conduct extensive comparative simulation experiments to validate the effectiveness and superiority of our proposed method. Results show that our method outperforms other methods in sudden load resistance, load stabilizing and locomotion with heavy load on rough terrain. https://leixinjonaschang.github.io/leggedloadadapt.github.io/{Project Page}.
Weak Supervision Dynamic KL-Weighted Diffusion Models Guided by Large Language Models
In this paper, we presents a novel method for improving text-to-image generation by combining Large Language Models (LLMs) with diffusion models, a hybrid approach aimed at achieving both higher quality and efficiency in image synthesis from text descriptions. Our approach introduces a new dynamic KL-weighting strategy to optimize the diffusion process, along with incorporating semantic understanding from pre-trained LLMs to guide the generation process. The proposed method significantly improves both the visual quality and alignment of generated images with text descriptions, addressing challenges such as computational inefficiency, instability in training, and robustness to textual variability. We evaluate our method on the COCO dataset and demonstrate its superior performance over traditional GAN-based models, both quantitatively and qualitatively. Extensive experiments, including ablation studies and human evaluations, confirm that our method outperforms existing approaches in terms of image realism, relevance to the input text, and overall aesthetic quality. Our approach also shows promise in scalability to other multimodal tasks, making it a versatile solution for a wide range of generative applications.
Beyond Prompts: Dynamic Conversational Benchmarking of Large Language Models
We introduce a dynamic benchmarking system for conversational agents that evaluates their performance through a single, simulated, and lengthy userleftrightarrowagent interaction. The interaction is a conversation between the user and agent, where multiple tasks are introduced and then undertaken concurrently. We context switch regularly to interleave the tasks, which constructs a realistic testing scenario in which we assess the Long-Term Memory, Continual Learning, and Information Integration capabilities of the agents. Results from both proprietary and open-source Large-Language Models show that LLMs in general perform well on single-task interactions, but they struggle on the same tasks when they are interleaved. Notably, short-context LLMs supplemented with an LTM system perform as well as or better than those with larger contexts. Our benchmark suggests that there are other challenges for LLMs responding to more natural interactions that contemporary benchmarks have heretofore not been able to capture.
Gaussian Head Avatar: Ultra High-fidelity Head Avatar via Dynamic Gaussians
Creating high-fidelity 3D head avatars has always been a research hotspot, but there remains a great challenge under lightweight sparse view setups. In this paper, we propose Gaussian Head Avatar represented by controllable 3D Gaussians for high-fidelity head avatar modeling. We optimize the neutral 3D Gaussians and a fully learned MLP-based deformation field to capture complex expressions. The two parts benefit each other, thereby our method can model fine-grained dynamic details while ensuring expression accuracy. Furthermore, we devise a well-designed geometry-guided initialization strategy based on implicit SDF and Deep Marching Tetrahedra for the stability and convergence of the training procedure. Experiments show our approach outperforms other state-of-the-art sparse-view methods, achieving ultra high-fidelity rendering quality at 2K resolution even under exaggerated expressions.




Dynamic Speculative Agent Planning
Despite their remarkable success in complex tasks propelling widespread adoption, large language-model-based agents still face critical deployment challenges due to prohibitive latency and inference costs. While recent work has explored various methods to accelerate inference, existing approaches suffer from significant limitations: they either fail to preserve performance fidelity, require extensive offline training of router modules, or incur excessive operational costs. Moreover, they provide minimal user control over the tradeoff between acceleration and other performance metrics. To address these gaps, we introduce Dynamic Speculative Planning (DSP), an asynchronous online reinforcement learning framework that provides lossless acceleration with substantially reduced costs without requiring additional pre-deployment preparation. DSP explicitly optimizes a joint objective balancing end-to-end latency against dollar cost, allowing practitioners to adjust a single parameter that steers the system toward faster responses, cheaper operation, or any point along this continuum. Experiments on two standard agent benchmarks demonstrate that DSP achieves comparable efficiency to the fastest lossless acceleration method while reducing total cost by 30% and unnecessary cost up to 60%. Our code and data are available through https://github.com/guanyilin428/Dynamic-Speculative-Planning.
Dynamic graph neural networks for enhanced volatility prediction in financial markets
Volatility forecasting is essential for risk management and decision-making in financial markets. Traditional models like Generalized Autoregressive Conditional Heteroskedasticity (GARCH) effectively capture volatility clustering but often fail to model complex, non-linear interdependencies between multiple indices. This paper proposes a novel approach using Graph Neural Networks (GNNs) to represent global financial markets as dynamic graphs. The Temporal Graph Attention Network (Temporal GAT) combines Graph Convolutional Networks (GCNs) and Graph Attention Networks (GATs) to capture the temporal and structural dynamics of volatility spillovers. By utilizing correlation-based and volatility spillover indices, the Temporal GAT constructs directed graphs that enhance the accuracy of volatility predictions. Empirical results from a 15-year study of eight major global indices show that the Temporal GAT outperforms traditional GARCH models and other machine learning methods, particularly in short- to mid-term forecasts. The sensitivity and scenario-based analysis over a range of parameters and hyperparameters further demonstrate the significance of the proposed technique. Hence, this work highlights the potential of GNNs in modeling complex market behaviors, providing valuable insights for financial analysts and investors.
D3D-VLP: Dynamic 3D Vision-Language-Planning Model for Embodied Grounding and Navigation
Embodied agents face a critical dilemma that end-to-end models lack interpretability and explicit 3D reasoning, while modular systems ignore cross-component interdependencies and synergies. To bridge this gap, we propose the Dynamic 3D Vision-Language-Planning Model (D3D-VLP). Our model introduces two key innovations: 1) A Dynamic 3D Chain-of-Thought (3D CoT) that unifies planning, grounding, navigation, and question answering within a single 3D-VLM and CoT pipeline; 2) A Synergistic Learning from Fragmented Supervision (SLFS) strategy, which uses a masked autoregressive loss to learn from massive and partially-annotated hybrid data. This allows different CoT components to mutually reinforce and implicitly supervise each other. To this end, we construct a large-scale dataset with 10M hybrid samples from 5K real scans and 20K synthetic scenes that are compatible with online learning methods such as RL and DAgger. Our D3D-VLP achieves state-of-the-art results on multiple benchmarks, including Vision-and-Language Navigation (R2R-CE, REVERIE-CE, NavRAG-CE), Object-goal Navigation (HM3D-OVON), and Task-oriented Sequential Grounding and Navigation (SG3D). Real-world mobile manipulation experiments further validate the effectiveness.
FMT$^{x}$: An Efficient and Asymptotically Optimal Extension of the Fast Marching Tree for Dynamic Replanning
Path planning in dynamic environments remains a core challenge in robotics, especially as autonomous systems are deployed in unpredictable spaces such as warehouses and public roads. While algorithms like Fast Marching Tree (FMT^{*}) offer asymptotically optimal solutions in static settings, their single-pass design prevents path revisions which are essential for real-time adaptation. On the other hand, full replanning is often too computationally expensive. This paper introduces FMT^{x}, an extension of the Fast Marching Tree algorithm that enables efficient and consistent replanning in dynamic environments. We revisit the neighbor selection rule of FMT^{*} and demonstrate that a minimal change overcomes its single-pass limitation, enabling the algorithm to update cost-to-come values upon discovering better connections without sacrificing asymptotic optimality or computational efficiency. By maintaining a cost-ordered priority queue and applying a selective update condition that uses an expanding neighbor to identify and trigger the re-evaluation of any node with a potentially suboptimal path, FMT^{x} ensures that suboptimal routes are efficiently repaired as the environment evolves. This targeted strategy preserves the inherent efficiency of FMT^{*} while enabling robust adaptation to changes in obstacle configuration. FMT^{x} is proven to recover an asymptotically optimal solution after environmental changes. Experimental results demonstrate that FMT^{x} outperforms the influential replanner RRT^{x}, reacting more swiftly to dynamic events with lower computational overhead and thus offering a more effective solution for real-time robotic navigation in unpredictable worlds.
Bingo: Boosting Efficient Reasoning of LLMs via Dynamic and Significance-based Reinforcement Learning
Large language models have demonstrated impressive reasoning capabilities, yet they often suffer from inefficiencies due to unnecessarily verbose or redundant outputs. While many works have explored reinforcement learning (RL) to enhance reasoning abilities, most primarily focus on improving accuracy, with limited attention to reasoning efficiency. Some existing approaches introduce direct length-based rewards to encourage brevity, but this often leads to noticeable drops in accuracy. In this paper, we propose Bingo, an RL framework that advances length-based reward design to boost efficient reasoning. Bingo incorporates two key mechanisms: a significance-aware length reward, which gradually guides the model to reduce only insignificant tokens, and a dynamic length reward, which initially encourages elaborate reasoning for hard questions but decays over time to improve overall efficiency. Experiments across multiple reasoning benchmarks show that Bingo improves both accuracy and efficiency. It outperforms the vanilla reward and several other length-based reward baselines in RL, achieving a favorable trade-off between accuracy and efficiency. These results underscore the potential of training LLMs explicitly for efficient reasoning.
A Psychology-based Unified Dynamic Framework for Curriculum Learning
Directly learning from examples of random difficulty levels is often challenging for both humans and machine learning models. A more effective strategy involves exposing learners to examples in a progressive order, from easy to difficult. Curriculum Learning (CL) has been proposed to implement this strategy in machine learning model training. However, two key challenges persist in CL framework design: defining the difficulty of training data and determining the appropriate amount of data to input at each training step. This paper presents a Psychology-based Unified Dynamic Framework for Curriculum Learning (PUDF), drawing inspiration from psychometrics. We quantify the difficulty of training data by applying Item Response Theory (IRT) to responses from Artificial Crowds (AC). This theory-driven IRT-AC approach leads to global (i.e., model-independent) and interpretable difficulty values. Leveraging IRT, we propose a Dynamic Data Selection via Model Ability Estimation (DDS-MAE) strategy to schedule the appropriate amount of data during model training. Since our difficulty labeling and model ability estimation are based on a consistent theory, namely IRT, their values are comparable within the same scope, potentially leading to a faster convergence compared to the other CL methods. Experimental results demonstrate that fine-tuning pre-trained language models with PUDF enhances their performance on the GLUE benchmark. Moreover, PUDF surpasses other state-of-the-art (SOTA) CL methods on the GLUE benchmark. We further explore the components of PUDF, namely the difficulty measurer (IRT-AC) and the training scheduler (DDS-MAE) qualitatively and quantitatively. Lastly, we conduct an ablation study to clarify which components of PUDF contribute to faster convergence and higher accuracy.
Dynamic Curriculum Learning for Great Ape Detection in the Wild
We propose a novel end-to-end curriculum learning approach for sparsely labelled animal datasets leveraging large volumes of unlabelled data to improve supervised species detectors. We exemplify the method in detail on the task of finding great apes in camera trap footage taken in challenging real-world jungle environments. In contrast to previous semi-supervised methods, our approach adjusts learning parameters dynamically over time and gradually improves detection quality by steering training towards virtuous self-reinforcement. To achieve this, we propose integrating pseudo-labelling with curriculum learning policies and show how learning collapse can be avoided. We discuss theoretical arguments, ablations, and significant performance improvements against various state-of-the-art systems when evaluating on the Extended PanAfrican Dataset holding approx. 1.8M frames. We also demonstrate our method can outperform supervised baselines with significant margins on sparse label versions of other animal datasets such as Bees and Snapshot Serengeti. We note that performance advantages are strongest for smaller labelled ratios common in ecological applications. Finally, we show that our approach achieves competitive benchmarks for generic object detection in MS-COCO and PASCAL-VOC indicating wider applicability of the dynamic learning concepts introduced. We publish all relevant source code, network weights, and data access details for full reproducibility. The code is available at https://github.com/youshyee/DCL-Detection.
Choreographing a World of Dynamic Objects
Dynamic objects in our physical 4D (3D + time) world are constantly evolving, deforming, and interacting with other objects, leading to diverse 4D scene dynamics. In this paper, we present a universal generative pipeline, CHORD, for CHOReographing Dynamic objects and scenes and synthesizing this type of phenomena. Traditional rule-based graphics pipelines to create these dynamics are based on category-specific heuristics, yet are labor-intensive and not scalable. Recent learning-based methods typically demand large-scale datasets, which may not cover all object categories in interest. Our approach instead inherits the universality from the video generative models by proposing a distillation-based pipeline to extract the rich Lagrangian motion information hidden in the Eulerian representations of 2D videos. Our method is universal, versatile, and category-agnostic. We demonstrate its effectiveness by conducting experiments to generate a diverse range of multi-body 4D dynamics, show its advantage compared to existing methods, and demonstrate its applicability in generating robotics manipulation policies. Project page: https://yanzhelyu.github.io/chord
Dynamic Prompt Learning: Addressing Cross-Attention Leakage for Text-Based Image Editing
Large-scale text-to-image generative models have been a ground-breaking development in generative AI, with diffusion models showing their astounding ability to synthesize convincing images following an input text prompt. The goal of image editing research is to give users control over the generated images by modifying the text prompt. Current image editing techniques are susceptible to unintended modifications of regions outside the targeted area, such as on the background or on distractor objects which have some semantic or visual relationship with the targeted object. According to our experimental findings, inaccurate cross-attention maps are at the root of this problem. Based on this observation, we propose Dynamic Prompt Learning (DPL) to force cross-attention maps to focus on correct noun words in the text prompt. By updating the dynamic tokens for nouns in the textual input with the proposed leakage repairment losses, we achieve fine-grained image editing over particular objects while preventing undesired changes to other image regions. Our method DPL, based on the publicly available Stable Diffusion, is extensively evaluated on a wide range of images, and consistently obtains superior results both quantitatively (CLIP score, Structure-Dist) and qualitatively (on user-evaluation). We show improved prompt editing results for Word-Swap, Prompt Refinement, and Attention Re-weighting, especially for complex multi-object scenes.

Dynamic Spectrum Mixer for Visual Recognition
Recently, MLP-based vision backbones have achieved promising performance in several visual recognition tasks. However, the existing MLP-based methods directly aggregate tokens with static weights, leaving the adaptability to different images untouched. Moreover, Recent research demonstrates that MLP-Transformer is great at creating long-range dependencies but ineffective at catching high frequencies that primarily transmit local information, which prevents it from applying to the downstream dense prediction tasks, such as semantic segmentation. To address these challenges, we propose a content-adaptive yet computationally efficient structure, dubbed Dynamic Spectrum Mixer (DSM). The DSM represents token interactions in the frequency domain by employing the Discrete Cosine Transform, which can learn long-term spatial dependencies with log-linear complexity. Furthermore, a dynamic spectrum weight generation layer is proposed as the spectrum bands selector, which could emphasize the informative frequency bands while diminishing others. To this end, the technique can efficiently learn detailed features from visual input that contains both high- and low-frequency information. Extensive experiments show that DSM is a powerful and adaptable backbone for a range of visual recognition tasks. Particularly, DSM outperforms previous transformer-based and MLP-based models, on image classification, object detection, and semantic segmentation tasks, such as 83.8 \% top-1 accuracy on ImageNet, and 49.9 \% mIoU on ADE20K.
Dynamic Novel View Synthesis in High Dynamic Range
High Dynamic Range Novel View Synthesis (HDR NVS) seeks to learn an HDR 3D model from Low Dynamic Range (LDR) training images captured under conventional imaging conditions. Current methods primarily focus on static scenes, implicitly assuming all scene elements remain stationary and non-living. However, real-world scenarios frequently feature dynamic elements, such as moving objects, varying lighting conditions, and other temporal events, thereby presenting a significantly more challenging scenario. To address this gap, we propose a more realistic problem named HDR Dynamic Novel View Synthesis (HDR DNVS), where the additional dimension ``Dynamic'' emphasizes the necessity of jointly modeling temporal radiance variations alongside sophisticated 3D translation between LDR and HDR. To tackle this complex, intertwined challenge, we introduce HDR-4DGS, a Gaussian Splatting-based architecture featured with an innovative dynamic tone-mapping module that explicitly connects HDR and LDR domains, maintaining temporal radiance coherence by dynamically adapting tone-mapping functions according to the evolving radiance distributions across the temporal dimension. As a result, HDR-4DGS achieves both temporal radiance consistency and spatially accurate color translation, enabling photorealistic HDR renderings from arbitrary viewpoints and time instances. Extensive experiments demonstrate that HDR-4DGS surpasses existing state-of-the-art methods in both quantitative performance and visual fidelity. Source code will be released.
DRAGON: Dynamic RAG Benchmark On News
Retrieval-Augmented Generation (RAG) is a widely adopted approach for improving the factuality of large language models (LLMs) by incorporating external knowledge at inference time. Although there exist multiple RAG benchmarks for English, evaluation resources for other languages, including Russian, remain scarce and static, failing to capture the dynamic nature of real-world deployments. In this work, we present DRAGON (Dynamic RAG Benchmark On News), the first dynamic benchmark for evaluating RAG systems in Russian on a changing news corpora. DRAGON is built upon a regularly updated corpus of Russian news and public documents and supports comprehensive evaluation of both the retriever and generator components. Question generation is performed automatically with the use of Knowledge Graph constructed from the corpus and enables the extraction of four core question types aligned with distinct subgraph patterns. We release a complete evaluation framework comprising the pipeline for automatic question generation, evaluation scripts, which are potentially reusable for other languages and multilingual settings, and benchmark data. We also launch a public leaderboard to encourage community participation and comparison.
DynaGuide: Steering Diffusion Polices with Active Dynamic Guidance
Deploying large, complex policies in the real world requires the ability to steer them to fit the needs of a situation. Most common steering approaches, like goal-conditioning, require training the robot policy with a distribution of test-time objectives in mind. To overcome this limitation, we present DynaGuide, a steering method for diffusion policies using guidance from an external dynamics model during the diffusion denoising process. DynaGuide separates the dynamics model from the base policy, which gives it multiple advantages, including the ability to steer towards multiple objectives, enhance underrepresented base policy behaviors, and maintain robustness on low-quality objectives. The separate guidance signal also allows DynaGuide to work with off-the-shelf pretrained diffusion policies. We demonstrate the performance and features of DynaGuide against other steering approaches in a series of simulated and real experiments, showing an average steering success of 70% on a set of articulated CALVIN tasks and outperforming goal-conditioning by 5.4x when steered with low-quality objectives. We also successfully steer an off-the-shelf real robot policy to express preference for particular objects and even create novel behavior. Videos and more can be found on the project website: https://dynaguide.github.io

Dynamic Double Space Tower
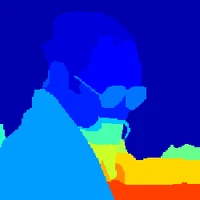
The Visual Question Answering (VQA) task requires the simultaneous understanding of image content and question semantics. However, existing methods often have difficulty handling complex reasoning scenarios due to insufficient cross-modal interaction and capturing the entity spatial relationships in the image.huang2023adaptiveliu2021comparingguibas2021adaptivezhang2022vsaWe studied a brand-new approach to replace the attention mechanism in order to enhance the reasoning ability of the model and its understanding of spatial relationships.Specifically, we propose a dynamic bidirectional spatial tower, which is divided into four layers to observe the image according to the principle of human gestalt vision. This naturally provides a powerful structural prior for the spatial organization between entities, enabling the model to no longer blindly search for relationships between pixels but make judgments based on more meaningful perceptual units. Change from "seeing images" to "perceiving and organizing image content".A large number of experiments have shown that our module can be used in any other multimodal model and achieve advanced results, demonstrating its potential in spatial relationship processing.Meanwhile, the multimodal visual question-answering model July trained by our method has achieved state-of-the-art results with only 3B parameters, especially on the question-answering dataset of spatial relations.

Knowing When to Stop: Dynamic Context Cutoff for Large Language Models
Large language models (LLMs) process entire input contexts indiscriminately, which is inefficient in cases where the information required to answer a query is localized within the context. We present dynamic context cutoff, a human-inspired method enabling LLMs to self-terminate processing upon acquiring sufficient task-relevant information. Through analysis of model internals, we discover that specific attention heads inherently encode "sufficiency signals" - detectable through lightweight classifiers - that predict when critical information has been processed. This reveals a new efficiency paradigm: models' internal understanding naturally dictates processing needs rather than external compression heuristics. Comprehensive experiments across six QA datasets (up to 40K tokens) with three model families (LLaMA/Qwen/Mistral, 1B0-70B) demonstrate 1.33x average token reduction while improving accuracy by 1.3%. Furthermore, our method demonstrates better performance with the same rate of token reduction compared to other context efficiency methods. Additionally, we observe an emergent scaling phenomenon: while smaller models require require probing for sufficiency detection, larger models exhibit intrinsic self-assessment capabilities through prompting.

Dynamic Gaussians Mesh: Consistent Mesh Reconstruction from Dynamic Scenes
Modern 3D engines and graphics pipelines require mesh as a memory-efficient representation, which allows efficient rendering, geometry processing, texture editing, and many other downstream operations. However, it is still highly difficult to obtain high-quality mesh in terms of detailed structure and time consistency from dynamic observations. To this end, we introduce Dynamic Gaussians Mesh (DG-Mesh), a framework to reconstruct a high-fidelity and time-consistent mesh from dynamic input. Our work leverages the recent advancement in 3D Gaussian Splatting to construct the mesh sequence with temporal consistency from dynamic observations. Building on top of this representation, DG-Mesh recovers high-quality meshes from the Gaussian points and can track the mesh vertices over time, which enables applications such as texture editing on dynamic objects. We introduce the Gaussian-Mesh Anchoring, which encourages evenly distributed Gaussians, resulting better mesh reconstruction through mesh-guided densification and pruning on the deformed Gaussians. By applying cycle-consistent deformation between the canonical and the deformed space, we can project the anchored Gaussian back to the canonical space and optimize Gaussians across all time frames. During the evaluation on different datasets, DG-Mesh provides significantly better mesh reconstruction and rendering than baselines. Project page: https://www.liuisabella.com/DG-Mesh
Large-scale Graph Representation Learning of Dynamic Brain Connectome with Transformers
Graph Transformers have recently been successful in various graph representation learning tasks, providing a number of advantages over message-passing Graph Neural Networks. Utilizing Graph Transformers for learning the representation of the brain functional connectivity network is also gaining interest. However, studies to date have underlooked the temporal dynamics of functional connectivity, which fluctuates over time. Here, we propose a method for learning the representation of dynamic functional connectivity with Graph Transformers. Specifically, we define the connectome embedding, which holds the position, structure, and time information of the functional connectivity graph, and use Transformers to learn its representation across time. We perform experiments with over 50,000 resting-state fMRI samples obtained from three datasets, which is the largest number of fMRI data used in studies by far. The experimental results show that our proposed method outperforms other competitive baselines in gender classification and age regression tasks based on the functional connectivity extracted from the fMRI data.

Dynamic Perceiver for Efficient Visual Recognition
Early exiting has become a promising approach to improving the inference efficiency of deep networks. By structuring models with multiple classifiers (exits), predictions for ``easy'' samples can be generated at earlier exits, negating the need for executing deeper layers. Current multi-exit networks typically implement linear classifiers at intermediate layers, compelling low-level features to encapsulate high-level semantics. This sub-optimal design invariably undermines the performance of later exits. In this paper, we propose Dynamic Perceiver (Dyn-Perceiver) to decouple the feature extraction procedure and the early classification task with a novel dual-branch architecture. A feature branch serves to extract image features, while a classification branch processes a latent code assigned for classification tasks. Bi-directional cross-attention layers are established to progressively fuse the information of both branches. Early exits are placed exclusively within the classification branch, thus eliminating the need for linear separability in low-level features. Dyn-Perceiver constitutes a versatile and adaptable framework that can be built upon various architectures. Experiments on image classification, action recognition, and object detection demonstrate that our method significantly improves the inference efficiency of different backbones, outperforming numerous competitive approaches across a broad range of computational budgets. Evaluation on both CPU and GPU platforms substantiate the superior practical efficiency of Dyn-Perceiver. Code is available at https://www.github.com/LeapLabTHU/Dynamic_Perceiver.


DRAG: Dynamic Region-Aware GCN for Privacy-Leaking Image Detection
The daily practice of sharing images on social media raises a severe issue about privacy leakage. To address the issue, privacy-leaking image detection is studied recently, with the goal to automatically identify images that may leak privacy. Recent advance on this task benefits from focusing on crucial objects via pretrained object detectors and modeling their correlation. However, these methods have two limitations: 1) they neglect other important elements like scenes, textures, and objects beyond the capacity of pretrained object detectors; 2) the correlation among objects is fixed, but a fixed correlation is not appropriate for all the images. To overcome the limitations, we propose the Dynamic Region-Aware Graph Convolutional Network (DRAG) that dynamically finds out crucial regions including objects and other important elements, and models their correlation adaptively for each input image. To find out crucial regions, we cluster spatially-correlated feature channels into several region-aware feature maps. Further, we dynamically model the correlation with the self-attention mechanism and explore the interaction among the regions with a graph convolutional network. The DRAG achieved an accuracy of 87% on the largest dataset for privacy-leaking image detection, which is 10 percentage points higher than the state of the art. The further case study demonstrates that it found out crucial regions containing not only objects but other important elements like textures.

Dynamic-TinyBERT: Boost TinyBERT's Inference Efficiency by Dynamic Sequence Length
Limited computational budgets often prevent transformers from being used in production and from having their high accuracy utilized. TinyBERT addresses the computational efficiency by self-distilling BERT into a smaller transformer representation having fewer layers and smaller internal embedding. However, TinyBERT's performance drops when we reduce the number of layers by 50%, and drops even more abruptly when we reduce the number of layers by 75% for advanced NLP tasks such as span question answering. Additionally, a separate model must be trained for each inference scenario with its distinct computational budget. In this work we present Dynamic-TinyBERT, a TinyBERT model that utilizes sequence-length reduction and Hyperparameter Optimization for enhanced inference efficiency per any computational budget. Dynamic-TinyBERT is trained only once, performing on-par with BERT and achieving an accuracy-speedup trade-off superior to any other efficient approaches (up to 3.3x with <1% loss-drop). Upon publication, the code to reproduce our work will be open-sourced.




Dynamic population-based meta-learning for multi-agent communication with natural language
In this work, our goal is to train agents that can coordinate with seen, unseen as well as human partners in a multi-agent communication environment involving natural language. Previous work using a single set of agents has shown great progress in generalizing to known partners, however it struggles when coordinating with unfamiliar agents. To mitigate that, recent work explored the use of population-based approaches, where multiple agents interact with each other with the goal of learning more generic protocols. These methods, while able to result in good coordination between unseen partners, still only achieve so in cases of simple languages, thus failing to adapt to human partners using natural language. We attribute this to the use of static populations and instead propose a dynamic population-based meta-learning approach that builds such a population in an iterative manner. We perform a holistic evaluation of our method on two different referential games, and show that our agents outperform all prior work when communicating with seen partners and humans. Furthermore, we analyze the natural language generation skills of our agents, where we find that our agents also outperform strong baselines. Finally, we test the robustness of our agents when communicating with out-of-population agents and carefully test the importance of each component of our method through ablation studies.

TLDR: Token Loss Dynamic Reweighting for Reducing Repetitive Utterance Generation
Natural Language Generation (NLG) models are prone to generating repetitive utterances. In this work, we study the repetition problem for encoder-decoder models, using both recurrent neural network (RNN) and transformer architectures. To this end, we consider the chit-chat task, where the problem is more prominent than in other tasks that need encoder-decoder architectures. We first study the influence of model architectures. By using pre-attention and highway connections for RNNs, we manage to achieve lower repetition rates. However, this method does not generalize to other models such as transformers. We hypothesize that the deeper reason is that in the training corpora, there are hard tokens that are more difficult for a generative model to learn than others and, once learning has finished, hard tokens are still under-learned, so that repetitive generations are more likely to happen. Based on this hypothesis, we propose token loss dynamic reweighting (TLDR) that applies differentiable weights to individual token losses. By using higher weights for hard tokens and lower weights for easy tokens, NLG models are able to learn individual tokens at different paces. Experiments on chit-chat benchmark datasets show that TLDR is more effective in repetition reduction for both RNN and transformer architectures than baselines using different weighting functions.

Dynamic Knowledge Routing Network For Target-Guided Open-Domain Conversation
Target-guided open-domain conversation aims to proactively and naturally guide a dialogue agent or human to achieve specific goals, topics or keywords during open-ended conversations. Existing methods mainly rely on single-turn datadriven learning and simple target-guided strategy without considering semantic or factual knowledge relations among candidate topics/keywords. This results in poor transition smoothness and low success rate. In this work, we adopt a structured approach that controls the intended content of system responses by introducing coarse-grained keywords, attains smooth conversation transition through turn-level supervised learning and knowledge relations between candidate keywords, and drives an conversation towards an specified target with discourse-level guiding strategy. Specially, we propose a novel dynamic knowledge routing network (DKRN) which considers semantic knowledge relations among candidate keywords for accurate next topic prediction of next discourse. With the help of more accurate keyword prediction, our keyword-augmented response retrieval module can achieve better retrieval performance and more meaningful conversations. Besides, we also propose a novel dual discourse-level target-guided strategy to guide conversations to reach their goals smoothly with higher success rate. Furthermore, to push the research boundary of target-guided open-domain conversation to match real-world scenarios better, we introduce a new large-scale Chinese target-guided open-domain conversation dataset (more than 900K conversations) crawled from Sina Weibo. Quantitative and human evaluations show our method can produce meaningful and effective target-guided conversations, significantly improving over other state-of-the-art methods by more than 20% in success rate and more than 0.6 in average smoothness score.
OmniZip: Audio-Guided Dynamic Token Compression for Fast Omnimodal Large Language Models
Omnimodal large language models (OmniLLMs) have attracted increasing research attention of late towards unified audio-video understanding, wherein processing audio-video token sequences creates a significant computational bottleneck, however. Existing token compression methods have yet to accommodate this emerging need of jointly compressing multimodal tokens. To bridge this gap, we present OmniZip, a training-free, audio-guided audio-visual token-compression framework that optimizes multimodal token representation and accelerates inference. Specifically, OmniZip first identifies salient audio tokens, then computes an audio retention score for each time group to capture information density, thereby dynamically guiding video token pruning and preserving cues from audio anchors enhanced by cross-modal similarity. For each time window, OmniZip compresses the video tokens using an interleaved spatio-temporal scheme. Extensive empirical results demonstrate the merits of OmniZip - it achieves 3.42X inference speedup and 1.4X memory reduction over other top-performing counterparts, while maintaining performance with no training.
How Can Input Reformulation Improve Tool Usage Accuracy in a Complex Dynamic Environment? A Study on $τ$-bench
Recent advances in reasoning and planning capabilities of large language models (LLMs) have enabled their potential as autonomous agents capable of tool use in dynamic environments. However, in multi-turn conversational environments like tau-bench, these agents often struggle with consistent reasoning, adherence to domain-specific policies, and extracting correct information over a long horizon of tool-calls and conversation. To capture and mitigate these failures, we conduct a comprehensive manual analysis of the common errors occurring in the conversation trajectories. We then experiment with reformulations of inputs to the tool-calling agent for improvement in agent decision making. Finally, we propose the Input-Reformulation Multi-Agent (IRMA) framework, which automatically reformulates user queries augmented with relevant domain rules and tool suggestions for the tool-calling agent to focus on. The results show that IRMA significantly outperforms ReAct, Function Calling, and Self-Reflection by 16.1%, 12.7%, and 19.1%, respectively, in overall pass^5 scores. These findings highlight the superior reliability and consistency of IRMA compared to other methods in dynamic environments.

PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
In this study, we investigate whether attention-based information flow inside large language models (LLMs) is aggregated through noticeable patterns for long context processing. Our observations reveal that LLMs aggregate information through Pyramidal Information Funneling where attention is scattering widely in lower layers, progressively consolidating within specific contexts, and ultimately focusin on critical tokens (a.k.a massive activation or attention sink) in higher layers. Motivated by these insights, we developed PyramidKV, a novel and effective KV cache compression method. This approach dynamically adjusts the KV cache size across different layers, allocating more cache in lower layers and less in higher ones, diverging from traditional methods that maintain a uniform KV cache size. Our experimental evaluations, utilizing the LongBench benchmark, show that PyramidKV matches the performance of models with a full KV cache while retaining only 12% of the KV cache, thus significantly reducing memory usage. In scenarios emphasizing memory efficiency, where only 0.7% of the KV cache is maintained, PyramidKV surpasses other KV cache compression techniques achieving up to a 20.5 absolute accuracy improvement on TREC.



High Dynamic Range Novel View Synthesis with Single Exposure
High Dynamic Range Novel View Synthesis (HDR-NVS) aims to establish a 3D scene HDR model from Low Dynamic Range (LDR) imagery. Typically, multiple-exposure LDR images are employed to capture a wider range of brightness levels in a scene, as a single LDR image cannot represent both the brightest and darkest regions simultaneously. While effective, this multiple-exposure HDR-NVS approach has significant limitations, including susceptibility to motion artifacts (e.g., ghosting and blurring), high capture and storage costs. To overcome these challenges, we introduce, for the first time, the single-exposure HDR-NVS problem, where only single exposure LDR images are available during training. We further introduce a novel approach, Mono-HDR-3D, featuring two dedicated modules formulated by the LDR image formation principles, one for converting LDR colors to HDR counterparts, and the other for transforming HDR images to LDR format so that unsupervised learning is enabled in a closed loop. Designed as a meta-algorithm, our approach can be seamlessly integrated with existing NVS models. Extensive experiments show that Mono-HDR-3D significantly outperforms previous methods. Source code will be released.
Can Large Language Models Adapt to Other Agents In-Context?
As the research community aims to build better AI assistants that are more dynamic and personalized to the diversity of humans that they interact with, there is increased interest in evaluating the theory of mind capabilities of large language models (LLMs). Indeed, several recent studies suggest that LLM theory of mind capabilities are quite impressive, approximating human-level performance. Our paper aims to rebuke this narrative and argues instead that past studies were not directly measuring agent performance, potentially leading to findings that are illusory in nature as a result. We draw a strong distinction between what we call literal theory of mind i.e. measuring the agent's ability to predict the behavior of others and functional theory of mind i.e. adapting to agents in-context based on a rational response to predictions of their behavior. We find that top performing open source LLMs may display strong capabilities in literal theory of mind, depending on how they are prompted, but seem to struggle with functional theory of mind -- even when partner policies are exceedingly simple. Our work serves to highlight the double sided nature of inductive bias in LLMs when adapting to new situations. While this bias can lead to strong performance over limited horizons, it often hinders convergence to optimal long-term behavior.
GMS-VINS:Multi-category Dynamic Objects Semantic Segmentation for Enhanced Visual-Inertial Odometry Using a Promptable Foundation Model
Visual-inertial odometry (VIO) is widely used in various fields, such as robots, drones, and autonomous vehicles, due to its low cost and complementary sensors. Most VIO methods presuppose that observed objects are static and time-invariant. However, real-world scenes often feature dynamic objects, compromising the accuracy of pose estimation. These moving entities include cars, trucks, buses, motorcycles, and pedestrians. The diversity and partial occlusion of these objects present a tough challenge for existing dynamic object removal techniques. To tackle this challenge, we introduce GMS-VINS, which integrates an enhanced SORT algorithm along with a robust multi-category segmentation framework into VIO, thereby improving pose estimation accuracy in environments with diverse dynamic objects and frequent occlusions. Leveraging the promptable foundation model, our solution efficiently tracks and segments a wide range of object categories. The enhanced SORT algorithm significantly improves the reliability of tracking multiple dynamic objects, especially in urban settings with partial occlusions or swift movements. We evaluated our proposed method using multiple public datasets representing various scenes, as well as in a real-world scenario involving diverse dynamic objects. The experimental results demonstrate that our proposed method performs impressively in multiple scenarios, outperforming other state-of-the-art methods. This highlights its remarkable generalization and adaptability in diverse dynamic environments, showcasing its potential to handle various dynamic objects in practical applications.
MoSca: Dynamic Gaussian Fusion from Casual Videos via 4D Motion Scaffolds
We introduce 4D Motion Scaffolds (MoSca), a neural information processing system designed to reconstruct and synthesize novel views of dynamic scenes from monocular videos captured casually in the wild. To address such a challenging and ill-posed inverse problem, we leverage prior knowledge from foundational vision models, lift the video data to a novel Motion Scaffold (MoSca) representation, which compactly and smoothly encodes the underlying motions / deformations. The scene geometry and appearance are then disentangled from the deformation field, and are encoded by globally fusing the Gaussians anchored onto the MoSca and optimized via Gaussian Splatting. Additionally, camera poses can be seamlessly initialized and refined during the dynamic rendering process, without the need for other pose estimation tools. Experiments demonstrate state-of-the-art performance on dynamic rendering benchmarks.

LAN-HDR: Luminance-based Alignment Network for High Dynamic Range Video Reconstruction
As demands for high-quality videos continue to rise, high-resolution and high-dynamic range (HDR) imaging techniques are drawing attention. To generate an HDR video from low dynamic range (LDR) images, one of the critical steps is the motion compensation between LDR frames, for which most existing works employed the optical flow algorithm. However, these methods suffer from flow estimation errors when saturation or complicated motions exist. In this paper, we propose an end-to-end HDR video composition framework, which aligns LDR frames in the feature space and then merges aligned features into an HDR frame, without relying on pixel-domain optical flow. Specifically, we propose a luminance-based alignment network for HDR (LAN-HDR) consisting of an alignment module and a hallucination module. The alignment module aligns a frame to the adjacent reference by evaluating luminance-based attention, excluding color information. The hallucination module generates sharp details, especially for washed-out areas due to saturation. The aligned and hallucinated features are then blended adaptively to complement each other. Finally, we merge the features to generate a final HDR frame. In training, we adopt a temporal loss, in addition to frame reconstruction losses, to enhance temporal consistency and thus reduce flickering. Extensive experiments demonstrate that our method performs better or comparable to state-of-the-art methods on several benchmarks.
DADA: Dialect Adaptation via Dynamic Aggregation of Linguistic Rules
Existing large language models (LLMs) that mainly focus on Standard American English (SAE) often lead to significantly worse performance when being applied to other English dialects. While existing mitigations tackle discrepancies for individual target dialects, they assume access to high-accuracy dialect identification systems. The boundaries between dialects are inherently flexible, making it difficult to categorize language into discrete predefined categories. In this paper, we propose DADA (Dialect Adaptation via Dynamic Aggregation), a modular approach to imbue SAE-trained models with multi-dialectal robustness by composing adapters which handle specific linguistic features. The compositional architecture of DADA allows for both targeted adaptation to specific dialect variants and simultaneous adaptation to various dialects. We show that DADA is effective for both single task and instruction finetuned language models, offering an extensible and interpretable framework for adapting existing LLMs to different English dialects.

DynaMITe: Dynamic Query Bootstrapping for Multi-object Interactive Segmentation Transformer
Most state-of-the-art instance segmentation methods rely on large amounts of pixel-precise ground-truth annotations for training, which are expensive to create. Interactive segmentation networks help generate such annotations based on an image and the corresponding user interactions such as clicks. Existing methods for this task can only process a single instance at a time and each user interaction requires a full forward pass through the entire deep network. We introduce a more efficient approach, called DynaMITe, in which we represent user interactions as spatio-temporal queries to a Transformer decoder with a potential to segment multiple object instances in a single iteration. Our architecture also alleviates any need to re-compute image features during refinement, and requires fewer interactions for segmenting multiple instances in a single image when compared to other methods. DynaMITe achieves state-of-the-art results on multiple existing interactive segmentation benchmarks, and also on the new multi-instance benchmark that we propose in this paper.
An Embedding-Dynamic Approach to Self-supervised Learning
A number of recent self-supervised learning methods have shown impressive performance on image classification and other tasks. A somewhat bewildering variety of techniques have been used, not always with a clear understanding of the reasons for their benefits, especially when used in combination. Here we treat the embeddings of images as point particles and consider model optimization as a dynamic process on this system of particles. Our dynamic model combines an attractive force for similar images, a locally dispersive force to avoid local collapse, and a global dispersive force to achieve a globally-homogeneous distribution of particles. The dynamic perspective highlights the advantage of using a delayed-parameter image embedding (a la BYOL) together with multiple views of the same image. It also uses a purely-dynamic local dispersive force (Brownian motion) that shows improved performance over other methods and does not require knowledge of other particle coordinates. The method is called MSBReg which stands for (i) a Multiview centroid loss, which applies an attractive force to pull different image view embeddings toward their centroid, (ii) a Singular value loss, which pushes the particle system toward spatially homogeneous density, (iii) a Brownian diffusive loss. We evaluate downstream classification performance of MSBReg on ImageNet as well as transfer learning tasks including fine-grained classification, multi-class object classification, object detection, and instance segmentation. In addition, we also show that applying our regularization term to other methods further improves their performance and stabilize the training by preventing a mode collapse.

DynaSent: A Dynamic Benchmark for Sentiment Analysis
We introduce DynaSent ('Dynamic Sentiment'), a new English-language benchmark task for ternary (positive/negative/neutral) sentiment analysis. DynaSent combines naturally occurring sentences with sentences created using the open-source Dynabench Platform, which facilities human-and-model-in-the-loop dataset creation. DynaSent has a total of 121,634 sentences, each validated by five crowdworkers, and its development and test splits are designed to produce chance performance for even the best models we have been able to develop; when future models solve this task, we will use them to create DynaSent version 2, continuing the dynamic evolution of this benchmark. Here, we report on the dataset creation effort, focusing on the steps we took to increase quality and reduce artifacts. We also present evidence that DynaSent's Neutral category is more coherent than the comparable category in other benchmarks, and we motivate training models from scratch for each round over successive fine-tuning.


QwenLong-CPRS: Towards $\infty$-LLMs with Dynamic Context Optimization
This technical report presents QwenLong-CPRS, a context compression framework designed for explicit long-context optimization, addressing prohibitive computation overhead during the prefill stage and the "lost in the middle" performance degradation of large language models (LLMs) during long sequence processing. Implemented through a novel dynamic context optimization mechanism, QwenLong-CPRS enables multi-granularity context compression guided by natural language instructions, achieving both efficiency gains and improved performance. Evolved from the Qwen architecture series, QwenLong-CPRS introduces four key innovations: (1) Natural language-guided dynamic optimization, (2) Bidirectional reasoning layers for enhanced boundary awareness, (3) Token critic mechanisms with language modeling heads, and (4) Window-parallel inference. Comprehensive evaluations across five benchmarks (4K-2M word contexts) demonstrate QwenLong-CPRS's threefold effectiveness: (1) Consistent superiority over other context management methods like RAG and sparse attention in both accuracy and efficiency. (2) Architecture-agnostic integration with all flagship LLMs, including GPT-4o, Gemini2.0-pro, Claude3.7-sonnet, DeepSeek-v3, and Qwen2.5-max, achieves 21.59times context compression alongside 19.15-point average performance gains; (3) Deployed with Qwen2.5-32B-Instruct, QwenLong-CPRS surpasses leading proprietary LLMs by 4.85 and 10.88 points on Ruler-128K and InfiniteBench, establishing new SOTA performance.



Click2Mask: Local Editing with Dynamic Mask Generation
Recent advancements in generative models have revolutionized image generation and editing, making these tasks accessible to non-experts. This paper focuses on local image editing, particularly the task of adding new content to a loosely specified area. Existing methods often require a precise mask or a detailed description of the location, which can be cumbersome and prone to errors. We propose Click2Mask, a novel approach that simplifies the local editing process by requiring only a single point of reference (in addition to the content description). A mask is dynamically grown around this point during a Blended Latent Diffusion (BLD) process, guided by a masked CLIP-based semantic loss. Click2Mask surpasses the limitations of segmentation-based and fine-tuning dependent methods, offering a more user-friendly and contextually accurate solution. Our experiments demonstrate that Click2Mask not only minimizes user effort but also delivers competitive or superior local image manipulation results compared to SoTA methods, according to both human judgement and automatic metrics. Key contributions include the simplification of user input, the ability to freely add objects unconstrained by existing segments, and the integration potential of our dynamic mask approach within other editing methods.



X-Cross: Dynamic Integration of Language Models for Cross-Domain Sequential Recommendation
As new products are emerging daily, recommendation systems are required to quickly adapt to possible new domains without needing extensive retraining. This work presents ``X-Cross'' -- a novel cross-domain sequential-recommendation model that recommends products in new domains by integrating several domain-specific language models; each model is fine-tuned with low-rank adapters (LoRA). Given a recommendation prompt, operating layer by layer, X-Cross dynamically refines the representation of each source language model by integrating knowledge from all other models. These refined representations are propagated from one layer to the next, leveraging the activations from each domain adapter to ensure domain-specific nuances are preserved while enabling adaptability across domains. Using Amazon datasets for sequential recommendation, X-Cross achieves performance comparable to a model that is fine-tuned with LoRA, while using only 25% of the additional parameters. In cross-domain tasks, such as adapting from Toys domain to Tools, Electronics or Sports, X-Cross demonstrates robust performance, while requiring about 50%-75% less fine-tuning data than LoRA to make fine-tuning effective. Furthermore, X-Cross achieves significant improvement in accuracy over alternative cross-domain baselines. Overall, X-Cross enables scalable and adaptive cross-domain recommendations, reducing computational overhead and providing an efficient solution for data-constrained environments.




Vidu: a Highly Consistent, Dynamic and Skilled Text-to-Video Generator with Diffusion Models
We introduce Vidu, a high-performance text-to-video generator that is capable of producing 1080p videos up to 16 seconds in a single generation. Vidu is a diffusion model with U-ViT as its backbone, which unlocks the scalability and the capability for handling long videos. Vidu exhibits strong coherence and dynamism, and is capable of generating both realistic and imaginative videos, as well as understanding some professional photography techniques, on par with Sora -- the most powerful reported text-to-video generator. Finally, we perform initial experiments on other controllable video generation, including canny-to-video generation, video prediction and subject-driven generation, which demonstrate promising results.




Talk2Event: Grounded Understanding of Dynamic Scenes from Event Cameras
Event cameras offer microsecond-level latency and robustness to motion blur, making them ideal for understanding dynamic environments. Yet, connecting these asynchronous streams to human language remains an open challenge. We introduce Talk2Event, the first large-scale benchmark for language-driven object grounding in event-based perception. Built from real-world driving data, we provide over 30,000 validated referring expressions, each enriched with four grounding attributes -- appearance, status, relation to viewer, and relation to other objects -- bridging spatial, temporal, and relational reasoning. To fully exploit these cues, we propose EventRefer, an attribute-aware grounding framework that dynamically fuses multi-attribute representations through a Mixture of Event-Attribute Experts (MoEE). Our method adapts to different modalities and scene dynamics, achieving consistent gains over state-of-the-art baselines in event-only, frame-only, and event-frame fusion settings. We hope our dataset and approach will establish a foundation for advancing multimodal, temporally-aware, and language-driven perception in real-world robotics and autonomy.


Robust Preference Optimization via Dynamic Target Margins
The alignment of Large Language Models (LLMs) is crucial for ensuring their safety and reliability in practical applications. Direct Preference Optimization (DPO) has emerged as an efficient method that directly optimizes models using preference pairs, significantly reducing resource demands. However, the effectiveness of DPO heavily depends on the data quality, which is frequently compromised by noise. In this work, we propose gamma-PO, a dynamic target margin preference optimization algorithm that adjust reward margins at the pairwise level. By introducing instance-specific margin calibration, gamma-PO strategically prioritizes high-confidence pairs (those demonstrating higher reward margins) while suppressing potential noise from ambiguous pairs. Moreover, gamma-PO is a plug-and-play method, compatible with variants of DPO that rely on reward margin between preference pairs. Across benchmarks such as AlpacaEval2 and Arena-Hard, gamma-PO achieves an average 4.4\% improvement over other baselines, setting new benchmarks for state-of-the-art performance. Additionally, gamma-PO requires minimal code changes and has a negligible impact on training efficiency, making it a robust solution for enhancing LLMs alignment. Our codes are available at https://github.com/sunjie279/gammaPO{https://github.com/sunjie279/gammaPO}.


MaintainCoder: Maintainable Code Generation Under Dynamic Requirements
Modern code generation has made significant strides in functional correctness and execution efficiency. However, these systems often overlook a critical dimension in real-world software development: maintainability. To handle dynamic requirements with minimal rework, we propose MaintainCoder as a pioneering solution. It integrates the Waterfall model, design patterns, and multi-agent collaboration to systematically enhance cohesion, reduce coupling, achieving clear responsibility boundaries and better maintainability. We also introduce MaintainCoder, a benchmark comprising requirement changes and novel dynamic metrics on maintenance efforts. Experiments demonstrate that existing code generation methods struggle to meet maintainability standards when requirements evolve. In contrast, MaintainCoder improves dynamic maintainability metrics by more than 60% with even higher correctness of initial codes. Furthermore, while static metrics fail to accurately reflect maintainability and even contradict each other, our proposed dynamic metrics exhibit high consistency. Our work not only provides the foundation for maintainable code generation, but also highlights the need for more realistic and comprehensive code generation research. Resources: https://github.com/IAAR-Shanghai/MaintainCoder.
Point-DynRF: Point-based Dynamic Radiance Fields from a Monocular Video
Dynamic radiance fields have emerged as a promising approach for generating novel views from a monocular video. However, previous methods enforce the geometric consistency to dynamic radiance fields only between adjacent input frames, making it difficult to represent the global scene geometry and degenerates at the viewpoint that is spatio-temporally distant from the input camera trajectory. To solve this problem, we introduce point-based dynamic radiance fields (Point-DynRF), a novel framework where the global geometric information and the volume rendering process are trained by neural point clouds and dynamic radiance fields, respectively. Specifically, we reconstruct neural point clouds directly from geometric proxies and optimize both radiance fields and the geometric proxies using our proposed losses, allowing them to complement each other. We validate the effectiveness of our method with experiments on the NVIDIA Dynamic Scenes Dataset and several causally captured monocular video clips.

FedDIP: Federated Learning with Extreme Dynamic Pruning and Incremental Regularization
Federated Learning (FL) has been successfully adopted for distributed training and inference of large-scale Deep Neural Networks (DNNs). However, DNNs are characterized by an extremely large number of parameters, thus, yielding significant challenges in exchanging these parameters among distributed nodes and managing the memory. Although recent DNN compression methods (e.g., sparsification, pruning) tackle such challenges, they do not holistically consider an adaptively controlled reduction of parameter exchange while maintaining high accuracy levels. We, therefore, contribute with a novel FL framework (coined FedDIP), which combines (i) dynamic model pruning with error feedback to eliminate redundant information exchange, which contributes to significant performance improvement, with (ii) incremental regularization that can achieve extreme sparsity of models. We provide convergence analysis of FedDIP and report on a comprehensive performance and comparative assessment against state-of-the-art methods using benchmark data sets and DNN models. Our results showcase that FedDIP not only controls the model sparsity but efficiently achieves similar or better performance compared to other model pruning methods adopting incremental regularization during distributed model training. The code is available at: https://github.com/EricLoong/feddip.
DRL-VO: Learning to Navigate Through Crowded Dynamic Scenes Using Velocity Obstacles
This paper proposes a novel learning-based control policy with strong generalizability to new environments that enables a mobile robot to navigate autonomously through spaces filled with both static obstacles and dense crowds of pedestrians. The policy uses a unique combination of input data to generate the desired steering angle and forward velocity: a short history of lidar data, kinematic data about nearby pedestrians, and a sub-goal point. The policy is trained in a reinforcement learning setting using a reward function that contains a novel term based on velocity obstacles to guide the robot to actively avoid pedestrians and move towards the goal. Through a series of 3D simulated experiments with up to 55 pedestrians, this control policy is able to achieve a better balance between collision avoidance and speed (i.e., higher success rate and faster average speed) than state-of-the-art model-based and learning-based policies, and it also generalizes better to different crowd sizes and unseen environments. An extensive series of hardware experiments demonstrate the ability of this policy to directly work in different real-world environments with different crowd sizes with zero retraining. Furthermore, a series of simulated and hardware experiments show that the control policy also works in highly constrained static environments on a different robot platform without any additional training. Lastly, several important lessons that can be applied to other robot learning systems are summarized. Multimedia demonstrations are available at https://www.youtube.com/watch?v=KneELRT8GzU&list=PLouWbAcP4zIvPgaARrV223lf2eiSR-eSS.

Learning Policies for Dynamic Coalition Formation in Multi-Robot Task Allocation
We propose a decentralized, learning-based framework for dynamic coalition formation in Multi-Robot Task Allocation (MRTA). Our approach extends Multi-Agent Proximal Policy Optimization (MAPPO) by integrating spatial action maps, robot motion planning, intention sharing, and task allocation revision to enable effective and adaptive coalition formation. Extensive simulation studies confirm the effectiveness of our model, enabling each robot to rely solely on local information to learn timely revisions of task selections and form coalitions with other robots to complete collaborative tasks. Additionally, our model significantly outperforms existing methods, including a market-based baseline. Furthermore, we evaluate the scalability and generalizability of the proposed framework, highlighting its ability to handle large robot populations and adapt to scenarios featuring diverse task sets.

RCDN: Towards Robust Camera-Insensitivity Collaborative Perception via Dynamic Feature-based 3D Neural Modeling
Collaborative perception is dedicated to tackling the constraints of single-agent perception, such as occlusions, based on the multiple agents' multi-view sensor inputs. However, most existing works assume an ideal condition that all agents' multi-view cameras are continuously available. In reality, cameras may be highly noisy, obscured or even failed during the collaboration. In this work, we introduce a new robust camera-insensitivity problem: how to overcome the issues caused by the failed camera perspectives, while stabilizing high collaborative performance with low calibration cost? To address above problems, we propose RCDN, a Robust Camera-insensitivity collaborative perception with a novel Dynamic feature-based 3D Neural modeling mechanism. The key intuition of RCDN is to construct collaborative neural rendering field representations to recover failed perceptual messages sent by multiple agents. To better model collaborative neural rendering field, RCDN first establishes a geometry BEV feature based time-invariant static field with other agents via fast hash grid modeling. Based on the static background field, the proposed time-varying dynamic field can model corresponding motion vectors for foregrounds with appropriate positions. To validate RCDN, we create OPV2V-N, a new large-scale dataset with manual labelling under different camera failed scenarios. Extensive experiments conducted on OPV2V-N show that RCDN can be ported to other baselines and improve their robustness in extreme camera-insensitivity settings.
Nebula: Self-Attention for Dynamic Malware Analysis
Dynamic analysis enables detecting Windows malware by executing programs in a controlled environment and logging their actions. Previous work has proposed training machine learning models, i.e., convolutional and long short-term memory networks, on homogeneous input features like runtime APIs to either detect or classify malware, neglecting other relevant information coming from heterogeneous data like network and file operations. To overcome these issues, we introduce Nebula, a versatile, self-attention Transformer-based neural architecture that generalizes across different behavioral representations and formats, combining diverse information from dynamic log reports. Nebula is composed by several components needed to tokenize, filter, normalize and encode data to feed the transformer architecture. We firstly perform a comprehensive ablation study to evaluate their impact on the performance of the whole system, highlighting which components can be used as-is, and which must be enriched with specific domain knowledge. We perform extensive experiments on both malware detection and classification tasks, using three datasets acquired from different dynamic analyses platforms, show that, on average, Nebula outperforms state-of-the-art models at low false positive rates, with a peak of 12% improvement. Moreover, we showcase how self-supervised learning pre-training matches the performance of fully-supervised models with only 20% of training data, and we inspect the output of Nebula through explainable AI techniques, pinpointing how attention is focusing on specific tokens correlated to malicious activities of malware families. To foster reproducibility, we open-source our findings and models at https://github.com/dtrizna/nebula.


DTW-SiameseNet: Dynamic Time Warped Siamese Network for Mispronunciation Detection and Correction
Personal Digital Assistants (PDAs) - such as Siri, Alexa and Google Assistant, to name a few - play an increasingly important role to access information and complete tasks spanning multiple domains, and by diverse groups of users. A text-to-speech (TTS) module allows PDAs to interact in a natural, human-like manner, and play a vital role when the interaction involves people with visual impairments or other disabilities. To cater to the needs of a diverse set of users, inclusive TTS is important to recognize and pronounce correctly text in different languages and dialects. Despite great progress in speech synthesis, the pronunciation accuracy of named entities in a multi-lingual setting still has a large room for improvement. Existing approaches to correct named entity (NE) mispronunciations, like retraining Grapheme-to-Phoneme (G2P) models, or maintaining a TTS pronunciation dictionary, require expensive annotation of the ground truth pronunciation, which is also time consuming. In this work, we present a highly-precise, PDA-compatible pronunciation learning framework for the task of TTS mispronunciation detection and correction. In addition, we also propose a novel mispronunciation detection model called DTW-SiameseNet, which employs metric learning with a Siamese architecture for Dynamic Time Warping (DTW) with triplet loss. We demonstrate that a locale-agnostic, privacy-preserving solution to the problem of TTS mispronunciation detection is feasible. We evaluate our approach on a real-world dataset, and a corpus of NE pronunciations of an anonymized audio dataset of person names recorded by participants from 10 different locales. Human evaluation shows our proposed approach improves pronunciation accuracy on average by ~6% compared to strong phoneme-based and audio-based baselines.
Optimistic Planning by Regularized Dynamic Programming
We propose a new method for optimistic planning in infinite-horizon discounted Markov decision processes based on the idea of adding regularization to the updates of an otherwise standard approximate value iteration procedure. This technique allows us to avoid contraction and monotonicity arguments typically required by existing analyses of approximate dynamic programming methods, and in particular to use approximate transition functions estimated via least-squares procedures in MDPs with linear function approximation. We use our method to recover known guarantees in tabular MDPs and to provide a computationally efficient algorithm for learning near-optimal policies in discounted linear mixture MDPs from a single stream of experience, and show it achieves near-optimal statistical guarantees.
GD-VAEs: Geometric Dynamic Variational Autoencoders for Learning Nonlinear Dynamics and Dimension Reductions
We develop data-driven methods incorporating geometric and topological information to learn parsimonious representations of nonlinear dynamics from observations. The approaches learn nonlinear state-space models of the dynamics for general manifold latent spaces using training strategies related to Variational Autoencoders (VAEs). Our methods are referred to as Geometric Dynamic (GD) Variational Autoencoders (GD-VAEs). We learn encoders and decoders for the system states and evolution based on deep neural network architectures that include general Multilayer Perceptrons (MLPs), Convolutional Neural Networks (CNNs), and other architectures. Motivated by problems arising in parameterized PDEs and physics, we investigate the performance of our methods on tasks for learning reduced dimensional representations of the nonlinear Burgers Equations, Constrained Mechanical Systems, and spatial fields of Reaction-Diffusion Systems. GD-VAEs provide methods that can be used to obtain representations in manifold latent spaces for diverse learning tasks involving dynamics.

DynVFX: Augmenting Real Videos with Dynamic Content
We present a method for augmenting real-world videos with newly generated dynamic content. Given an input video and a simple user-provided text instruction describing the desired content, our method synthesizes dynamic objects or complex scene effects that naturally interact with the existing scene over time. The position, appearance, and motion of the new content are seamlessly integrated into the original footage while accounting for camera motion, occlusions, and interactions with other dynamic objects in the scene, resulting in a cohesive and realistic output video. We achieve this via a zero-shot, training-free framework that harnesses a pre-trained text-to-video diffusion transformer to synthesize the new content and a pre-trained Vision Language Model to envision the augmented scene in detail. Specifically, we introduce a novel inference-based method that manipulates features within the attention mechanism, enabling accurate localization and seamless integration of the new content while preserving the integrity of the original scene. Our method is fully automated, requiring only a simple user instruction. We demonstrate its effectiveness on a wide range of edits applied to real-world videos, encompassing diverse objects and scenarios involving both camera and object motion.




V^3: Viewing Volumetric Videos on Mobiles via Streamable 2D Dynamic Gaussians
Experiencing high-fidelity volumetric video as seamlessly as 2D videos is a long-held dream. However, current dynamic 3DGS methods, despite their high rendering quality, face challenges in streaming on mobile devices due to computational and bandwidth constraints. In this paper, we introduce V3(Viewing Volumetric Videos), a novel approach that enables high-quality mobile rendering through the streaming of dynamic Gaussians. Our key innovation is to view dynamic 3DGS as 2D videos, facilitating the use of hardware video codecs. Additionally, we propose a two-stage training strategy to reduce storage requirements with rapid training speed. The first stage employs hash encoding and shallow MLP to learn motion, then reduces the number of Gaussians through pruning to meet the streaming requirements, while the second stage fine tunes other Gaussian attributes using residual entropy loss and temporal loss to improve temporal continuity. This strategy, which disentangles motion and appearance, maintains high rendering quality with compact storage requirements. Meanwhile, we designed a multi-platform player to decode and render 2D Gaussian videos. Extensive experiments demonstrate the effectiveness of V3, outperforming other methods by enabling high-quality rendering and streaming on common devices, which is unseen before. As the first to stream dynamic Gaussians on mobile devices, our companion player offers users an unprecedented volumetric video experience, including smooth scrolling and instant sharing. Our project page with source code is available at https://authoritywang.github.io/v3/.


Retrofitting (Large) Language Models with Dynamic Tokenization
Current language models (LMs) use a fixed, static subword tokenizer. This choice, often taken for granted, typically results in degraded efficiency and capabilities in languages other than English, and makes it challenging to apply LMs to new domains or languages. To address these issues, we propose retrofitting LMs with dynamic tokenization: a way to dynamically decide on token boundaries based on the input text. For encoder-style models, we introduce a subword-merging algorithm inspired by byte-pair encoding (BPE), but at a batch level. We merge frequent subword sequences in a batch, then apply a pretrained embedding-prediction hypernetwork to compute the token embeddings on-the-fly. When applied with word-level boundaries, this on average reduces token sequence lengths by >20% across 14 languages on XNLI with XLM-R while degrading its task performance by less than 2%. For decoder-style models, we apply dynamic tokenization in two ways: 1) for prefilling, maintaining performance of Mistral-7B almost completely with up to 40% sequence reduction - relative to the word-level; and 2) via an approximate nearest neighbor index, achieving fast generation with a one million token vocabulary, demonstrating scalability to even larger, dynamic vocabularies. Overall, our findings show that dynamic tokenization substantially improves inference speed and promotes fairness across languages, making a leap towards overcoming the limitations of static tokenization and enabling more equitable and adaptable LMs.

StreamDiffusionV2: A Streaming System for Dynamic and Interactive Video Generation
Generative models are reshaping the live-streaming industry by redefining how content is created, styled, and delivered. Previous image-based streaming diffusion models have powered efficient and creative live streaming products but have hit limits on temporal consistency due to the foundation of image-based designs. Recent advances in video diffusion have markedly improved temporal consistency and sampling efficiency for offline generation. However, offline generation systems primarily optimize throughput by batching large workloads. In contrast, live online streaming operates under strict service-level objectives (SLOs): time-to-first-frame must be minimal, and every frame must meet a per-frame deadline with low jitter. Besides, scalable multi-GPU serving for real-time streams remains largely unresolved so far. To address this, we present StreamDiffusionV2, a training-free pipeline for interactive live streaming with video diffusion models. StreamDiffusionV2 integrates an SLO-aware batching scheduler and a block scheduler, together with a sink-token--guided rolling KV cache, a motion-aware noise controller, and other system-level optimizations. Moreover, we introduce a scalable pipeline orchestration that parallelizes the diffusion process across denoising steps and network layers, achieving near-linear FPS scaling without violating latency guarantees. The system scales seamlessly across heterogeneous GPU environments and supports flexible denoising steps (e.g., 1--4), enabling both ultra-low-latency and higher-quality modes. Without TensorRT or quantization, StreamDiffusionV2 renders the first frame within 0.5s and attains 58.28 FPS with a 14B-parameter model and 64.52 FPS with a 1.3B-parameter model on four H100 GPUs, making state-of-the-art generative live streaming practical and accessible--from individual creators to enterprise-scale platforms.
Balcony: A Lightweight Approach to Dynamic Inference of Generative Language Models
Deploying large language models (LLMs) in real-world applications is often hindered by strict computational and latency constraints. While dynamic inference offers the flexibility to adjust model behavior based on varying resource budgets, existing methods are frequently limited by hardware inefficiencies or performance degradation. In this paper, we introduce Balcony, a simple yet highly effective framework for depth-based dynamic inference. By freezing the pretrained LLM and inserting additional transformer layers at selected exit points, Balcony maintains the full model's performance while enabling real-time adaptation to different computational budgets. These additional layers are trained using a straightforward self-distillation loss, aligning the sub-model outputs with those of the full model. This approach requires significantly fewer training tokens and tunable parameters, drastically reducing computational costs compared to prior methods. When applied to the LLaMA3-8B model, using only 0.2% of the original pretraining data, Balcony achieves minimal performance degradation while enabling significant speedups. Remarkably, we show that Balcony outperforms state-of-the-art methods such as Flextron and Layerskip as well as other leading compression techniques on multiple models and at various scales, across a variety of benchmarks.

An Efficient 3D Gaussian Representation for Monocular/Multi-view Dynamic Scenes
In novel view synthesis of scenes from multiple input views, 3D Gaussian splatting emerges as a viable alternative to existing radiance field approaches, delivering great visual quality and real-time rendering. While successful in static scenes, the present advancement of 3D Gaussian representation, however, faces challenges in dynamic scenes in terms of memory consumption and the need for numerous observations per time step, due to the onus of storing 3D Gaussian parameters per time step. In this study, we present an efficient 3D Gaussian representation tailored for dynamic scenes in which we define positions and rotations as functions of time while leaving other time-invariant properties of the static 3D Gaussian unchanged. Notably, our representation reduces memory usage, which is consistent regardless of the input sequence length. Additionally, it mitigates the risk of overfitting observed frames by accounting for temporal changes. The optimization of our Gaussian representation based on image and flow reconstruction results in a powerful framework for dynamic scene view synthesis in both monocular and multi-view cases. We obtain the highest rendering speed of 118 frames per second (FPS) at a resolution of 1352 times 1014 with a single GPU, showing the practical usability and effectiveness of our proposed method in dynamic scene rendering scenarios.
DyFraNet: Forecasting and Backcasting Dynamic Fracture Mechanics in Space and Time Using a 2D-to-3D Deep Neural Network
The dynamics of materials failure is one of the most critical phenomena in a range of scientific and engineering fields, from healthcare to structural materials to transportation. In this paper we propose a specially designed deep neural network, DyFraNet, which can predict dynamic fracture behaviors by identifying a complete history of fracture propagation - from cracking onset, as a crack grows through the material, modeled as a series of frames evolving over time and dependent on each other. Furthermore, this model can not only forecast future fracture processes but also backcast to elucidate the past fracture history. In this scenario, once provided with the outcome of a fracture event, the model will elucidate past events that led to this state and will predict the future evolution of the failure process. By comparing the predicted results with atomistic-level simulations and theory, we show that DyFraNet can capture dynamic fracture mechanics by accurately predicting how cracks develop over time, including measures such as the crack speed, as well as when cracks become unstable. We use GradCAM to interpret how DyFraNet perceives the relationship between geometric conditions and fracture dynamics and we find DyFraNet pays special attention to the areas around crack tips, which have a critical influence in the early stage of fracture propagation. In later stages, the model pays increased attention to the existing or newly formed damage distribution in the material. The proposed approach offers significant potential to accelerate the exploration of the dynamics in material design against fracture failures and can be beneficially adapted for all kinds of dynamical engineering problems.
Stochastic Occupancy Grid Map Prediction in Dynamic Scenes
This paper presents two variations of a novel stochastic prediction algorithm that enables mobile robots to accurately and robustly predict the future state of complex dynamic scenes. The proposed algorithm uses a variational autoencoder to predict a range of possible future states of the environment. The algorithm takes full advantage of the motion of the robot itself, the motion of dynamic objects, and the geometry of static objects in the scene to improve prediction accuracy. Three simulated and real-world datasets collected by different robot models are used to demonstrate that the proposed algorithm is able to achieve more accurate and robust prediction performance than other prediction algorithms. Furthermore, a predictive uncertainty-aware planner is proposed to demonstrate the effectiveness of the proposed predictor in simulation and real-world navigation experiments. Implementations are open source at https://github.com/TempleRAIL/SOGMP.
LLM Data Selection and Utilization via Dynamic Bi-level Optimization
While large-scale training data is fundamental for developing capable large language models (LLMs), strategically selecting high-quality data has emerged as a critical approach to enhance training efficiency and reduce computational costs. Current data selection methodologies predominantly rely on static, training-agnostic criteria, failing to account for the dynamic model training and data interactions. In this paper, we propose a new Data Weighting Model (DWM) to adjust the weight of selected data within each batch to achieve a dynamic data utilization during LLM training. Specially, to better capture the dynamic data preference of the trained model, a bi-level optimization framework is implemented to update the weighting model. Our experiments demonstrate that DWM enhances the performance of models trained with randomly-selected data, and the learned weighting model can be transferred to enhance other data selection methods and models of different sizes. Moreover, we further analyze how a model's data preferences evolve throughout training, providing new insights into the data preference of the model during training.
QUEEN: QUantized Efficient ENcoding of Dynamic Gaussians for Streaming Free-viewpoint Videos
Online free-viewpoint video (FVV) streaming is a challenging problem, which is relatively under-explored. It requires incremental on-the-fly updates to a volumetric representation, fast training and rendering to satisfy real-time constraints and a small memory footprint for efficient transmission. If achieved, it can enhance user experience by enabling novel applications, e.g., 3D video conferencing and live volumetric video broadcast, among others. In this work, we propose a novel framework for QUantized and Efficient ENcoding (QUEEN) for streaming FVV using 3D Gaussian Splatting (3D-GS). QUEEN directly learns Gaussian attribute residuals between consecutive frames at each time-step without imposing any structural constraints on them, allowing for high quality reconstruction and generalizability. To efficiently store the residuals, we further propose a quantization-sparsity framework, which contains a learned latent-decoder for effectively quantizing attribute residuals other than Gaussian positions and a learned gating module to sparsify position residuals. We propose to use the Gaussian viewspace gradient difference vector as a signal to separate the static and dynamic content of the scene. It acts as a guide for effective sparsity learning and speeds up training. On diverse FVV benchmarks, QUEEN outperforms the state-of-the-art online FVV methods on all metrics. Notably, for several highly dynamic scenes, it reduces the model size to just 0.7 MB per frame while training in under 5 sec and rendering at 350 FPS. Project website is at https://research.nvidia.com/labs/amri/projects/queen



DGNS: Deformable Gaussian Splatting and Dynamic Neural Surface for Monocular Dynamic 3D Reconstruction
Dynamic scene reconstruction from monocular video is critical for real-world applications. This paper tackles the dual challenges of dynamic novel-view synthesis and 3D geometry reconstruction by introducing a hybrid framework: Deformable Gaussian Splatting and Dynamic Neural Surfaces (DGNS), in which both modules can leverage each other for both tasks. During training, depth maps generated by the deformable Gaussian splatting module guide the ray sampling for faster processing and provide depth supervision within the dynamic neural surface module to improve geometry reconstruction. Simultaneously, the dynamic neural surface directs the distribution of Gaussian primitives around the surface, enhancing rendering quality. To further refine depth supervision, we introduce a depth-filtering process on depth maps derived from Gaussian rasterization. Extensive experiments on public datasets demonstrate that DGNS achieves state-of-the-art performance in both novel-view synthesis and 3D reconstruction.
Generative Camera Dolly: Extreme Monocular Dynamic Novel View Synthesis
Accurate reconstruction of complex dynamic scenes from just a single viewpoint continues to be a challenging task in computer vision. Current dynamic novel view synthesis methods typically require videos from many different camera viewpoints, necessitating careful recording setups, and significantly restricting their utility in the wild as well as in terms of embodied AI applications. In this paper, we propose GCD, a controllable monocular dynamic view synthesis pipeline that leverages large-scale diffusion priors to, given a video of any scene, generate a synchronous video from any other chosen perspective, conditioned on a set of relative camera pose parameters. Our model does not require depth as input, and does not explicitly model 3D scene geometry, instead performing end-to-end video-to-video translation in order to achieve its goal efficiently. Despite being trained on synthetic multi-view video data only, zero-shot real-world generalization experiments show promising results in multiple domains, including robotics, object permanence, and driving environments. We believe our framework can potentially unlock powerful applications in rich dynamic scene understanding, perception for robotics, and interactive 3D video viewing experiences for virtual reality.


Human-Inspired Facial Sketch Synthesis with Dynamic Adaptation
Facial sketch synthesis (FSS) aims to generate a vivid sketch portrait from a given facial photo. Existing FSS methods merely rely on 2D representations of facial semantic or appearance. However, professional human artists usually use outlines or shadings to covey 3D geometry. Thus facial 3D geometry (e.g. depth map) is extremely important for FSS. Besides, different artists may use diverse drawing techniques and create multiple styles of sketches; but the style is globally consistent in a sketch. Inspired by such observations, in this paper, we propose a novel Human-Inspired Dynamic Adaptation (HIDA) method. Specially, we propose to dynamically modulate neuron activations based on a joint consideration of both facial 3D geometry and 2D appearance, as well as globally consistent style control. Besides, we use deformable convolutions at coarse-scales to align deep features, for generating abstract and distinct outlines. Experiments show that HIDA can generate high-quality sketches in multiple styles, and significantly outperforms previous methods, over a large range of challenging faces. Besides, HIDA allows precise style control of the synthesized sketch, and generalizes well to natural scenes and other artistic styles. Our code and results have been released online at: https://github.com/AiArt-HDU/HIDA.
TiDy-PSFs: Computational Imaging with Time-Averaged Dynamic Point-Spread-Functions
Point-spread-function (PSF) engineering is a powerful computational imaging techniques wherein a custom phase mask is integrated into an optical system to encode additional information into captured images. Used in combination with deep learning, such systems now offer state-of-the-art performance at monocular depth estimation, extended depth-of-field imaging, lensless imaging, and other tasks. Inspired by recent advances in spatial light modulator (SLM) technology, this paper answers a natural question: Can one encode additional information and achieve superior performance by changing a phase mask dynamically over time? We first prove that the set of PSFs described by static phase masks is non-convex and that, as a result, time-averaged PSFs generated by dynamic phase masks are fundamentally more expressive. We then demonstrate, in simulation, that time-averaged dynamic (TiDy) phase masks can offer substantially improved monocular depth estimation and extended depth-of-field imaging performance.

Consecutive Question Generation via Dynamic Multitask Learning
In this paper, we propose the task of consecutive question generation (CQG), which generates a set of logically related question-answer pairs to understand a whole passage, with a comprehensive consideration of the aspects including accuracy, coverage, and informativeness. To achieve this, we first examine the four key elements of CQG, i.e., question, answer, rationale, and context history, and propose a novel dynamic multitask framework with one main task generating a question-answer pair, and four auxiliary tasks generating other elements. It directly helps the model generate good questions through both joint training and self-reranking. At the same time, to fully explore the worth-asking information in a given passage, we make use of the reranking losses to sample the rationales and search for the best question series globally. Finally, we measure our strategy by QA data augmentation and manual evaluation, as well as a novel application of generated question-answer pairs on DocNLI. We prove that our strategy can improve question generation significantly and benefit multiple related NLP tasks.

STVGFormer: Spatio-Temporal Video Grounding with Static-Dynamic Cross-Modal Understanding
In this technical report, we introduce our solution to human-centric spatio-temporal video grounding task. We propose a concise and effective framework named STVGFormer, which models spatiotemporal visual-linguistic dependencies with a static branch and a dynamic branch. The static branch performs cross-modal understanding in a single frame and learns to localize the target object spatially according to intra-frame visual cues like object appearances. The dynamic branch performs cross-modal understanding across multiple frames. It learns to predict the starting and ending time of the target moment according to dynamic visual cues like motions. Both the static and dynamic branches are designed as cross-modal transformers. We further design a novel static-dynamic interaction block to enable the static and dynamic branches to transfer useful and complementary information from each other, which is shown to be effective to improve the prediction on hard cases. Our proposed method achieved 39.6% vIoU and won the first place in the HC-STVG track of the 4th Person in Context Challenge.
RWKV-7 "Goose" with Expressive Dynamic State Evolution
We present RWKV-7 "Goose", a new sequence modeling architecture, along with pre-trained language models that establish a new state-of-the-art in downstream performance at the 3 billion parameter scale on multilingual tasks, and match current SoTA English language performance despite being trained on dramatically fewer tokens than other top 3B models. Nevertheless, RWKV-7 models require only constant memory usage and constant inference time per token. RWKV-7 introduces a newly generalized formulation of the delta rule with vector-valued gating and in-context learning rates, as well as a relaxed value replacement rule. We show that RWKV-7 can perform state tracking and recognize all regular languages, while retaining parallelizability of training. This exceeds the capabilities of Transformers under standard complexity conjectures, which are limited to TC^0. To demonstrate RWKV-7's language modeling capability, we also present an extended open source 3.1 trillion token multilingual corpus, and train four RWKV-7 models ranging from 0.19 billion to 2.9 billion parameters on this dataset. To foster openness, reproduction, and adoption, we release our models and dataset component listing at https://huggingface.co/RWKV, and our training and inference code at https://github.com/RWKV/RWKV-LM all under the Apache 2.0 License.




SCOPE: Stochastic Cartographic Occupancy Prediction Engine for Uncertainty-Aware Dynamic Navigation
This article presents a family of Stochastic Cartographic Occupancy Prediction Engines (SCOPEs) that enable mobile robots to predict the future states of complex dynamic environments. They do this by accounting for the motion of the robot itself, the motion of dynamic objects, and the geometry of static objects in the scene, and they generate a range of possible future states of the environment. These prediction engines are software-optimized for real-time performance for navigation in crowded dynamic scenes, achieving up to 89 times faster inference speed and 8 times less memory usage than other state-of-the-art engines. Three simulated and real-world datasets collected by different robot models are used to demonstrate that these proposed prediction algorithms are able to achieve more accurate and robust stochastic prediction performance than other algorithms. Furthermore, a series of simulation and hardware navigation experiments demonstrate that the proposed predictive uncertainty-aware navigation framework with these stochastic prediction engines is able to improve the safe navigation performance of current state-of-the-art model- and learning-based control policies.
The Debate on RLVR Reasoning Capability Boundary: Shrinkage, Expansion, or Both? A Two-Stage Dynamic View
The ongoing debate on whether reinforcement learning with verifiable rewards (RLVR) expands or shrinks the reasoning capabilities of large language models (LLMs) remains unresolved. Some studies contend that RLVR mainly improves sampling efficiency but at the expense of diversity and exploratory capacity, resulting in capability boundary shrinkage. In contrast, others demonstrate that prolonged training can lead to the emergence of novel reasoning strategies, suggesting capability boundary expansion. To reconcile these contradictory findings, we theoretically and empirically show that both perspectives are partially valid-each aligning with a separate phase in an inherent two-stage probability mass dynamic: (1) Exploitation stage: initially, the model primarily samples explored high-reward and low-reward tokens, while rarely selecting the potentially optimal token. Positive advantage estimates increase the probability of high-reward tokens and decrease those of low-reward tokens, yet the optimal token's probability remains largely unchanged during this stage. (2) Exploration stage: as training advances, the growth rate of previously acquired high-reward tokens slows as their probabilities approach saturation. When a potentially optimal token-now receiving positive advantage estimates-is occasionally sampled, its probability increases, while those of the originally high-reward tokens decrease. This dynamic suggests that over-exploitation during the exploitation stage may lead to capability boundary shrinkage, whereas prolonged training into the exploration stage can promote an expansion of the reasoning capability boundary. Building upon our insights, we revisit the potential of only using relative negative gradients for prolonging training, providing a theoretical and empirical foundation for the development of more advanced reasoning capabilities.
Lost & Found: Tracking Changes from Egocentric Observations in 3D Dynamic Scene Graphs
Recent approaches have successfully focused on the segmentation of static reconstructions, thereby equipping downstream applications with semantic 3D understanding. However, the world in which we live is dynamic, characterized by numerous interactions between the environment and humans or robotic agents. Static semantic maps are unable to capture this information, and the naive solution of rescanning the environment after every change is both costly and ineffective in tracking e.g. objects being stored away in drawers. With Lost & Found we present an approach that addresses this limitation. Based solely on egocentric recordings with corresponding hand position and camera pose estimates, we are able to track the 6DoF poses of the moving object within the detected interaction interval. These changes are applied online to a transformable scene graph that captures object-level relations. Compared to state-of-the-art object pose trackers, our approach is more reliable in handling the challenging egocentric viewpoint and the lack of depth information. It outperforms the second-best approach by 34% and 56% for translational and orientational error, respectively, and produces visibly smoother 6DoF object trajectories. In addition, we illustrate how the acquired interaction information in the dynamic scene graph can be employed in the context of robotic applications that would otherwise be unfeasible: We show how our method allows to command a mobile manipulator through teach & repeat, and how information about prior interaction allows a mobile manipulator to retrieve an object hidden in a drawer. Code, videos and corresponding data are accessible at https://behretj.github.io/LostAndFound.

DP-DyLoRA: Fine-Tuning Transformer-Based Models On-Device under Differentially Private Federated Learning using Dynamic Low-Rank Adaptation
Federated learning (FL) allows clients to collaboratively train a global model without sharing their local data with a server. However, clients' contributions to the server can still leak sensitive information. Differential privacy (DP) addresses such leakage by providing formal privacy guarantees, with mechanisms that add randomness to the clients' contributions. The randomness makes it infeasible to train large transformer-based models, common in modern federated learning systems. In this work, we empirically evaluate the practicality of fine-tuning large scale on-device transformer-based models with differential privacy in a federated learning system. We conduct comprehensive experiments on various system properties for tasks spanning a multitude of domains: speech recognition, computer vision (CV) and natural language understanding (NLU). Our results show that full fine-tuning under differentially private federated learning (DP-FL) generally leads to huge performance degradation which can be alleviated by reducing the dimensionality of contributions through parameter-efficient fine-tuning (PEFT). Our benchmarks of existing DP-PEFT methods show that DP-Low-Rank Adaptation (DP-LoRA) consistently outperforms other methods. An even more promising approach, DyLoRA, which makes the low rank variable, when naively combined with FL would straightforwardly break differential privacy. We therefore propose an adaptation method that can be combined with differential privacy and call it DP-DyLoRA. Finally, we are able to reduce the accuracy degradation and word error rate (WER) increase due to DP to less than 2% and 7% respectively with 1 million clients and a stringent privacy budget of ε=2.
Sketching Meets Differential Privacy: Fast Algorithm for Dynamic Kronecker Projection Maintenance
Projection maintenance is one of the core data structure tasks. Efficient data structures for projection maintenance have led to recent breakthroughs in many convex programming algorithms. In this work, we further extend this framework to the Kronecker product structure. Given a constraint matrix {sf A} and a positive semi-definite matrix Win R^{ntimes n} with a sparse eigenbasis, we consider the task of maintaining the projection in the form of {sf B}^top({sf B}{sf B}^top)^{-1}{sf B}, where {sf B}={sf A}(Wotimes I) or {sf B}={sf A}(W^{1/2}otimes W^{1/2}). At each iteration, the weight matrix W receives a low rank change and we receive a new vector h. The goal is to maintain the projection matrix and answer the query {sf B}^top({sf B}{sf B}^top)^{-1}{sf B}h with good approximation guarantees. We design a fast dynamic data structure for this task and it is robust against an adaptive adversary. Following the beautiful and pioneering work of [Beimel, Kaplan, Mansour, Nissim, Saranurak and Stemmer, STOC'22], we use tools from differential privacy to reduce the randomness required by the data structure and further improve the running time.
AdaFocus V2: End-to-End Training of Spatial Dynamic Networks for Video Recognition
Recent works have shown that the computational efficiency of video recognition can be significantly improved by reducing the spatial redundancy. As a representative work, the adaptive focus method (AdaFocus) has achieved a favorable trade-off between accuracy and inference speed by dynamically identifying and attending to the informative regions in each video frame. However, AdaFocus requires a complicated three-stage training pipeline (involving reinforcement learning), leading to slow convergence and is unfriendly to practitioners. This work reformulates the training of AdaFocus as a simple one-stage algorithm by introducing a differentiable interpolation-based patch selection operation, enabling efficient end-to-end optimization. We further present an improved training scheme to address the issues introduced by the one-stage formulation, including the lack of supervision, input diversity and training stability. Moreover, a conditional-exit technique is proposed to perform temporal adaptive computation on top of AdaFocus without additional training. Extensive experiments on six benchmark datasets (i.e., ActivityNet, FCVID, Mini-Kinetics, Something-Something V1&V2, and Jester) demonstrate that our model significantly outperforms the original AdaFocus and other competitive baselines, while being considerably more simple and efficient to train. Code is available at https://github.com/LeapLabTHU/AdaFocusV2.

Efficient neural networks for real-time modeling of analog dynamic range compression
Deep learning approaches have demonstrated success in modeling analog audio effects. Nevertheless, challenges remain in modeling more complex effects that involve time-varying nonlinear elements, such as dynamic range compressors. Existing neural network approaches for modeling compression either ignore the device parameters, do not attain sufficient accuracy, or otherwise require large noncausal models prohibiting real-time operation. In this work, we propose a modification to temporal convolutional networks (TCNs) enabling greater efficiency without sacrificing performance. By utilizing very sparse convolutional kernels through rapidly growing dilations, our model attains a significant receptive field using fewer layers, reducing computation. Through a detailed evaluation we demonstrate our efficient and causal approach achieves state-of-the-art performance in modeling the analog LA-2A, is capable of real-time operation on CPU, and only requires 10 minutes of training data.
Linearly-Recurrent Autoencoder Networks for Learning Dynamics
This paper describes a method for learning low-dimensional approximations of nonlinear dynamical systems, based on neural-network approximations of the underlying Koopman operator. Extended Dynamic Mode Decomposition (EDMD) provides a useful data-driven approximation of the Koopman operator for analyzing dynamical systems. This paper addresses a fundamental problem associated with EDMD: a trade-off between representational capacity of the dictionary and over-fitting due to insufficient data. A new neural network architecture combining an autoencoder with linear recurrent dynamics in the encoded state is used to learn a low-dimensional and highly informative Koopman-invariant subspace of observables. A method is also presented for balanced model reduction of over-specified EDMD systems in feature space. Nonlinear reconstruction using partially linear multi-kernel regression aims to improve reconstruction accuracy from the low-dimensional state when the data has complex but intrinsically low-dimensional structure. The techniques demonstrate the ability to identify Koopman eigenfunctions of the unforced Duffing equation, create accurate low-dimensional models of an unstable cylinder wake flow, and make short-time predictions of the chaotic Kuramoto-Sivashinsky equation.
A Unified Approach for Text- and Image-guided 4D Scene Generation
Large-scale diffusion generative models are greatly simplifying image, video and 3D asset creation from user-provided text prompts and images. However, the challenging problem of text-to-4D dynamic 3D scene generation with diffusion guidance remains largely unexplored. We propose Dream-in-4D, which features a novel two-stage approach for text-to-4D synthesis, leveraging (1) 3D and 2D diffusion guidance to effectively learn a high-quality static 3D asset in the first stage; (2) a deformable neural radiance field that explicitly disentangles the learned static asset from its deformation, preserving quality during motion learning; and (3) a multi-resolution feature grid for the deformation field with a displacement total variation loss to effectively learn motion with video diffusion guidance in the second stage. Through a user preference study, we demonstrate that our approach significantly advances image and motion quality, 3D consistency and text fidelity for text-to-4D generation compared to baseline approaches. Thanks to its motion-disentangled representation, Dream-in-4D can also be easily adapted for controllable generation where appearance is defined by one or multiple images, without the need to modify the motion learning stage. Thus, our method offers, for the first time, a unified approach for text-to-4D, image-to-4D and personalized 4D generation tasks.
Complex-valued neural networks to speed-up MR Thermometry during Hyperthermia using Fourier PD and PDUNet
Hyperthermia (HT) in combination with radio- and/or chemotherapy has become an accepted cancer treatment for distinct solid tumour entities. In HT, tumour tissue is exogenously heated to temperatures between 39 and 43 ^circC for 60 minutes. Temperature monitoring can be performed non-invasively using dynamic magnetic resonance imaging (MRI). However, the slow nature of MRI leads to motion artefacts in the images due to the movements of patients during image acquisition. By discarding parts of the data, the speed of the acquisition can be increased - known as undersampling. However, due to the invalidation of the Nyquist criterion, the acquired images might be blurry and can also produce aliasing artefacts. The aim of this work was, therefore, to reconstruct highly undersampled MR thermometry acquisitions with better resolution and with fewer artefacts compared to conventional methods. The use of deep learning in the medical field has emerged in recent times, and various studies have shown that deep learning has the potential to solve inverse problems such as MR image reconstruction. However, most of the published work only focuses on the magnitude images, while the phase images are ignored, which are fundamental requirements for MR thermometry. This work, for the first time, presents deep learning-based solutions for reconstructing undersampled MR thermometry data. Two different deep learning models have been employed here, the Fourier Primal-Dual network and the Fourier Primal-Dual UNet, to reconstruct highly undersampled complex images of MR thermometry. The method reduced the temperature difference between the undersampled MRIs and the fully sampled MRIs from 1.3 ^circC to 0.6 ^circC in full volume and 0.49 ^circC to 0.06 ^circC in the tumour region for an acceleration factor of 10.

ArtiGrasp: Physically Plausible Synthesis of Bi-Manual Dexterous Grasping and Articulation
We present ArtiGrasp, a novel method to synthesize bi-manual hand-object interactions that include grasping and articulation. This task is challenging due to the diversity of the global wrist motions and the precise finger control that are necessary to articulate objects. ArtiGrasp leverages reinforcement learning and physics simulations to train a policy that controls the global and local hand pose. Our framework unifies grasping and articulation within a single policy guided by a single hand pose reference. Moreover, to facilitate the training of the precise finger control required for articulation, we present a learning curriculum with increasing difficulty. It starts with single-hand manipulation of stationary objects and continues with multi-agent training including both hands and non-stationary objects. To evaluate our method, we introduce Dynamic Object Grasping and Articulation, a task that involves bringing an object into a target articulated pose. This task requires grasping, relocation, and articulation. We show our method's efficacy towards this task. We further demonstrate that our method can generate motions with noisy hand-object pose estimates from an off-the-shelf image-based regressor.

Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-supervised Scene Decomposition
We present Vid2Avatar, a method to learn human avatars from monocular in-the-wild videos. Reconstructing humans that move naturally from monocular in-the-wild videos is difficult. Solving it requires accurately separating humans from arbitrary backgrounds. Moreover, it requires reconstructing detailed 3D surface from short video sequences, making it even more challenging. Despite these challenges, our method does not require any groundtruth supervision or priors extracted from large datasets of clothed human scans, nor do we rely on any external segmentation modules. Instead, it solves the tasks of scene decomposition and surface reconstruction directly in 3D by modeling both the human and the background in the scene jointly, parameterized via two separate neural fields. Specifically, we define a temporally consistent human representation in canonical space and formulate a global optimization over the background model, the canonical human shape and texture, and per-frame human pose parameters. A coarse-to-fine sampling strategy for volume rendering and novel objectives are introduced for a clean separation of dynamic human and static background, yielding detailed and robust 3D human geometry reconstructions. We evaluate our methods on publicly available datasets and show improvements over prior art.
TurtleBench: Evaluating Top Language Models via Real-World Yes/No Puzzles
As the application of Large Language Models (LLMs) expands, the demand for reliable evaluations increases. Existing LLM evaluation benchmarks primarily rely on static datasets, making it challenging to assess model performance in dynamic interactions with users. Moreover, these benchmarks often depend on specific background knowledge, complicating the measurement of a model's logical reasoning capabilities. Other dynamic evaluation methods based on strong models or manual efforts may introduce biases and incur high costs and time demands, hindering large-scale application. To address these issues, we propose TurtleBench. TurtleBench collects real user guesses from our online Turtle Soup Puzzle platform that we developed. This approach allows for the relatively dynamic generation of evaluation datasets, mitigating the risk of model cheating while aligning assessments more closely with genuine user needs for reasoning capabilities, thus enhancing the reliability of evaluations. TurtleBench includes 1,532 user guesses along with the correctness of guesses after annotation. Using this dataset, we thoroughly evaluated nine of the most advanced LLMs available today. Notably, the OpenAI o1 series models did not achieve leading results in these evaluations. We propose several hypotheses for further research, such as "the latent reasoning of o1 utilizes trivial Chain-of-Thought (CoT) techniques" and "increasing CoT length not only provides reasoning benefits but also incurs noise costs."





Optimizing Chain-of-Thought Reasoners via Gradient Variance Minimization in Rejection Sampling and RL
Chain-of-thought (CoT) reasoning in large language models (LLMs) can be formalized as a latent variable problem, where the model needs to generate intermediate reasoning steps. While prior approaches such as iterative reward-ranked fine-tuning (RAFT) have relied on such formulations, they typically apply uniform inference budgets across prompts, which fails to account for variability in difficulty and convergence behavior. This work identifies the main bottleneck in CoT training as inefficient stochastic gradient estimation due to static sampling strategies. We propose GVM-RAFT, a prompt-specific Dynamic Sample Allocation Strategy designed to minimize stochastic gradient variance under a computational budget constraint. The method dynamically allocates computational resources by monitoring prompt acceptance rates and stochastic gradient norms, ensuring that the resulting gradient variance is minimized. Our theoretical analysis shows that the proposed dynamic sampling strategy leads to accelerated convergence guarantees under suitable conditions. Experiments on mathematical reasoning show that GVM-RAFT achieves a 2-4x speedup and considerable accuracy improvements over vanilla RAFT. The proposed dynamic sampling strategy is general and can be incorporated into other reinforcement learning algorithms, such as GRPO, leading to similar improvements in convergence and test accuracy. Our code is available at https://github.com/RLHFlow/GVM.





Deep Time Series Models: A Comprehensive Survey and Benchmark
Time series, characterized by a sequence of data points organized in a discrete-time order, are ubiquitous in real-world scenarios. Unlike other data modalities, time series present unique challenges due to their intricate and dynamic nature, including the entanglement of nonlinear patterns and time-variant trends. Analyzing such data is of great significance in practical applications and has been extensively studied for centuries. Recent years have witnessed remarkable breakthroughs in the time series community, with techniques shifting from traditional statistical methods to contemporary deep learning models. In this paper, we delve into the design of deep time series models across various analysis tasks and review the existing literature from two perspectives: basic modules and model architectures. Further, we develop and release Time Series Library (TSLib) as a fair benchmark of deep time series models for diverse analysis tasks. TSLib implements 30 prominent models, covers 30 datasets from different domains, and supports five prevalent analysis tasks. Based on TSLib, we thoroughly evaluate 13 advanced deep time series models across diverse tasks. Empirical results indicate that models with specific structures are well-suited for distinct analytical tasks, providing insights for research and adoption of deep time series models. Code and datasets are available at https://github.com/thuml/Time-Series-Library.
BrainMAE: A Region-aware Self-supervised Learning Framework for Brain Signals
The human brain is a complex, dynamic network, which is commonly studied using functional magnetic resonance imaging (fMRI) and modeled as network of Regions of interest (ROIs) for understanding various brain functions. Recent studies utilize deep learning approaches to learn the brain network representation based on functional connectivity (FC) profile, broadly falling into two main categories. The Fixed-FC approaches, utilizing the FC profile which represents the linear temporal relation within the brain network, are limited by failing to capture informative brain temporal dynamics. On the other hand, the Dynamic-FC approaches, modeling the evolving FC profile over time, often exhibit less satisfactory performance due to challenges in handling the inherent noisy nature of fMRI data. To address these challenges, we propose Brain Masked Auto-Encoder (BrainMAE) for learning representations directly from fMRI time-series data. Our approach incorporates two essential components: a region-aware graph attention mechanism designed to capture the relationships between different brain ROIs, and a novel self-supervised masked autoencoding framework for effective model pre-training. These components enable the model to capture rich temporal dynamics of brain activity while maintaining resilience to inherent noise in fMRI data. Our experiments demonstrate that BrainMAE consistently outperforms established baseline methods by significant margins in four distinct downstream tasks. Finally, leveraging the model's inherent interpretability, our analysis of model-generated representations reveals findings that resonate with ongoing research in the field of neuroscience.
Anchored Supervised Fine-Tuning
Post-training of large language models involves a fundamental trade-off between supervised fine-tuning (SFT), which efficiently mimics demonstrations but tends to memorize, and reinforcement learning (RL), which achieves better generalization at higher computational cost. Dynamic Fine-Tuning (DFT) recently emerged as a promising middle ground, reweighting SFT objectives with token probabilities and achieving improvements in certain reasoning domains, though it exhibits instability in other tasks. We provide a analysis of DFT through the reward-weighted regression (RWR) framework, revealing that it corresponds to a specific auxiliary distribution choice that yields provably tighter RL bounds than standard SFT. However, our analysis also uncovers a critical limitation: this construction lacks distributional anchoring, leading to progressive drift that undermines training stability. To address this, we propose Anchored Supervised Fine-Tuning (ASFT), which augments DFT's reweighting with lightweight KL regularization to preserve tightness while ensuring stability. Empirically, ASFT consistently outperforms both SFT and DFT across mathematical reasoning, medical knowledge grounding, and code generation, achieving substantial improvements with minimal computational overhead. Our RWR framework provides a systematic lens for understanding post-training methods and demonstrates that principled theoretical analysis leads to both stronger guarantees and practical gains.

EvEnhancer: Empowering Effectiveness, Efficiency and Generalizability for Continuous Space-Time Video Super-Resolution with Events
Continuous space-time video super-resolution (C-STVSR) endeavors to upscale videos simultaneously at arbitrary spatial and temporal scales, which has recently garnered increasing interest. However, prevailing methods struggle to yield satisfactory videos at out-of-distribution spatial and temporal scales. On the other hand, event streams characterized by high temporal resolution and high dynamic range, exhibit compelling promise in vision tasks. This paper presents EvEnhancer, an innovative approach that marries the unique advantages of event streams to elevate effectiveness, efficiency, and generalizability for C-STVSR. Our approach hinges on two pivotal components: 1) Event-adapted synthesis capitalizes on the spatiotemporal correlations between frames and events to discern and learn long-term motion trajectories, enabling the adaptive interpolation and fusion of informative spatiotemporal features; 2) Local implicit video transformer integrates local implicit video neural function with cross-scale spatiotemporal attention to learn continuous video representations utilized to generate plausible videos at arbitrary resolutions and frame rates. Experiments show that EvEnhancer achieves superiority on synthetic and real-world datasets and preferable generalizability on out-of-distribution scales against state-of-the-art methods. Code is available at https://github.com/W-Shuoyan/EvEnhancer.
KARMA: A Multilevel Decomposition Hybrid Mamba Framework for Multivariate Long-Term Time Series Forecasting
Multivariate long-term and efficient time series forecasting is a key requirement for a variety of practical applications, and there are complex interleaving time dynamics in time series data that require decomposition modeling. Traditional time series decomposition methods are single and rely on fixed rules, which are insufficient for mining the potential information of the series and adapting to the dynamic characteristics of complex series. On the other hand, the Transformer-based models for time series forecasting struggle to effectively model long sequences and intricate dynamic relationships due to their high computational complexity. To overcome these limitations, we introduce KARMA, with an Adaptive Time Channel Decomposition module (ATCD) to dynamically extract trend and seasonal components. It further integrates a Hybrid Frequency-Time Decomposition module (HFTD) to further decompose Series into frequency-domain and time-domain. These components are coupled with multi-scale Mamba-based KarmaBlock to efficiently process global and local information in a coordinated manner. Experiments on eight real-world datasets from diverse domains well demonstrated that KARMA significantly outperforms mainstream baseline methods in both predictive accuracy and computational efficiency. Code and full results are available at this repository: https://github.com/yedadasd/KARMA
MC#: Mixture Compressor for Mixture-of-Experts Large Models
Mixture-of-Experts (MoE) effectively scales large language models (LLMs) and vision-language models (VLMs) by increasing capacity through sparse activation. However, preloading all experts into memory and activating multiple experts per input introduces significant computational and memory overhead, making the expert module a major contributor to model size and inference cost. To address this, we propose MC# (Mixture-Compressor-sharp), a framework that combines static quantization and dynamic expert pruning by leveraging the significance of experts and tokens for aggressive compression of MoE-LLMs/VLMs. To reduce storage and loading costs, we introduce Pre-Loading Mixed-Precision Quantization (PMQ), which optimizes bit allocation via linear programming, balancing expert importance and quantization error for a Pareto-optimal trade-off between size and performance. To reduce runtime computation, Online Top-any Pruning (OTP) uses Gumbel-Softmax sampling to dynamically select a subset of experts per token, enabling fine-grained control over activation. By combining PMQ's static bit-width optimization with OTP's dynamic routing, MC# achieves extreme compression with minimal accuracy loss. On DeepSeek-VL2, MC# achieves a 6.2 times weight reduction at 2.57 average bits with only a 1.7% accuracy drop across five multimodal benchmarks. Additionally, OTP reduces expert activation over 20% with less than 1% performance degradation, demonstrating strong potential for efficient MoE-based model deployment.

Pareto Domain Adaptation
Domain adaptation (DA) attempts to transfer the knowledge from a labeled source domain to an unlabeled target domain that follows different distribution from the source. To achieve this, DA methods include a source classification objective to extract the source knowledge and a domain alignment objective to diminish the domain shift, ensuring knowledge transfer. Typically, former DA methods adopt some weight hyper-parameters to linearly combine the training objectives to form an overall objective. However, the gradient directions of these objectives may conflict with each other due to domain shift. Under such circumstances, the linear optimization scheme might decrease the overall objective value at the expense of damaging one of the training objectives, leading to restricted solutions. In this paper, we rethink the optimization scheme for DA from a gradient-based perspective. We propose a Pareto Domain Adaptation (ParetoDA) approach to control the overall optimization direction, aiming to cooperatively optimize all training objectives. Specifically, to reach a desirable solution on the target domain, we design a surrogate loss mimicking target classification. To improve target-prediction accuracy to support the mimicking, we propose a target-prediction refining mechanism which exploits domain labels via Bayes' theorem. On the other hand, since prior knowledge of weighting schemes for objectives is often unavailable to guide optimization to approach the optimal solution on the target domain, we propose a dynamic preference mechanism to dynamically guide our cooperative optimization by the gradient of the surrogate loss on a held-out unlabeled target dataset. Extensive experiments on image classification and semantic segmentation benchmarks demonstrate the effectiveness of ParetoDA
RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking
In various natural language processing tasks, passage retrieval and passage re-ranking are two key procedures in finding and ranking relevant information. Since both the two procedures contribute to the final performance, it is important to jointly optimize them in order to achieve mutual improvement. In this paper, we propose a novel joint training approach for dense passage retrieval and passage re-ranking. A major contribution is that we introduce the dynamic listwise distillation, where we design a unified listwise training approach for both the retriever and the re-ranker. During the dynamic distillation, the retriever and the re-ranker can be adaptively improved according to each other's relevance information. We also propose a hybrid data augmentation strategy to construct diverse training instances for listwise training approach. Extensive experiments show the effectiveness of our approach on both MSMARCO and Natural Questions datasets. Our code is available at https://github.com/PaddlePaddle/RocketQA.
OmniRe: Omni Urban Scene Reconstruction
We introduce OmniRe, a holistic approach for efficiently reconstructing high-fidelity dynamic urban scenes from on-device logs. Recent methods for modeling driving sequences using neural radiance fields or Gaussian Splatting have demonstrated the potential of reconstructing challenging dynamic scenes, but often overlook pedestrians and other non-vehicle dynamic actors, hindering a complete pipeline for dynamic urban scene reconstruction. To that end, we propose a comprehensive 3DGS framework for driving scenes, named OmniRe, that allows for accurate, full-length reconstruction of diverse dynamic objects in a driving log. OmniRe builds dynamic neural scene graphs based on Gaussian representations and constructs multiple local canonical spaces that model various dynamic actors, including vehicles, pedestrians, and cyclists, among many others. This capability is unmatched by existing methods. OmniRe allows us to holistically reconstruct different objects present in the scene, subsequently enabling the simulation of reconstructed scenarios with all actors participating in real-time (~60Hz). Extensive evaluations on the Waymo dataset show that our approach outperforms prior state-of-the-art methods quantitatively and qualitatively by a large margin. We believe our work fills a critical gap in driving reconstruction.


Real-Time Reasoning Agents in Evolving Environments
Agents in the real world must make not only logical but also timely judgments. This requires continuous awareness of the dynamic environment: hazards emerge, opportunities arise, and other agents act, while the agent's reasoning is still unfolding. Despite advances in language model reasoning, existing approaches fail to account for this dynamic nature. We introduce real-time reasoning as a new problem formulation for agents in evolving environments and build Real-Time Reasoning Gym to demonstrate it. We study two paradigms for deploying language models in agents: (1) reactive agents, which employ language models with bounded reasoning computation for rapid responses, and (2) planning agents, which allow extended reasoning computation for complex problems. Our experiments show that even state-of-the-art models struggle with making logical and timely judgments in either paradigm. To address this limitation, we propose AgileThinker, which simultaneously engages both reasoning paradigms. AgileThinker consistently outperforms agents engaging only one reasoning paradigm as the task difficulty and time pressure rise, effectively balancing reasoning depth and response latency. Our work establishes real-time reasoning as a critical testbed for developing practical agents and provides a foundation for research in temporally constrained AI systems, highlighting a path toward real-time capable agents.

Contestable AI needs Computational Argumentation
AI has become pervasive in recent years, but state-of-the-art approaches predominantly neglect the need for AI systems to be contestable. Instead, contestability is advocated by AI guidelines (e.g. by the OECD) and regulation of automated decision-making (e.g. GDPR). In this position paper we explore how contestability can be achieved computationally in and for AI. We argue that contestable AI requires dynamic (human-machine and/or machine-machine) explainability and decision-making processes, whereby machines can (i) interact with humans and/or other machines to progressively explain their outputs and/or their reasoning as well as assess grounds for contestation provided by these humans and/or other machines, and (ii) revise their decision-making processes to redress any issues successfully raised during contestation. Given that much of the current AI landscape is tailored to static AIs, the need to accommodate contestability will require a radical rethinking, that, we argue, computational argumentation is ideally suited to support.
RELAX: Reinforcement Learning Enabled 2D-LiDAR Autonomous System for Parsimonious UAVs
Unmanned Aerial Vehicles (UAVs) have become increasingly prominence in recent years, finding applications in surveillance, package delivery, among many others. Despite considerable efforts in developing algorithms that enable UAVs to navigate through complex unknown environments autonomously, they often require expensive hardware and sensors, such as RGB-D cameras and 3D-LiDAR, leading to a persistent trade-off between performance and cost. To this end, we propose RELAX, a novel end-to-end autonomous framework that is exceptionally cost-efficient, requiring only a single 2D-LiDAR to enable UAVs operating in unknown environments. Specifically, RELAX comprises three components: a pre-processing map constructor; an offline mission planner; and a reinforcement learning (RL)-based online re-planner. Experiments demonstrate that RELAX offers more robust dynamic navigation compared to existing algorithms, while only costing a fraction of the others. The code will be made public upon acceptance.

Efficient Content-Based Sparse Attention with Routing Transformers
Self-attention has recently been adopted for a wide range of sequence modeling problems. Despite its effectiveness, self-attention suffers from quadratic compute and memory requirements with respect to sequence length. Successful approaches to reduce this complexity focused on attending to local sliding windows or a small set of locations independent of content. Our work proposes to learn dynamic sparse attention patterns that avoid allocating computation and memory to attend to content unrelated to the query of interest. This work builds upon two lines of research: it combines the modeling flexibility of prior work on content-based sparse attention with the efficiency gains from approaches based on local, temporal sparse attention. Our model, the Routing Transformer, endows self-attention with a sparse routing module based on online k-means while reducing the overall complexity of attention to Oleft(n^{1.5}dright) from Oleft(n^2dright) for sequence length n and hidden dimension d. We show that our model outperforms comparable sparse attention models on language modeling on Wikitext-103 (15.8 vs 18.3 perplexity) as well as on image generation on ImageNet-64 (3.43 vs 3.44 bits/dim) while using fewer self-attention layers. Additionally, we set a new state-of-the-art on the newly released PG-19 data-set, obtaining a test perplexity of 33.2 with a 22 layer Routing Transformer model trained on sequences of length 8192.

Analysis of Named Entity Recognition and Linking for Tweets
Applying natural language processing for mining and intelligent information access to tweets (a form of microblog) is a challenging, emerging research area. Unlike carefully authored news text and other longer content, tweets pose a number of new challenges, due to their short, noisy, context-dependent, and dynamic nature. Information extraction from tweets is typically performed in a pipeline, comprising consecutive stages of language identification, tokenisation, part-of-speech tagging, named entity recognition and entity disambiguation (e.g. with respect to DBpedia). In this work, we describe a new Twitter entity disambiguation dataset, and conduct an empirical analysis of named entity recognition and disambiguation, investigating how robust a number of state-of-the-art systems are on such noisy texts, what the main sources of error are, and which problems should be further investigated to improve the state of the art.
Learning to Upsample by Learning to Sample
We present DySample, an ultra-lightweight and effective dynamic upsampler. While impressive performance gains have been witnessed from recent kernel-based dynamic upsamplers such as CARAFE, FADE, and SAPA, they introduce much workload, mostly due to the time-consuming dynamic convolution and the additional sub-network used to generate dynamic kernels. Further, the need for high-res feature guidance of FADE and SAPA somehow limits their application scenarios. To address these concerns, we bypass dynamic convolution and formulate upsampling from the perspective of point sampling, which is more resource-efficient and can be easily implemented with the standard built-in function in PyTorch. We first showcase a naive design, and then demonstrate how to strengthen its upsampling behavior step by step towards our new upsampler, DySample. Compared with former kernel-based dynamic upsamplers, DySample requires no customized CUDA package and has much fewer parameters, FLOPs, GPU memory, and latency. Besides the light-weight characteristics, DySample outperforms other upsamplers across five dense prediction tasks, including semantic segmentation, object detection, instance segmentation, panoptic segmentation, and monocular depth estimation. Code is available at https://github.com/tiny-smart/dysample.
Hierarchical Reinforcement Learning for Modeling User Novelty-Seeking Intent in Recommender Systems
Recommending novel content, which expands user horizons by introducing them to new interests, has been shown to improve users' long-term experience on recommendation platforms chen2021values. Users however are not constantly looking to explore novel content. It is therefore crucial to understand their novelty-seeking intent and adjust the recommendation policy accordingly. Most existing literature models a user's propensity to choose novel content or to prefer a more diverse set of recommendations at individual interactions. Hierarchical structure, on the other hand, exists in a user's novelty-seeking intent, which is manifested as a static and intrinsic user preference for seeking novelty along with a dynamic session-based propensity. To this end, we propose a novel hierarchical reinforcement learning-based method to model the hierarchical user novelty-seeking intent, and to adapt the recommendation policy accordingly based on the extracted user novelty-seeking propensity. We further incorporate diversity and novelty-related measurement in the reward function of the hierarchical RL (HRL) agent to encourage user exploration chen2021values. We demonstrate the benefits of explicitly modeling hierarchical user novelty-seeking intent in recommendations through extensive experiments on simulated and real-world datasets. In particular, we demonstrate that the effectiveness of our proposed hierarchical RL-based method lies in its ability to capture such hierarchically-structured intent. As a result, the proposed HRL model achieves superior performance on several public datasets, compared with state-of-art baselines.