Get trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe

Combo: Co-speech holistic 3D human motion generation and efficient customizable adaptation in harmony
In this paper, we propose a novel framework, Combo, for harmonious co-speech holistic 3D human motion generation and efficient customizable adaption. In particular, we identify that one fundamental challenge as the multiple-input-multiple-output (MIMO) nature of the generative model of interest. More concretely, on the input end, the model typically consumes both speech signals and character guidance (e.g., identity and emotion), which not only poses challenge on learning capacity but also hinders further adaptation to varying guidance; on the output end, holistic human motions mainly consist of facial expressions and body movements, which are inherently correlated but non-trivial to coordinate in current data-driven generation process. In response to the above challenge, we propose tailored designs to both ends. For the former, we propose to pre-train on data regarding a fixed identity with neutral emotion, and defer the incorporation of customizable conditions (identity and emotion) to fine-tuning stage, which is boosted by our novel X-Adapter for parameter-efficient fine-tuning. For the latter, we propose a simple yet effective transformer design, DU-Trans, which first divides into two branches to learn individual features of face expression and body movements, and then unites those to learn a joint bi-directional distribution and directly predicts combined coefficients. Evaluated on BEAT2 and SHOW datasets, Combo is highly effective in generating high-quality motions but also efficient in transferring identity and emotion. Project website: https://xc-csc101.github.io/combo/{Combo}.
Kineo: Calibration-Free Metric Motion Capture From Sparse RGB Cameras
Markerless multiview motion capture is often constrained by the need for precise camera calibration, limiting accessibility for non-experts and in-the-wild captures. Existing calibration-free approaches mitigate this requirement but suffer from high computational cost and reduced reconstruction accuracy. We present Kineo, a fully automatic, calibration-free pipeline for markerless motion capture from videos captured by unsynchronized, uncalibrated, consumer-grade RGB cameras. Kineo leverages 2D keypoints from off-the-shelf detectors to simultaneously calibrate cameras, including Brown-Conrady distortion coefficients, and reconstruct 3D keypoints and dense scene point maps at metric scale. A confidence-driven spatio-temporal keypoint sampling strategy, combined with graph-based global optimization, ensures robust calibration at a fixed computational cost independent of sequence length. We further introduce a pairwise reprojection consensus score to quantify 3D reconstruction reliability for downstream tasks. Evaluations on EgoHumans and Human3.6M demonstrate substantial improvements over prior calibration-free methods. Compared to previous state-of-the-art approaches, Kineo reduces camera translation error by approximately 83-85%, camera angular error by 86-92%, and world mean-per-joint error (W-MPJPE) by 83-91%. Kineo is also efficient in real-world scenarios, processing multi-view sequences faster than their duration in specific configuration (e.g., 36min to process 1h20min of footage). The full pipeline and evaluation code are openly released to promote reproducibility and practical adoption at https://liris-xr.github.io/kineo/.
Animus3D: Text-driven 3D Animation via Motion Score Distillation
We present Animus3D, a text-driven 3D animation framework that generates motion field given a static 3D asset and text prompt. Previous methods mostly leverage the vanilla Score Distillation Sampling (SDS) objective to distill motion from pretrained text-to-video diffusion, leading to animations with minimal movement or noticeable jitter. To address this, our approach introduces a novel SDS alternative, Motion Score Distillation (MSD). Specifically, we introduce a LoRA-enhanced video diffusion model that defines a static source distribution rather than pure noise as in SDS, while another inversion-based noise estimation technique ensures appearance preservation when guiding motion. To further improve motion fidelity, we incorporate explicit temporal and spatial regularization terms that mitigate geometric distortions across time and space. Additionally, we propose a motion refinement module to upscale the temporal resolution and enhance fine-grained details, overcoming the fixed-resolution constraints of the underlying video model. Extensive experiments demonstrate that Animus3D successfully animates static 3D assets from diverse text prompts, generating significantly more substantial and detailed motion than state-of-the-art baselines while maintaining high visual integrity. Code will be released at https://qiisun.github.io/animus3d_page.

3D Motion Magnification: Visualizing Subtle Motions with Time Varying Radiance Fields
Motion magnification helps us visualize subtle, imperceptible motion. However, prior methods only work for 2D videos captured with a fixed camera. We present a 3D motion magnification method that can magnify subtle motions from scenes captured by a moving camera, while supporting novel view rendering. We represent the scene with time-varying radiance fields and leverage the Eulerian principle for motion magnification to extract and amplify the variation of the embedding of a fixed point over time. We study and validate our proposed principle for 3D motion magnification using both implicit and tri-plane-based radiance fields as our underlying 3D scene representation. We evaluate the effectiveness of our method on both synthetic and real-world scenes captured under various camera setups.



SpatialTracker: Tracking Any 2D Pixels in 3D Space
Recovering dense and long-range pixel motion in videos is a challenging problem. Part of the difficulty arises from the 3D-to-2D projection process, leading to occlusions and discontinuities in the 2D motion domain. While 2D motion can be intricate, we posit that the underlying 3D motion can often be simple and low-dimensional. In this work, we propose to estimate point trajectories in 3D space to mitigate the issues caused by image projection. Our method, named SpatialTracker, lifts 2D pixels to 3D using monocular depth estimators, represents the 3D content of each frame efficiently using a triplane representation, and performs iterative updates using a transformer to estimate 3D trajectories. Tracking in 3D allows us to leverage as-rigid-as-possible (ARAP) constraints while simultaneously learning a rigidity embedding that clusters pixels into different rigid parts. Extensive evaluation shows that our approach achieves state-of-the-art tracking performance both qualitatively and quantitatively, particularly in challenging scenarios such as out-of-plane rotation.


Motion 3-to-4: 3D Motion Reconstruction for 4D Synthesis
We present Motion 3-to-4, a feed-forward framework for synthesising high-quality 4D dynamic objects from a single monocular video and an optional 3D reference mesh. While recent advances have significantly improved 2D, video, and 3D content generation, 4D synthesis remains difficult due to limited training data and the inherent ambiguity of recovering geometry and motion from a monocular viewpoint. Motion 3-to-4 addresses these challenges by decomposing 4D synthesis into static 3D shape generation and motion reconstruction. Using a canonical reference mesh, our model learns a compact motion latent representation and predicts per-frame vertex trajectories to recover complete, temporally coherent geometry. A scalable frame-wise transformer further enables robustness to varying sequence lengths. Evaluations on both standard benchmarks and a new dataset with accurate ground-truth geometry show that Motion 3-to-4 delivers superior fidelity and spatial consistency compared to prior work. Project page is available at https://motion3-to-4.github.io/.
Motion-2-to-3: Leveraging 2D Motion Data to Boost 3D Motion Generation
Text-driven human motion synthesis is capturing significant attention for its ability to effortlessly generate intricate movements from abstract text cues, showcasing its potential for revolutionizing motion design not only in film narratives but also in virtual reality experiences and computer game development. Existing methods often rely on 3D motion capture data, which require special setups resulting in higher costs for data acquisition, ultimately limiting the diversity and scope of human motion. In contrast, 2D human videos offer a vast and accessible source of motion data, covering a wider range of styles and activities. In this paper, we explore leveraging 2D human motion extracted from videos as an alternative data source to improve text-driven 3D motion generation. Our approach introduces a novel framework that disentangles local joint motion from global movements, enabling efficient learning of local motion priors from 2D data. We first train a single-view 2D local motion generator on a large dataset of text-motion pairs. To enhance this model to synthesize 3D motion, we fine-tune the generator with 3D data, transforming it into a multi-view generator that predicts view-consistent local joint motion and root dynamics. Experiments on the HumanML3D dataset and novel text prompts demonstrate that our method efficiently utilizes 2D data, supporting realistic 3D human motion generation and broadening the range of motion types it supports. Our code will be made publicly available at https://zju3dv.github.io/Motion-2-to-3/.

Splatter a Video: Video Gaussian Representation for Versatile Processing
Video representation is a long-standing problem that is crucial for various down-stream tasks, such as tracking,depth prediction,segmentation,view synthesis,and editing. However, current methods either struggle to model complex motions due to the absence of 3D structure or rely on implicit 3D representations that are ill-suited for manipulation tasks. To address these challenges, we introduce a novel explicit 3D representation-video Gaussian representation -- that embeds a video into 3D Gaussians. Our proposed representation models video appearance in a 3D canonical space using explicit Gaussians as proxies and associates each Gaussian with 3D motions for video motion. This approach offers a more intrinsic and explicit representation than layered atlas or volumetric pixel matrices. To obtain such a representation, we distill 2D priors, such as optical flow and depth, from foundation models to regularize learning in this ill-posed setting. Extensive applications demonstrate the versatility of our new video representation. It has been proven effective in numerous video processing tasks, including tracking, consistent video depth and feature refinement, motion and appearance editing, and stereoscopic video generation. Project page: https://sunyangtian.github.io/spatter_a_video_web/

Diffusion4D: Fast Spatial-temporal Consistent 4D Generation via Video Diffusion Models
The availability of large-scale multimodal datasets and advancements in diffusion models have significantly accelerated progress in 4D content generation. Most prior approaches rely on multiple image or video diffusion models, utilizing score distillation sampling for optimization or generating pseudo novel views for direct supervision. However, these methods are hindered by slow optimization speeds and multi-view inconsistency issues. Spatial and temporal consistency in 4D geometry has been extensively explored respectively in 3D-aware diffusion models and traditional monocular video diffusion models. Building on this foundation, we propose a strategy to migrate the temporal consistency in video diffusion models to the spatial-temporal consistency required for 4D generation. Specifically, we present a novel framework, Diffusion4D, for efficient and scalable 4D content generation. Leveraging a meticulously curated dynamic 3D dataset, we develop a 4D-aware video diffusion model capable of synthesizing orbital views of dynamic 3D assets. To control the dynamic strength of these assets, we introduce a 3D-to-4D motion magnitude metric as guidance. Additionally, we propose a novel motion magnitude reconstruction loss and 3D-aware classifier-free guidance to refine the learning and generation of motion dynamics. After obtaining orbital views of the 4D asset, we perform explicit 4D construction with Gaussian splatting in a coarse-to-fine manner. The synthesized multi-view consistent 4D image set enables us to swiftly generate high-fidelity and diverse 4D assets within just several minutes. Extensive experiments demonstrate that our method surpasses prior state-of-the-art techniques in terms of generation efficiency and 4D geometry consistency across various prompt modalities.


Animate3D: Animating Any 3D Model with Multi-view Video Diffusion
Recent advances in 4D generation mainly focus on generating 4D content by distilling pre-trained text or single-view image-conditioned models. It is inconvenient for them to take advantage of various off-the-shelf 3D assets with multi-view attributes, and their results suffer from spatiotemporal inconsistency owing to the inherent ambiguity in the supervision signals. In this work, we present Animate3D, a novel framework for animating any static 3D model. The core idea is two-fold: 1) We propose a novel multi-view video diffusion model (MV-VDM) conditioned on multi-view renderings of the static 3D object, which is trained on our presented large-scale multi-view video dataset (MV-Video). 2) Based on MV-VDM, we introduce a framework combining reconstruction and 4D Score Distillation Sampling (4D-SDS) to leverage the multi-view video diffusion priors for animating 3D objects. Specifically, for MV-VDM, we design a new spatiotemporal attention module to enhance spatial and temporal consistency by integrating 3D and video diffusion models. Additionally, we leverage the static 3D model's multi-view renderings as conditions to preserve its identity. For animating 3D models, an effective two-stage pipeline is proposed: we first reconstruct motions directly from generated multi-view videos, followed by the introduced 4D-SDS to refine both appearance and motion. Qualitative and quantitative experiments demonstrate that Animate3D significantly outperforms previous approaches. Data, code, and models will be open-released.

MotionFix: Text-Driven 3D Human Motion Editing
The focus of this paper is on 3D motion editing. Given a 3D human motion and a textual description of the desired modification, our goal is to generate an edited motion as described by the text. The key challenges include the scarcity of training data and the need to design a model that accurately edits the source motion. In this paper, we address both challenges. We propose a methodology to semi-automatically collect a dataset of triplets comprising (i) a source motion, (ii) a target motion, and (iii) an edit text, introducing the new MotionFix dataset. Access to this data allows us to train a conditional diffusion model, TMED, that takes both the source motion and the edit text as input. We develop several baselines to evaluate our model, comparing it against models trained solely on text-motion pair datasets, and demonstrate the superior performance of our model trained on triplets. We also introduce new retrieval-based metrics for motion editing, establishing a benchmark on the evaluation set of MotionFix. Our results are promising, paving the way for further research in fine-grained motion generation. Code, models, and data are available at https://motionfix.is.tue.mpg.de/ .
Unsupervised Learning of Long-Term Motion Dynamics for Videos
We present an unsupervised representation learning approach that compactly encodes the motion dependencies in videos. Given a pair of images from a video clip, our framework learns to predict the long-term 3D motions. To reduce the complexity of the learning framework, we propose to describe the motion as a sequence of atomic 3D flows computed with RGB-D modality. We use a Recurrent Neural Network based Encoder-Decoder framework to predict these sequences of flows. We argue that in order for the decoder to reconstruct these sequences, the encoder must learn a robust video representation that captures long-term motion dependencies and spatial-temporal relations. We demonstrate the effectiveness of our learned temporal representations on activity classification across multiple modalities and datasets such as NTU RGB+D and MSR Daily Activity 3D. Our framework is generic to any input modality, i.e., RGB, Depth, and RGB-D videos.
DELTA: Dense Efficient Long-range 3D Tracking for any video
Tracking dense 3D motion from monocular videos remains challenging, particularly when aiming for pixel-level precision over long sequences. We introduce \Approach, a novel method that efficiently tracks every pixel in 3D space, enabling accurate motion estimation across entire videos. Our approach leverages a joint global-local attention mechanism for reduced-resolution tracking, followed by a transformer-based upsampler to achieve high-resolution predictions. Unlike existing methods, which are limited by computational inefficiency or sparse tracking, \Approach delivers dense 3D tracking at scale, running over 8x faster than previous methods while achieving state-of-the-art accuracy. Furthermore, we explore the impact of depth representation on tracking performance and identify log-depth as the optimal choice. Extensive experiments demonstrate the superiority of \Approach on multiple benchmarks, achieving new state-of-the-art results in both 2D and 3D dense tracking tasks. Our method provides a robust solution for applications requiring fine-grained, long-term motion tracking in 3D space.
V3D: Video Diffusion Models are Effective 3D Generators
Automatic 3D generation has recently attracted widespread attention. Recent methods have greatly accelerated the generation speed, but usually produce less-detailed objects due to limited model capacity or 3D data. Motivated by recent advancements in video diffusion models, we introduce V3D, which leverages the world simulation capacity of pre-trained video diffusion models to facilitate 3D generation. To fully unleash the potential of video diffusion to perceive the 3D world, we further introduce geometrical consistency prior and extend the video diffusion model to a multi-view consistent 3D generator. Benefiting from this, the state-of-the-art video diffusion model could be fine-tuned to generate 360degree orbit frames surrounding an object given a single image. With our tailored reconstruction pipelines, we can generate high-quality meshes or 3D Gaussians within 3 minutes. Furthermore, our method can be extended to scene-level novel view synthesis, achieving precise control over the camera path with sparse input views. Extensive experiments demonstrate the superior performance of the proposed approach, especially in terms of generation quality and multi-view consistency. Our code is available at https://github.com/heheyas/V3D




Physics3D: Learning Physical Properties of 3D Gaussians via Video Diffusion
In recent years, there has been rapid development in 3D generation models, opening up new possibilities for applications such as simulating the dynamic movements of 3D objects and customizing their behaviors. However, current 3D generative models tend to focus only on surface features such as color and shape, neglecting the inherent physical properties that govern the behavior of objects in the real world. To accurately simulate physics-aligned dynamics, it is essential to predict the physical properties of materials and incorporate them into the behavior prediction process. Nonetheless, predicting the diverse materials of real-world objects is still challenging due to the complex nature of their physical attributes. In this paper, we propose Physics3D, a novel method for learning various physical properties of 3D objects through a video diffusion model. Our approach involves designing a highly generalizable physical simulation system based on a viscoelastic material model, which enables us to simulate a wide range of materials with high-fidelity capabilities. Moreover, we distill the physical priors from a video diffusion model that contains more understanding of realistic object materials. Extensive experiments demonstrate the effectiveness of our method with both elastic and plastic materials. Physics3D shows great potential for bridging the gap between the physical world and virtual neural space, providing a better integration and application of realistic physical principles in virtual environments. Project page: https://liuff19.github.io/Physics3D.




AnimaX: Animating the Inanimate in 3D with Joint Video-Pose Diffusion Models
We present AnimaX, a feed-forward 3D animation framework that bridges the motion priors of video diffusion models with the controllable structure of skeleton-based animation. Traditional motion synthesis methods are either restricted to fixed skeletal topologies or require costly optimization in high-dimensional deformation spaces. In contrast, AnimaX effectively transfers video-based motion knowledge to the 3D domain, supporting diverse articulated meshes with arbitrary skeletons. Our method represents 3D motion as multi-view, multi-frame 2D pose maps, and enables joint video-pose diffusion conditioned on template renderings and a textual motion prompt. We introduce shared positional encodings and modality-aware embeddings to ensure spatial-temporal alignment between video and pose sequences, effectively transferring video priors to motion generation task. The resulting multi-view pose sequences are triangulated into 3D joint positions and converted into mesh animation via inverse kinematics. Trained on a newly curated dataset of 160,000 rigged sequences, AnimaX achieves state-of-the-art results on VBench in generalization, motion fidelity, and efficiency, offering a scalable solution for category-agnostic 3D animation. Project page: https://anima-x.github.io/{https://anima-x.github.io/}.





SyncMV4D: Synchronized Multi-view Joint Diffusion of Appearance and Motion for Hand-Object Interaction Synthesis
Hand-Object Interaction (HOI) generation plays a critical role in advancing applications across animation and robotics. Current video-based methods are predominantly single-view, which impedes comprehensive 3D geometry perception and often results in geometric distortions or unrealistic motion patterns. While 3D HOI approaches can generate dynamically plausible motions, their dependence on high-quality 3D data captured in controlled laboratory settings severely limits their generalization to real-world scenarios. To overcome these limitations, we introduce SyncMV4D, the first model that jointly generates synchronized multi-view HOI videos and 4D motions by unifying visual prior, motion dynamics, and multi-view geometry. Our framework features two core innovations: (1) a Multi-view Joint Diffusion (MJD) model that co-generates HOI videos and intermediate motions, and (2) a Diffusion Points Aligner (DPA) that refines the coarse intermediate motion into globally aligned 4D metric point tracks. To tightly couple 2D appearance with 4D dynamics, we establish a closed-loop, mutually enhancing cycle. During the diffusion denoising process, the generated video conditions the refinement of the 4D motion, while the aligned 4D point tracks are reprojected to guide next-step joint generation. Experimentally, our method demonstrates superior performance to state-of-the-art alternatives in visual realism, motion plausibility, and multi-view consistency.



A Third-Order Gaussian Process Trajectory Representation Framework with Closed-Form Kinematics for Continuous-Time Motion Estimation
In this paper, we propose a third-order, i.e., white-noise-on-jerk, Gaussian Process (GP) Trajectory Representation (TR) framework for continuous-time (CT) motion estimation (ME) tasks. Our framework features a unified trajectory representation that encapsulates the kinematic models of both SO(3)timesR^3 and SE(3) pose representations. This encapsulation strategy allows users to use the same implementation of measurement-based factors for either choice of pose representation, which facilitates experimentation and comparison to achieve the best model for the ME task. In addition, unique to our framework, we derive the kinematic models with the closed-form temporal derivatives of the local variable of SO(3) and SE(3), which so far has only been approximated based on the Taylor expansion in the literature. Our experiments show that these kinematic models can improve the estimation accuracy in high-speed scenarios. All analytical Jacobians of the interpolated states with respect to the support states of the trajectory representation, as well as the motion prior factors, are also provided for accelerated Gauss-Newton (GN) optimization. Our experiments demonstrate the efficacy and efficiency of the framework in various motion estimation tasks such as localization, calibration, and odometry, facilitating fast prototyping for ME researchers. We release the source code for the benefit of the community. Our project is available at https://github.com/brytsknguyen/gptr.
TC4D: Trajectory-Conditioned Text-to-4D Generation
Recent techniques for text-to-4D generation synthesize dynamic 3D scenes using supervision from pre-trained text-to-video models. However, existing representations for motion, such as deformation models or time-dependent neural representations, are limited in the amount of motion they can generate-they cannot synthesize motion extending far beyond the bounding box used for volume rendering. The lack of a more flexible motion model contributes to the gap in realism between 4D generation methods and recent, near-photorealistic video generation models. Here, we propose TC4D: trajectory-conditioned text-to-4D generation, which factors motion into global and local components. We represent the global motion of a scene's bounding box using rigid transformation along a trajectory parameterized by a spline. We learn local deformations that conform to the global trajectory using supervision from a text-to-video model. Our approach enables the synthesis of scenes animated along arbitrary trajectories, compositional scene generation, and significant improvements to the realism and amount of generated motion, which we evaluate qualitatively and through a user study. Video results can be viewed on our website: https://sherwinbahmani.github.io/tc4d.





Animate124: Animating One Image to 4D Dynamic Scene
We introduce Animate124 (Animate-one-image-to-4D), the first work to animate a single in-the-wild image into 3D video through textual motion descriptions, an underexplored problem with significant applications. Our 4D generation leverages an advanced 4D grid dynamic Neural Radiance Field (NeRF) model, optimized in three distinct stages using multiple diffusion priors. Initially, a static model is optimized using the reference image, guided by 2D and 3D diffusion priors, which serves as the initialization for the dynamic NeRF. Subsequently, a video diffusion model is employed to learn the motion specific to the subject. However, the object in the 3D videos tends to drift away from the reference image over time. This drift is mainly due to the misalignment between the text prompt and the reference image in the video diffusion model. In the final stage, a personalized diffusion prior is therefore utilized to address the semantic drift. As the pioneering image-text-to-4D generation framework, our method demonstrates significant advancements over existing baselines, evidenced by comprehensive quantitative and qualitative assessments.

Learning an Implicit Physics Model for Image-based Fluid Simulation
Humans possess an exceptional ability to imagine 4D scenes, encompassing both motion and 3D geometry, from a single still image. This ability is rooted in our accumulated observations of similar scenes and an intuitive understanding of physics. In this paper, we aim to replicate this capacity in neural networks, specifically focusing on natural fluid imagery. Existing methods for this task typically employ simplistic 2D motion estimators to animate the image, leading to motion predictions that often defy physical principles, resulting in unrealistic animations. Our approach introduces a novel method for generating 4D scenes with physics-consistent animation from a single image. We propose the use of a physics-informed neural network that predicts motion for each surface point, guided by a loss term derived from fundamental physical principles, including the Navier-Stokes equations. To capture appearance, we predict feature-based 3D Gaussians from the input image and its estimated depth, which are then animated using the predicted motions and rendered from any desired camera perspective. Experimental results highlight the effectiveness of our method in producing physically plausible animations, showcasing significant performance improvements over existing methods. Our project page is https://physfluid.github.io/ .
Generalizable Implicit Motion Modeling for Video Frame Interpolation
Motion modeling is critical in flow-based Video Frame Interpolation (VFI). Existing paradigms either consider linear combinations of bidirectional flows or directly predict bilateral flows for given timestamps without exploring favorable motion priors, thus lacking the capability of effectively modeling spatiotemporal dynamics in real-world videos. To address this limitation, in this study, we introduce Generalizable Implicit Motion Modeling (GIMM), a novel and effective approach to motion modeling for VFI. Specifically, to enable GIMM as an effective motion modeling paradigm, we design a motion encoding pipeline to model spatiotemporal motion latent from bidirectional flows extracted from pre-trained flow estimators, effectively representing input-specific motion priors. Then, we implicitly predict arbitrary-timestep optical flows within two adjacent input frames via an adaptive coordinate-based neural network, with spatiotemporal coordinates and motion latent as inputs. Our GIMM can be smoothly integrated with existing flow-based VFI works without further modifications. We show that GIMM performs better than the current state of the art on the VFI benchmarks.

NVFi: Neural Velocity Fields for 3D Physics Learning from Dynamic Videos
In this paper, we aim to model 3D scene dynamics from multi-view videos. Unlike the majority of existing works which usually focus on the common task of novel view synthesis within the training time period, we propose to simultaneously learn the geometry, appearance, and physical velocity of 3D scenes only from video frames, such that multiple desirable applications can be supported, including future frame extrapolation, unsupervised 3D semantic scene decomposition, and dynamic motion transfer. Our method consists of three major components, 1) the keyframe dynamic radiance field, 2) the interframe velocity field, and 3) a joint keyframe and interframe optimization module which is the core of our framework to effectively train both networks. To validate our method, we further introduce two dynamic 3D datasets: 1) Dynamic Object dataset, and 2) Dynamic Indoor Scene dataset. We conduct extensive experiments on multiple datasets, demonstrating the superior performance of our method over all baselines, particularly in the critical tasks of future frame extrapolation and unsupervised 3D semantic scene decomposition.
Stereo4D: Learning How Things Move in 3D from Internet Stereo Videos
Learning to understand dynamic 3D scenes from imagery is crucial for applications ranging from robotics to scene reconstruction. Yet, unlike other problems where large-scale supervised training has enabled rapid progress, directly supervising methods for recovering 3D motion remains challenging due to the fundamental difficulty of obtaining ground truth annotations. We present a system for mining high-quality 4D reconstructions from internet stereoscopic, wide-angle videos. Our system fuses and filters the outputs of camera pose estimation, stereo depth estimation, and temporal tracking methods into high-quality dynamic 3D reconstructions. We use this method to generate large-scale data in the form of world-consistent, pseudo-metric 3D point clouds with long-term motion trajectories. We demonstrate the utility of this data by training a variant of DUSt3R to predict structure and 3D motion from real-world image pairs, showing that training on our reconstructed data enables generalization to diverse real-world scenes. Project page: https://stereo4d.github.io

MotionTTT: 2D Test-Time-Training Motion Estimation for 3D Motion Corrected MRI
A major challenge of the long measurement times in magnetic resonance imaging (MRI), an important medical imaging technology, is that patients may move during data acquisition. This leads to severe motion artifacts in the reconstructed images and volumes. In this paper, we propose a deep learning-based test-time-training method for accurate motion estimation. The key idea is that a neural network trained for motion-free reconstruction has a small loss if there is no motion, thus optimizing over motion parameters passed through the reconstruction network enables accurate estimation of motion. The estimated motion parameters enable to correct for the motion and to reconstruct accurate motion-corrected images. Our method uses 2D reconstruction networks to estimate rigid motion in 3D, and constitutes the first deep learning based method for 3D rigid motion estimation towards 3D-motion-corrected MRI. We show that our method can provably reconstruct motion parameters for a simple signal and neural network model. We demonstrate the effectiveness of our method for both retrospectively simulated motion and prospectively collected real motion-corrupted data.

DreamPhysics: Learning Physics-Based 3D Dynamics with Video Diffusion Priors
Dynamic 3D interaction has been attracting a lot of attention recently. However, creating such 4D content remains challenging. One solution is to animate 3D scenes with physics-based simulation, which requires manually assigning precise physical properties to the object or the simulated results would become unnatural. Another solution is to learn the deformation of 3D objects with the distillation of video generative models, which, however, tends to produce 3D videos with small and discontinuous motions due to the inappropriate extraction and application of physics priors. In this work, to combine the strengths and complementing shortcomings of the above two solutions, we propose to learn the physical properties of a material field with video diffusion priors, and then utilize a physics-based Material-Point-Method (MPM) simulator to generate 4D content with realistic motions. In particular, we propose motion distillation sampling to emphasize video motion information during distillation. In addition, to facilitate the optimization, we further propose a KAN-based material field with frame boosting. Experimental results demonstrate that our method enjoys more realistic motions than state-of-the-arts do.


World-Grounded Human Motion Recovery via Gravity-View Coordinates
We present a novel method for recovering world-grounded human motion from monocular video. The main challenge lies in the ambiguity of defining the world coordinate system, which varies between sequences. Previous approaches attempt to alleviate this issue by predicting relative motion in an autoregressive manner, but are prone to accumulating errors. Instead, we propose estimating human poses in a novel Gravity-View (GV) coordinate system, which is defined by the world gravity and the camera view direction. The proposed GV system is naturally gravity-aligned and uniquely defined for each video frame, largely reducing the ambiguity of learning image-pose mapping. The estimated poses can be transformed back to the world coordinate system using camera rotations, forming a global motion sequence. Additionally, the per-frame estimation avoids error accumulation in the autoregressive methods. Experiments on in-the-wild benchmarks demonstrate that our method recovers more realistic motion in both the camera space and world-grounded settings, outperforming state-of-the-art methods in both accuracy and speed. The code is available at https://zju3dv.github.io/gvhmr/.

Learning Implicit Representation for Reconstructing Articulated Objects
3D Reconstruction of moving articulated objects without additional information about object structure is a challenging problem. Current methods overcome such challenges by employing category-specific skeletal models. Consequently, they do not generalize well to articulated objects in the wild. We treat an articulated object as an unknown, semi-rigid skeletal structure surrounded by nonrigid material (e.g., skin). Our method simultaneously estimates the visible (explicit) representation (3D shapes, colors, camera parameters) and the implicit skeletal representation, from motion cues in the object video without 3D supervision. Our implicit representation consists of four parts. (1) Skeleton, which specifies how semi-rigid parts are connected. (2) black{Skinning Weights}, which associates each surface vertex with semi-rigid parts with probability. (3) Rigidity Coefficients, specifying the articulation of the local surface. (4) Time-Varying Transformations, which specify the skeletal motion and surface deformation parameters. We introduce an algorithm that uses physical constraints as regularization terms and iteratively estimates both implicit and explicit representations. Our method is category-agnostic, thus eliminating the need for category-specific skeletons, we show that our method outperforms state-of-the-art across standard video datasets.


In-2-4D: Inbetweening from Two Single-View Images to 4D Generation
We propose a new problem, In-2-4D, for generative 4D (i.e., 3D + motion) inbetweening from a minimalistic input setting: two single-view images capturing an object in two distinct motion states. Given two images representing the start and end states of an object in motion, our goal is to generate and reconstruct the motion in 4D. We utilize a video interpolation model to predict the motion, but large frame-to-frame motions can lead to ambiguous interpretations. To overcome this, we employ a hierarchical approach to identify keyframes that are visually close to the input states and show significant motion, then generate smooth fragments between them. For each fragment, we construct the 3D representation of the keyframe using Gaussian Splatting. The temporal frames within the fragment guide the motion, enabling their transformation into dynamic Gaussians through a deformation field. To improve temporal consistency and refine 3D motion, we expand the self-attention of multi-view diffusion across timesteps and apply rigid transformation regularization. Finally, we merge the independently generated 3D motion segments by interpolating boundary deformation fields and optimizing them to align with the guiding video, ensuring smooth and flicker-free transitions. Through extensive qualitative and quantitiave experiments as well as a user study, we show the effectiveness of our method and its components. The project page is available at https://in-2-4d.github.io/
Pixel-to-4D: Camera-Controlled Image-to-Video Generation with Dynamic 3D Gaussians
Humans excel at forecasting the future dynamics of a scene given just a single image. Video generation models that can mimic this ability are an essential component for intelligent systems. Recent approaches have improved temporal coherence and 3D consistency in single-image-conditioned video generation. However, these methods often lack robust user controllability, such as modifying the camera path, limiting their applicability in real-world applications. Most existing camera-controlled image-to-video models struggle with accurately modeling camera motion, maintaining temporal consistency, and preserving geometric integrity. Leveraging explicit intermediate 3D representations offers a promising solution by enabling coherent video generation aligned with a given camera trajectory. Although these methods often use 3D point clouds to render scenes and introduce object motion in a later stage, this two-step process still falls short in achieving full temporal consistency, despite allowing precise control over camera movement. We propose a novel framework that constructs a 3D Gaussian scene representation and samples plausible object motion, given a single image in a single forward pass. This enables fast, camera-guided video generation without the need for iterative denoising to inject object motion into render frames. Extensive experiments on the KITTI, Waymo, RealEstate10K and DL3DV-10K datasets demonstrate that our method achieves state-of-the-art video quality and inference efficiency. The project page is available at https://melonienimasha.github.io/Pixel-to-4D-Website.
Decaf: Monocular Deformation Capture for Face and Hand Interactions
Existing methods for 3D tracking from monocular RGB videos predominantly consider articulated and rigid objects. Modelling dense non-rigid object deformations in this setting remained largely unaddressed so far, although such effects can improve the realism of the downstream applications such as AR/VR and avatar communications. This is due to the severe ill-posedness of the monocular view setting and the associated challenges. While it is possible to naively track multiple non-rigid objects independently using 3D templates or parametric 3D models, such an approach would suffer from multiple artefacts in the resulting 3D estimates such as depth ambiguity, unnatural intra-object collisions and missing or implausible deformations. Hence, this paper introduces the first method that addresses the fundamental challenges depicted above and that allows tracking human hands interacting with human faces in 3D from single monocular RGB videos. We model hands as articulated objects inducing non-rigid face deformations during an active interaction. Our method relies on a new hand-face motion and interaction capture dataset with realistic face deformations acquired with a markerless multi-view camera system. As a pivotal step in its creation, we process the reconstructed raw 3D shapes with position-based dynamics and an approach for non-uniform stiffness estimation of the head tissues, which results in plausible annotations of the surface deformations, hand-face contact regions and head-hand positions. At the core of our neural approach are a variational auto-encoder supplying the hand-face depth prior and modules that guide the 3D tracking by estimating the contacts and the deformations. Our final 3D hand and face reconstructions are realistic and more plausible compared to several baselines applicable in our setting, both quantitatively and qualitatively. https://vcai.mpi-inf.mpg.de/projects/Decaf


WideRange4D: Enabling High-Quality 4D Reconstruction with Wide-Range Movements and Scenes
With the rapid development of 3D reconstruction technology, research in 4D reconstruction is also advancing, existing 4D reconstruction methods can generate high-quality 4D scenes. However, due to the challenges in acquiring multi-view video data, the current 4D reconstruction benchmarks mainly display actions performed in place, such as dancing, within limited scenarios. In practical scenarios, many scenes involve wide-range spatial movements, highlighting the limitations of existing 4D reconstruction datasets. Additionally, existing 4D reconstruction methods rely on deformation fields to estimate the dynamics of 3D objects, but deformation fields struggle with wide-range spatial movements, which limits the ability to achieve high-quality 4D scene reconstruction with wide-range spatial movements. In this paper, we focus on 4D scene reconstruction with significant object spatial movements and propose a novel 4D reconstruction benchmark, WideRange4D. This benchmark includes rich 4D scene data with large spatial variations, allowing for a more comprehensive evaluation of the generation capabilities of 4D generation methods. Furthermore, we introduce a new 4D reconstruction method, Progress4D, which generates stable and high-quality 4D results across various complex 4D scene reconstruction tasks. We conduct both quantitative and qualitative comparison experiments on WideRange4D, showing that our Progress4D outperforms existing state-of-the-art 4D reconstruction methods. Project: https://github.com/Gen-Verse/WideRange4D





SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion
We present Stable Video 3D (SV3D) -- a latent video diffusion model for high-resolution, image-to-multi-view generation of orbital videos around a 3D object. Recent work on 3D generation propose techniques to adapt 2D generative models for novel view synthesis (NVS) and 3D optimization. However, these methods have several disadvantages due to either limited views or inconsistent NVS, thereby affecting the performance of 3D object generation. In this work, we propose SV3D that adapts image-to-video diffusion model for novel multi-view synthesis and 3D generation, thereby leveraging the generalization and multi-view consistency of the video models, while further adding explicit camera control for NVS. We also propose improved 3D optimization techniques to use SV3D and its NVS outputs for image-to-3D generation. Extensive experimental results on multiple datasets with 2D and 3D metrics as well as user study demonstrate SV3D's state-of-the-art performance on NVS as well as 3D reconstruction compared to prior works.





ViSA: 3D-Aware Video Shading for Real-Time Upper-Body Avatar Creation
Generating high-fidelity upper-body 3D avatars from one-shot input image remains a significant challenge. Current 3D avatar generation methods, which rely on large reconstruction models, are fast and capable of producing stable body structures, but they often suffer from artifacts such as blurry textures and stiff, unnatural motion. In contrast, generative video models show promising performance by synthesizing photorealistic and dynamic results, but they frequently struggle with unstable behavior, including body structural errors and identity drift. To address these limitations, we propose a novel approach that combines the strengths of both paradigms. Our framework employs a 3D reconstruction model to provide robust structural and appearance priors, which in turn guides a real-time autoregressive video diffusion model for rendering. This process enables the model to synthesize high-frequency, photorealistic details and fluid dynamics in real time, effectively reducing texture blur and motion stiffness while preventing the structural inconsistencies common in video generation methods. By uniting the geometric stability of 3D reconstruction with the generative capabilities of video models, our method produces high-fidelity digital avatars with realistic appearance and dynamic, temporally coherent motion. Experiments demonstrate that our approach significantly reduces artifacts and achieves substantial improvements in visual quality over leading methods, providing a robust and efficient solution for real-time applications such as gaming and virtual reality. Project page: https://lhyfst.github.io/visa
SC4D: Sparse-Controlled Video-to-4D Generation and Motion Transfer
Recent advances in 2D/3D generative models enable the generation of dynamic 3D objects from a single-view video. Existing approaches utilize score distillation sampling to form the dynamic scene as dynamic NeRF or dense 3D Gaussians. However, these methods struggle to strike a balance among reference view alignment, spatio-temporal consistency, and motion fidelity under single-view conditions due to the implicit nature of NeRF or the intricate dense Gaussian motion prediction. To address these issues, this paper proposes an efficient, sparse-controlled video-to-4D framework named SC4D, that decouples motion and appearance to achieve superior video-to-4D generation. Moreover, we introduce Adaptive Gaussian (AG) initialization and Gaussian Alignment (GA) loss to mitigate shape degeneration issue, ensuring the fidelity of the learned motion and shape. Comprehensive experimental results demonstrate that our method surpasses existing methods in both quality and efficiency. In addition, facilitated by the disentangled modeling of motion and appearance of SC4D, we devise a novel application that seamlessly transfers the learned motion onto a diverse array of 4D entities according to textual descriptions.

MotionCrafter: Dense Geometry and Motion Reconstruction with a 4D VAE
We introduce MotionCrafter, a video diffusion-based framework that jointly reconstructs 4D geometry and estimates dense motion from a monocular video. The core of our method is a novel joint representation of dense 3D point maps and 3D scene flows in a shared coordinate system, and a novel 4D VAE to effectively learn this representation. Unlike prior work that forces the 3D value and latents to align strictly with RGB VAE latents-despite their fundamentally different distributions-we show that such alignment is unnecessary and leads to suboptimal performance. Instead, we introduce a new data normalization and VAE training strategy that better transfers diffusion priors and greatly improves reconstruction quality. Extensive experiments across multiple datasets demonstrate that MotionCrafter achieves state-of-the-art performance in both geometry reconstruction and dense scene flow estimation, delivering 38.64% and 25.0% improvements in geometry and motion reconstruction, respectively, all without any post-optimization. Project page: https://ruijiezhu94.github.io/MotionCrafter_Page

MotionGS: Exploring Explicit Motion Guidance for Deformable 3D Gaussian Splatting
Dynamic scene reconstruction is a long-term challenge in the field of 3D vision. Recently, the emergence of 3D Gaussian Splatting has provided new insights into this problem. Although subsequent efforts rapidly extend static 3D Gaussian to dynamic scenes, they often lack explicit constraints on object motion, leading to optimization difficulties and performance degradation. To address the above issues, we propose a novel deformable 3D Gaussian splatting framework called MotionGS, which explores explicit motion priors to guide the deformation of 3D Gaussians. Specifically, we first introduce an optical flow decoupling module that decouples optical flow into camera flow and motion flow, corresponding to camera movement and object motion respectively. Then the motion flow can effectively constrain the deformation of 3D Gaussians, thus simulating the motion of dynamic objects. Additionally, a camera pose refinement module is proposed to alternately optimize 3D Gaussians and camera poses, mitigating the impact of inaccurate camera poses. Extensive experiments in the monocular dynamic scenes validate that MotionGS surpasses state-of-the-art methods and exhibits significant superiority in both qualitative and quantitative results. Project page: https://ruijiezhu94.github.io/MotionGS_page





Motion-aware 3D Gaussian Splatting for Efficient Dynamic Scene Reconstruction
3D Gaussian Splatting (3DGS) has become an emerging tool for dynamic scene reconstruction. However, existing methods focus mainly on extending static 3DGS into a time-variant representation, while overlooking the rich motion information carried by 2D observations, thus suffering from performance degradation and model redundancy. To address the above problem, we propose a novel motion-aware enhancement framework for dynamic scene reconstruction, which mines useful motion cues from optical flow to improve different paradigms of dynamic 3DGS. Specifically, we first establish a correspondence between 3D Gaussian movements and pixel-level flow. Then a novel flow augmentation method is introduced with additional insights into uncertainty and loss collaboration. Moreover, for the prevalent deformation-based paradigm that presents a harder optimization problem, a transient-aware deformation auxiliary module is proposed. We conduct extensive experiments on both multi-view and monocular scenes to verify the merits of our work. Compared with the baselines, our method shows significant superiority in both rendering quality and efficiency.

Shape of Motion: 4D Reconstruction from a Single Video
Monocular dynamic reconstruction is a challenging and long-standing vision problem due to the highly ill-posed nature of the task. Existing approaches are limited in that they either depend on templates, are effective only in quasi-static scenes, or fail to model 3D motion explicitly. In this work, we introduce a method capable of reconstructing generic dynamic scenes, featuring explicit, full-sequence-long 3D motion, from casually captured monocular videos. We tackle the under-constrained nature of the problem with two key insights: First, we exploit the low-dimensional structure of 3D motion by representing scene motion with a compact set of SE3 motion bases. Each point's motion is expressed as a linear combination of these bases, facilitating soft decomposition of the scene into multiple rigidly-moving groups. Second, we utilize a comprehensive set of data-driven priors, including monocular depth maps and long-range 2D tracks, and devise a method to effectively consolidate these noisy supervisory signals, resulting in a globally consistent representation of the dynamic scene. Experiments show that our method achieves state-of-the-art performance for both long-range 3D/2D motion estimation and novel view synthesis on dynamic scenes. Project Page: https://shape-of-motion.github.io/

Vid3D: Synthesis of Dynamic 3D Scenes using 2D Video Diffusion
A recent frontier in computer vision has been the task of 3D video generation, which consists of generating a time-varying 3D representation of a scene. To generate dynamic 3D scenes, current methods explicitly model 3D temporal dynamics by jointly optimizing for consistency across both time and views of the scene. In this paper, we instead investigate whether it is necessary to explicitly enforce multiview consistency over time, as current approaches do, or if it is sufficient for a model to generate 3D representations of each timestep independently. We hence propose a model, Vid3D, that leverages 2D video diffusion to generate 3D videos by first generating a 2D "seed" of the video's temporal dynamics and then independently generating a 3D representation for each timestep in the seed video. We evaluate Vid3D against two state-of-the-art 3D video generation methods and find that Vid3D is achieves comparable results despite not explicitly modeling 3D temporal dynamics. We further ablate how the quality of Vid3D depends on the number of views generated per frame. While we observe some degradation with fewer views, performance degradation remains minor. Our results thus suggest that 3D temporal knowledge may not be necessary to generate high-quality dynamic 3D scenes, potentially enabling simpler generative algorithms for this task.



Structure From Tracking: Distilling Structure-Preserving Motion for Video Generation
Reality is a dance between rigid constraints and deformable structures. For video models, that means generating motion that preserves fidelity as well as structure. Despite progress in diffusion models, producing realistic structure-preserving motion remains challenging, especially for articulated and deformable objects such as humans and animals. Scaling training data alone, so far, has failed to resolve physically implausible transitions. Existing approaches rely on conditioning with noisy motion representations, such as optical flow or skeletons extracted using an external imperfect model. To address these challenges, we introduce an algorithm to distill structure-preserving motion priors from an autoregressive video tracking model (SAM2) into a bidirectional video diffusion model (CogVideoX). With our method, we train SAM2VideoX, which contains two innovations: (1) a bidirectional feature fusion module that extracts global structure-preserving motion priors from a recurrent model like SAM2; (2) a Local Gram Flow loss that aligns how local features move together. Experiments on VBench and in human studies show that SAM2VideoX delivers consistent gains (+2.60\% on VBench, 21-22\% lower FVD, and 71.4\% human preference) over prior baselines. Specifically, on VBench, we achieve 95.51\%, surpassing REPA (92.91\%) by 2.60\%, and reduce FVD to 360.57, a 21.20\% and 22.46\% improvement over REPA- and LoRA-finetuning, respectively. The project website can be found at https://sam2videox.github.io/ .


Platypose: Calibrated Zero-Shot Multi-Hypothesis 3D Human Motion Estimation
Single camera 3D pose estimation is an ill-defined problem due to inherent ambiguities from depth, occlusion or keypoint noise. Multi-hypothesis pose estimation accounts for this uncertainty by providing multiple 3D poses consistent with the 2D measurements. Current research has predominantly concentrated on generating multiple hypotheses for single frame static pose estimation. In this study we focus on the new task of multi-hypothesis motion estimation. Motion estimation is not simply pose estimation applied to multiple frames, which would ignore temporal correlation across frames. Instead, it requires distributions which are capable of generating temporally consistent samples, which is significantly more challenging. To this end, we introduce Platypose, a framework that uses a diffusion model pretrained on 3D human motion sequences for zero-shot 3D pose sequence estimation. Platypose outperforms baseline methods on multiple hypotheses for motion estimation. Additionally, Platypose also achieves state-of-the-art calibration and competitive joint error when tested on static poses from Human3.6M, MPI-INF-3DHP and 3DPW. Finally, because it is zero-shot, our method generalizes flexibly to different settings such as multi-camera inference.

3D Cinemagraphy from a Single Image
We present 3D Cinemagraphy, a new technique that marries 2D image animation with 3D photography. Given a single still image as input, our goal is to generate a video that contains both visual content animation and camera motion. We empirically find that naively combining existing 2D image animation and 3D photography methods leads to obvious artifacts or inconsistent animation. Our key insight is that representing and animating the scene in 3D space offers a natural solution to this task. To this end, we first convert the input image into feature-based layered depth images using predicted depth values, followed by unprojecting them to a feature point cloud. To animate the scene, we perform motion estimation and lift the 2D motion into the 3D scene flow. Finally, to resolve the problem of hole emergence as points move forward, we propose to bidirectionally displace the point cloud as per the scene flow and synthesize novel views by separately projecting them into target image planes and blending the results. Extensive experiments demonstrate the effectiveness of our method. A user study is also conducted to validate the compelling rendering results of our method.
Image as an IMU: Estimating Camera Motion from a Single Motion-Blurred Image
In many robotics and VR/AR applications, fast camera motions cause a high level of motion blur, causing existing camera pose estimation methods to fail. In this work, we propose a novel framework that leverages motion blur as a rich cue for motion estimation rather than treating it as an unwanted artifact. Our approach works by predicting a dense motion flow field and a monocular depth map directly from a single motion-blurred image. We then recover the instantaneous camera velocity by solving a linear least squares problem under the small motion assumption. In essence, our method produces an IMU-like measurement that robustly captures fast and aggressive camera movements. To train our model, we construct a large-scale dataset with realistic synthetic motion blur derived from ScanNet++v2 and further refine our model by training end-to-end on real data using our fully differentiable pipeline. Extensive evaluations on real-world benchmarks demonstrate that our method achieves state-of-the-art angular and translational velocity estimates, outperforming current methods like MASt3R and COLMAP.


TAPIP3D: Tracking Any Point in Persistent 3D Geometry
We introduce TAPIP3D, a novel approach for long-term 3D point tracking in monocular RGB and RGB-D videos. TAPIP3D represents videos as camera-stabilized spatio-temporal feature clouds, leveraging depth and camera motion information to lift 2D video features into a 3D world space where camera motion is effectively canceled. TAPIP3D iteratively refines multi-frame 3D motion estimates within this stabilized representation, enabling robust tracking over extended periods. To manage the inherent irregularities of 3D point distributions, we propose a Local Pair Attention mechanism. This 3D contextualization strategy effectively exploits spatial relationships in 3D, forming informative feature neighborhoods for precise 3D trajectory estimation. Our 3D-centric approach significantly outperforms existing 3D point tracking methods and even enhances 2D tracking accuracy compared to conventional 2D pixel trackers when accurate depth is available. It supports inference in both camera coordinates (i.e., unstabilized) and world coordinates, and our results demonstrate that compensating for camera motion improves tracking performance. Our approach replaces the conventional 2D square correlation neighborhoods used in prior 2D and 3D trackers, leading to more robust and accurate results across various 3D point tracking benchmarks. Project Page: https://tapip3d.github.io


C4D: 4D Made from 3D through Dual Correspondences
Recovering 4D from monocular video, which jointly estimates dynamic geometry and camera poses, is an inevitably challenging problem. While recent pointmap-based 3D reconstruction methods (e.g., DUSt3R) have made great progress in reconstructing static scenes, directly applying them to dynamic scenes leads to inaccurate results. This discrepancy arises because moving objects violate multi-view geometric constraints, disrupting the reconstruction. To address this, we introduce C4D, a framework that leverages temporal Correspondences to extend existing 3D reconstruction formulation to 4D. Specifically, apart from predicting pointmaps, C4D captures two types of correspondences: short-term optical flow and long-term point tracking. We train a dynamic-aware point tracker that provides additional mobility information, facilitating the estimation of motion masks to separate moving elements from the static background, thus offering more reliable guidance for dynamic scenes. Furthermore, we introduce a set of dynamic scene optimization objectives to recover per-frame 3D geometry and camera parameters. Simultaneously, the correspondences lift 2D trajectories into smooth 3D trajectories, enabling fully integrated 4D reconstruction. Experiments show that our framework achieves complete 4D recovery and demonstrates strong performance across multiple downstream tasks, including depth estimation, camera pose estimation, and point tracking. Project Page: https://littlepure2333.github.io/C4D

Joint 3D Geometry Reconstruction and Motion Generation for 4D Synthesis from a Single Image
Generating interactive and dynamic 4D scenes from a single static image remains a core challenge. Most existing generate-then-reconstruct and reconstruct-then-generate methods decouple geometry from motion, causing spatiotemporal inconsistencies and poor generalization. To address these, we extend the reconstruct-then-generate framework to jointly perform Motion generation and geometric Reconstruction for 4D Synthesis (MoRe4D). We first introduce TrajScene-60K, a large-scale dataset of 60,000 video samples with dense point trajectories, addressing the scarcity of high-quality 4D scene data. Based on this, we propose a diffusion-based 4D Scene Trajectory Generator (4D-STraG) to jointly generate geometrically consistent and motion-plausible 4D point trajectories. To leverage single-view priors, we design a depth-guided motion normalization strategy and a motion-aware module for effective geometry and dynamics integration. We then propose a 4D View Synthesis Module (4D-ViSM) to render videos with arbitrary camera trajectories from 4D point track representations. Experiments show that MoRe4D generates high-quality 4D scenes with multi-view consistency and rich dynamic details from a single image. Code: https://github.com/Zhangyr2022/MoRe4D.

Gaussians-to-Life: Text-Driven Animation of 3D Gaussian Splatting Scenes
State-of-the-art novel view synthesis methods achieve impressive results for multi-view captures of static 3D scenes. However, the reconstructed scenes still lack "liveliness," a key component for creating engaging 3D experiences. Recently, novel video diffusion models generate realistic videos with complex motion and enable animations of 2D images, however they cannot naively be used to animate 3D scenes as they lack multi-view consistency. To breathe life into the static world, we propose Gaussians2Life, a method for animating parts of high-quality 3D scenes in a Gaussian Splatting representation. Our key idea is to leverage powerful video diffusion models as the generative component of our model and to combine these with a robust technique to lift 2D videos into meaningful 3D motion. We find that, in contrast to prior work, this enables realistic animations of complex, pre-existing 3D scenes and further enables the animation of a large variety of object classes, while related work is mostly focused on prior-based character animation, or single 3D objects. Our model enables the creation of consistent, immersive 3D experiences for arbitrary scenes.

Any4D: Unified Feed-Forward Metric 4D Reconstruction
We present Any4D, a scalable multi-view transformer for metric-scale, dense feed-forward 4D reconstruction. Any4D directly generates per-pixel motion and geometry predictions for N frames, in contrast to prior work that typically focuses on either 2-view dense scene flow or sparse 3D point tracking. Moreover, unlike other recent methods for 4D reconstruction from monocular RGB videos, Any4D can process additional modalities and sensors such as RGB-D frames, IMU-based egomotion, and Radar Doppler measurements, when available. One of the key innovations that allows for such a flexible framework is a modular representation of a 4D scene; specifically, per-view 4D predictions are encoded using a variety of egocentric factors (depthmaps and camera intrinsics) represented in local camera coordinates, and allocentric factors (camera extrinsics and scene flow) represented in global world coordinates. We achieve superior performance across diverse setups - both in terms of accuracy (2-3X lower error) and compute efficiency (15X faster), opening avenues for multiple downstream applications.
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
Videos inherently represent 2D projections of a dynamic 3D world. However, our analysis suggests that video diffusion models trained solely on raw video data often fail to capture meaningful geometric-aware structure in their learned representations. To bridge this gap between video diffusion models and the underlying 3D nature of the physical world, we propose Geometry Forcing, a simple yet effective method that encourages video diffusion models to internalize latent 3D representations. Our key insight is to guide the model's intermediate representations toward geometry-aware structure by aligning them with features from a pretrained geometric foundation model. To this end, we introduce two complementary alignment objectives: Angular Alignment, which enforces directional consistency via cosine similarity, and Scale Alignment, which preserves scale-related information by regressing unnormalized geometric features from normalized diffusion representation. We evaluate Geometry Forcing on both camera view-conditioned and action-conditioned video generation tasks. Experimental results demonstrate that our method substantially improves visual quality and 3D consistency over the baseline methods. Project page: https://GeometryForcing.github.io.



SimMotionEdit: Text-Based Human Motion Editing with Motion Similarity Prediction
Text-based 3D human motion editing is a critical yet challenging task in computer vision and graphics. While training-free approaches have been explored, the recent release of the MotionFix dataset, which includes source-text-motion triplets, has opened new avenues for training, yielding promising results. However, existing methods struggle with precise control, often leading to misalignment between motion semantics and language instructions. In this paper, we introduce a related task, motion similarity prediction, and propose a multi-task training paradigm, where we train the model jointly on motion editing and motion similarity prediction to foster the learning of semantically meaningful representations. To complement this task, we design an advanced Diffusion-Transformer-based architecture that separately handles motion similarity prediction and motion editing. Extensive experiments demonstrate the state-of-the-art performance of our approach in both editing alignment and fidelity.
SpatialTrackerV2: 3D Point Tracking Made Easy
We present SpatialTrackerV2, a feed-forward 3D point tracking method for monocular videos. Going beyond modular pipelines built on off-the-shelf components for 3D tracking, our approach unifies the intrinsic connections between point tracking, monocular depth, and camera pose estimation into a high-performing and feedforward 3D point tracker. It decomposes world-space 3D motion into scene geometry, camera ego-motion, and pixel-wise object motion, with a fully differentiable and end-to-end architecture, allowing scalable training across a wide range of datasets, including synthetic sequences, posed RGB-D videos, and unlabeled in-the-wild footage. By learning geometry and motion jointly from such heterogeneous data, SpatialTrackerV2 outperforms existing 3D tracking methods by 30%, and matches the accuracy of leading dynamic 3D reconstruction approaches while running 50times faster.
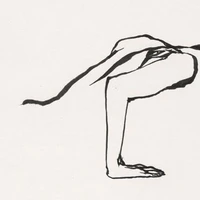


FMPose3D: monocular 3D pose estimation via flow matching
Monocular 3D pose estimation is fundamentally ill-posed due to depth ambiguity and occlusions, thereby motivating probabilistic methods that generate multiple plausible 3D pose hypotheses. In particular, diffusion-based models have recently demonstrated strong performance, but their iterative denoising process typically requires many timesteps for each prediction, making inference computationally expensive. In contrast, we leverage Flow Matching (FM) to learn a velocity field defined by an Ordinary Differential Equation (ODE), enabling efficient generation of 3D pose samples with only a few integration steps. We propose a novel generative pose estimation framework, FMPose3D, that formulates 3D pose estimation as a conditional distribution transport problem. It continuously transports samples from a standard Gaussian prior to the distribution of plausible 3D poses conditioned only on 2D inputs. Although ODE trajectories are deterministic, FMPose3D naturally generates various pose hypotheses by sampling different noise seeds. To obtain a single accurate prediction from those hypotheses, we further introduce a Reprojection-based Posterior Expectation Aggregation (RPEA) module, which approximates the Bayesian posterior expectation over 3D hypotheses. FMPose3D surpasses existing methods on the widely used human pose estimation benchmarks Human3.6M and MPI-INF-3DHP, and further achieves state-of-the-art performance on the 3D animal pose datasets Animal3D and CtrlAni3D, demonstrating strong performance across both 3D pose domains. The code is available at https://github.com/AdaptiveMotorControlLab/FMPose3D.
VideoFrom3D: 3D Scene Video Generation via Complementary Image and Video Diffusion Models
In this paper, we propose VideoFrom3D, a novel framework for synthesizing high-quality 3D scene videos from coarse geometry, a camera trajectory, and a reference image. Our approach streamlines the 3D graphic design workflow, enabling flexible design exploration and rapid production of deliverables. A straightforward approach to synthesizing a video from coarse geometry might condition a video diffusion model on geometric structure. However, existing video diffusion models struggle to generate high-fidelity results for complex scenes due to the difficulty of jointly modeling visual quality, motion, and temporal consistency. To address this, we propose a generative framework that leverages the complementary strengths of image and video diffusion models. Specifically, our framework consists of a Sparse Anchor-view Generation (SAG) and a Geometry-guided Generative Inbetweening (GGI) module. The SAG module generates high-quality, cross-view consistent anchor views using an image diffusion model, aided by Sparse Appearance-guided Sampling. Building on these anchor views, GGI module faithfully interpolates intermediate frames using a video diffusion model, enhanced by flow-based camera control and structural guidance. Notably, both modules operate without any paired dataset of 3D scene models and natural images, which is extremely difficult to obtain. Comprehensive experiments show that our method produces high-quality, style-consistent scene videos under diverse and challenging scenarios, outperforming simple and extended baselines.



Towards Physical Understanding in Video Generation: A 3D Point Regularization Approach
We present a novel video generation framework that integrates 3-dimensional geometry and dynamic awareness. To achieve this, we augment 2D videos with 3D point trajectories and align them in pixel space. The resulting 3D-aware video dataset, PointVid, is then used to fine-tune a latent diffusion model, enabling it to track 2D objects with 3D Cartesian coordinates. Building on this, we regularize the shape and motion of objects in the video to eliminate undesired artifacts, \eg, nonphysical deformation. Consequently, we enhance the quality of generated RGB videos and alleviate common issues like object morphing, which are prevalent in current video models due to a lack of shape awareness. With our 3D augmentation and regularization, our model is capable of handling contact-rich scenarios such as task-oriented videos. These videos involve complex interactions of solids, where 3D information is essential for perceiving deformation and contact. Furthermore, our model improves the overall quality of video generation by promoting the 3D consistency of moving objects and reducing abrupt changes in shape and motion.





PACE: Data-Driven Virtual Agent Interaction in Dense and Cluttered Environments
We present PACE, a novel method for modifying motion-captured virtual agents to interact with and move throughout dense, cluttered 3D scenes. Our approach changes a given motion sequence of a virtual agent as needed to adjust to the obstacles and objects in the environment. We first take the individual frames of the motion sequence most important for modeling interactions with the scene and pair them with the relevant scene geometry, obstacles, and semantics such that interactions in the agents motion match the affordances of the scene (e.g., standing on a floor or sitting in a chair). We then optimize the motion of the human by directly altering the high-DOF pose at each frame in the motion to better account for the unique geometric constraints of the scene. Our formulation uses novel loss functions that maintain a realistic flow and natural-looking motion. We compare our method with prior motion generating techniques and highlight the benefits of our method with a perceptual study and physical plausibility metrics. Human raters preferred our method over the prior approaches. Specifically, they preferred our method 57.1% of the time versus the state-of-the-art method using existing motions, and 81.0% of the time versus a state-of-the-art motion synthesis method. Additionally, our method performs significantly higher on established physical plausibility and interaction metrics. Specifically, we outperform competing methods by over 1.2% in terms of the non-collision metric and by over 18% in terms of the contact metric. We have integrated our interactive system with Microsoft HoloLens and demonstrate its benefits in real-world indoor scenes. Our project website is available at https://gamma.umd.edu/pace/.
PhysGM: Large Physical Gaussian Model for Feed-Forward 4D Synthesis
Despite advances in physics-based 3D motion synthesis, current methods face key limitations: reliance on pre-reconstructed 3D Gaussian Splatting (3DGS) built from dense multi-view images with time-consuming per-scene optimization; physics integration via either inflexible, hand-specified attributes or unstable, optimization-heavy guidance from video models using Score Distillation Sampling (SDS); and naive concatenation of prebuilt 3DGS with physics modules, which ignores physical information embedded in appearance and yields suboptimal performance. To address these issues, we propose PhysGM, a feed-forward framework that jointly predicts 3D Gaussian representation and physical properties from a single image, enabling immediate simulation and high-fidelity 4D rendering. Unlike slow appearance-agnostic optimization methods, we first pre-train a physics-aware reconstruction model that directly infers both Gaussian and physical parameters. We further refine the model with Direct Preference Optimization (DPO), aligning simulations with the physically plausible reference videos and avoiding the high-cost SDS optimization. To address the absence of a supporting dataset for this task, we propose PhysAssets, a dataset of 50K+ 3D assets annotated with physical properties and corresponding reference videos. Experiments show that PhysGM produces high-fidelity 4D simulations from a single image in one minute, achieving a significant speedup over prior work while delivering realistic renderings.Our project page is at:https://hihixiaolv.github.io/PhysGM.github.io/
MarS3D: A Plug-and-Play Motion-Aware Model for Semantic Segmentation on Multi-Scan 3D Point Clouds
3D semantic segmentation on multi-scan large-scale point clouds plays an important role in autonomous systems. Unlike the single-scan-based semantic segmentation task, this task requires distinguishing the motion states of points in addition to their semantic categories. However, methods designed for single-scan-based segmentation tasks perform poorly on the multi-scan task due to the lacking of an effective way to integrate temporal information. We propose MarS3D, a plug-and-play motion-aware module for semantic segmentation on multi-scan 3D point clouds. This module can be flexibly combined with single-scan models to allow them to have multi-scan perception abilities. The model encompasses two key designs: the Cross-Frame Feature Embedding module for enriching representation learning and the Motion-Aware Feature Learning module for enhancing motion awareness. Extensive experiments show that MarS3D can improve the performance of the baseline model by a large margin. The code is available at https://github.com/CVMI-Lab/MarS3D.

DIMO: Diverse 3D Motion Generation for Arbitrary Objects
We present DIMO, a generative approach capable of generating diverse 3D motions for arbitrary objects from a single image. The core idea of our work is to leverage the rich priors in well-trained video models to extract the common motion patterns and then embed them into a shared low-dimensional latent space. Specifically, we first generate multiple videos of the same object with diverse motions. We then embed each motion into a latent vector and train a shared motion decoder to learn the distribution of motions represented by a structured and compact motion representation, i.e., neural key point trajectories. The canonical 3D Gaussians are then driven by these key points and fused to model the geometry and appearance. During inference time with learned latent space, we can instantly sample diverse 3D motions in a single-forward pass and support several interesting applications including 3D motion interpolation and language-guided motion generation. Our project page is available at https://linzhanm.github.io/dimo.

SViMo: Synchronized Diffusion for Video and Motion Generation in Hand-object Interaction Scenarios
Hand-Object Interaction (HOI) generation has significant application potential. However, current 3D HOI motion generation approaches heavily rely on predefined 3D object models and lab-captured motion data, limiting generalization capabilities. Meanwhile, HOI video generation methods prioritize pixel-level visual fidelity, often sacrificing physical plausibility. Recognizing that visual appearance and motion patterns share fundamental physical laws in the real world, we propose a novel framework that combines visual priors and dynamic constraints within a synchronized diffusion process to generate the HOI video and motion simultaneously. To integrate the heterogeneous semantics, appearance, and motion features, our method implements tri-modal adaptive modulation for feature aligning, coupled with 3D full-attention for modeling inter- and intra-modal dependencies. Furthermore, we introduce a vision-aware 3D interaction diffusion model that generates explicit 3D interaction sequences directly from the synchronized diffusion outputs, then feeds them back to establish a closed-loop feedback cycle. This architecture eliminates dependencies on predefined object models or explicit pose guidance while significantly enhancing video-motion consistency. Experimental results demonstrate our method's superiority over state-of-the-art approaches in generating high-fidelity, dynamically plausible HOI sequences, with notable generalization capabilities in unseen real-world scenarios. Project page at https://github.com/Droliven/SViMo\_project.
GSOT3D: Towards Generic 3D Single Object Tracking in the Wild
In this paper, we present a novel benchmark, GSOT3D, that aims at facilitating development of generic 3D single object tracking (SOT) in the wild. Specifically, GSOT3D offers 620 sequences with 123K frames, and covers a wide selection of 54 object categories. Each sequence is offered with multiple modalities, including the point cloud (PC), RGB image, and depth. This allows GSOT3D to support various 3D tracking tasks, such as single-modal 3D SOT on PC and multi-modal 3D SOT on RGB-PC or RGB-D, and thus greatly broadens research directions for 3D object tracking. To provide highquality per-frame 3D annotations, all sequences are labeled manually with multiple rounds of meticulous inspection and refinement. To our best knowledge, GSOT3D is the largest benchmark dedicated to various generic 3D object tracking tasks. To understand how existing 3D trackers perform and to provide comparisons for future research on GSOT3D, we assess eight representative point cloud-based tracking models. Our evaluation results exhibit that these models heavily degrade on GSOT3D, and more efforts are required for robust and generic 3D object tracking. Besides, to encourage future research, we present a simple yet effective generic 3D tracker, named PROT3D, that localizes the target object via a progressive spatial-temporal network and outperforms all current solutions by a large margin. By releasing GSOT3D, we expect to advance further 3D tracking in future research and applications. Our benchmark and model as well as the evaluation results will be publicly released at our webpage https://github.com/ailovejinx/GSOT3D.
Street Gaussians without 3D Object Tracker
Realistic scene reconstruction in driving scenarios poses significant challenges due to fast-moving objects. Most existing methods rely on labor-intensive manual labeling of object poses to reconstruct dynamic objects in canonical space and move them based on these poses during rendering. While some approaches attempt to use 3D object trackers to replace manual annotations, the limited generalization of 3D trackers -- caused by the scarcity of large-scale 3D datasets -- results in inferior reconstructions in real-world settings. In contrast, 2D foundation models demonstrate strong generalization capabilities. To eliminate the reliance on 3D trackers and enhance robustness across diverse environments, we propose a stable object tracking module by leveraging associations from 2D deep trackers within a 3D object fusion strategy. We address inevitable tracking errors by further introducing a motion learning strategy in an implicit feature space that autonomously corrects trajectory errors and recovers missed detections. Experimental results on Waymo-NOTR and KITTI show that our method outperforms existing approaches. Our code will be released on https://lolrudy.github.io/No3DTrackSG/.
MIMO: Controllable Character Video Synthesis with Spatial Decomposed Modeling
Character video synthesis aims to produce realistic videos of animatable characters within lifelike scenes. As a fundamental problem in the computer vision and graphics community, 3D works typically require multi-view captures for per-case training, which severely limits their applicability of modeling arbitrary characters in a short time. Recent 2D methods break this limitation via pre-trained diffusion models, but they struggle for pose generality and scene interaction. To this end, we propose MIMO, a novel framework which can not only synthesize character videos with controllable attributes (i.e., character, motion and scene) provided by simple user inputs, but also simultaneously achieve advanced scalability to arbitrary characters, generality to novel 3D motions, and applicability to interactive real-world scenes in a unified framework. The core idea is to encode the 2D video to compact spatial codes, considering the inherent 3D nature of video occurrence. Concretely, we lift the 2D frame pixels into 3D using monocular depth estimators, and decompose the video clip to three spatial components (i.e., main human, underlying scene, and floating occlusion) in hierarchical layers based on the 3D depth. These components are further encoded to canonical identity code, structured motion code and full scene code, which are utilized as control signals of synthesis process. The design of spatial decomposed modeling enables flexible user control, complex motion expression, as well as 3D-aware synthesis for scene interactions. Experimental results demonstrate effectiveness and robustness of the proposed method.



VideoFlow: Exploiting Temporal Cues for Multi-frame Optical Flow Estimation
We introduce VideoFlow, a novel optical flow estimation framework for videos. In contrast to previous methods that learn to estimate optical flow from two frames, VideoFlow concurrently estimates bi-directional optical flows for multiple frames that are available in videos by sufficiently exploiting temporal cues. We first propose a TRi-frame Optical Flow (TROF) module that estimates bi-directional optical flows for the center frame in a three-frame manner. The information of the frame triplet is iteratively fused onto the center frame. To extend TROF for handling more frames, we further propose a MOtion Propagation (MOP) module that bridges multiple TROFs and propagates motion features between adjacent TROFs. With the iterative flow estimation refinement, the information fused in individual TROFs can be propagated into the whole sequence via MOP. By effectively exploiting video information, VideoFlow presents extraordinary performance, ranking 1st on all public benchmarks. On the Sintel benchmark, VideoFlow achieves 1.649 and 0.991 average end-point-error (AEPE) on the final and clean passes, a 15.1% and 7.6% error reduction from the best-published results (1.943 and 1.073 from FlowFormer++). On the KITTI-2015 benchmark, VideoFlow achieves an F1-all error of 3.65%, a 19.2% error reduction from the best-published result (4.52% from FlowFormer++). Code is released at https://github.com/XiaoyuShi97/VideoFlow.


MPI-Flow: Learning Realistic Optical Flow with Multiplane Images
The accuracy of learning-based optical flow estimation models heavily relies on the realism of the training datasets. Current approaches for generating such datasets either employ synthetic data or generate images with limited realism. However, the domain gap of these data with real-world scenes constrains the generalization of the trained model to real-world applications. To address this issue, we investigate generating realistic optical flow datasets from real-world images. Firstly, to generate highly realistic new images, we construct a layered depth representation, known as multiplane images (MPI), from single-view images. This allows us to generate novel view images that are highly realistic. To generate optical flow maps that correspond accurately to the new image, we calculate the optical flows of each plane using the camera matrix and plane depths. We then project these layered optical flows into the output optical flow map with volume rendering. Secondly, to ensure the realism of motion, we present an independent object motion module that can separate the camera and dynamic object motion in MPI. This module addresses the deficiency in MPI-based single-view methods, where optical flow is generated only by camera motion and does not account for any object movement. We additionally devise a depth-aware inpainting module to merge new images with dynamic objects and address unnatural motion occlusions. We show the superior performance of our method through extensive experiments on real-world datasets. Moreover, our approach achieves state-of-the-art performance in both unsupervised and supervised training of learning-based models. The code will be made publicly available at: https://github.com/Sharpiless/MPI-Flow.

Articulate That Object Part (ATOP): 3D Part Articulation via Text and Motion Personalization
We present ATOP (Articulate That Object Part), a novel few-shot method based on motion personalization to articulate a static 3D object with respect to a part and its motion as prescribed in a text prompt. Given the scarcity of available datasets with motion attribute annotations, existing methods struggle to generalize well in this task. In our work, the text input allows us to tap into the power of modern-day diffusion models to generate plausible motion samples for the right object category and part. In turn, the input 3D object provides image prompting to personalize the generated video to that very object we wish to articulate. Our method starts with a few-shot finetuning for category-specific motion generation, a key first step to compensate for the lack of articulation awareness by current diffusion models. For this, we finetune a pre-trained multi-view image generation model for controllable multi-view video generation, using a small collection of video samples obtained for the target object category. This is followed by motion video personalization that is realized by multi-view rendered images of the target 3D object. At last, we transfer the personalized video motion to the target 3D object via differentiable rendering to optimize part motion parameters by a score distillation sampling loss. Experimental results on PartNet-Sapien and ACD datasets show that our method is capable of generating realistic motion videos and predicting 3D motion parameters in a more accurate and generalizable way, compared to prior works in the few-shot setting.
4Diffusion: Multi-view Video Diffusion Model for 4D Generation
Current 4D generation methods have achieved noteworthy efficacy with the aid of advanced diffusion generative models. However, these methods lack multi-view spatial-temporal modeling and encounter challenges in integrating diverse prior knowledge from multiple diffusion models, resulting in inconsistent temporal appearance and flickers. In this paper, we propose a novel 4D generation pipeline, namely 4Diffusion aimed at generating spatial-temporally consistent 4D content from a monocular video. We first design a unified diffusion model tailored for multi-view video generation by incorporating a learnable motion module into a frozen 3D-aware diffusion model to capture multi-view spatial-temporal correlations. After training on a curated dataset, our diffusion model acquires reasonable temporal consistency and inherently preserves the generalizability and spatial consistency of the 3D-aware diffusion model. Subsequently, we propose 4D-aware Score Distillation Sampling loss, which is based on our multi-view video diffusion model, to optimize 4D representation parameterized by dynamic NeRF. This aims to eliminate discrepancies arising from multiple diffusion models, allowing for generating spatial-temporally consistent 4D content. Moreover, we devise an anchor loss to enhance the appearance details and facilitate the learning of dynamic NeRF. Extensive qualitative and quantitative experiments demonstrate that our method achieves superior performance compared to previous methods.



Gaussian-Flow: 4D Reconstruction with Dynamic 3D Gaussian Particle
We introduce Gaussian-Flow, a novel point-based approach for fast dynamic scene reconstruction and real-time rendering from both multi-view and monocular videos. In contrast to the prevalent NeRF-based approaches hampered by slow training and rendering speeds, our approach harnesses recent advancements in point-based 3D Gaussian Splatting (3DGS). Specifically, a novel Dual-Domain Deformation Model (DDDM) is proposed to explicitly model attribute deformations of each Gaussian point, where the time-dependent residual of each attribute is captured by a polynomial fitting in the time domain, and a Fourier series fitting in the frequency domain. The proposed DDDM is capable of modeling complex scene deformations across long video footage, eliminating the need for training separate 3DGS for each frame or introducing an additional implicit neural field to model 3D dynamics. Moreover, the explicit deformation modeling for discretized Gaussian points ensures ultra-fast training and rendering of a 4D scene, which is comparable to the original 3DGS designed for static 3D reconstruction. Our proposed approach showcases a substantial efficiency improvement, achieving a 5times faster training speed compared to the per-frame 3DGS modeling. In addition, quantitative results demonstrate that the proposed Gaussian-Flow significantly outperforms previous leading methods in novel view rendering quality. Project page: https://nju-3dv.github.io/projects/Gaussian-Flow

GeoVideo: Introducing Geometric Regularization into Video Generation Model
Recent advances in video generation have enabled the synthesis of high-quality and visually realistic clips using diffusion transformer models. However, most existing approaches operate purely in the 2D pixel space and lack explicit mechanisms for modeling 3D structures, often resulting in temporally inconsistent geometries, implausible motions, and structural artifacts. In this work, we introduce geometric regularization losses into video generation by augmenting latent diffusion models with per-frame depth prediction. We adopted depth as the geometric representation because of the great progress in depth prediction and its compatibility with image-based latent encoders. Specifically, to enforce structural consistency over time, we propose a multi-view geometric loss that aligns the predicted depth maps across frames within a shared 3D coordinate system. Our method bridges the gap between appearance generation and 3D structure modeling, leading to improved spatio-temporal coherence, shape consistency, and physical plausibility. Experiments across multiple datasets show that our approach produces significantly more stable and geometrically consistent results than existing baselines.
LiftImage3D: Lifting Any Single Image to 3D Gaussians with Video Generation Priors
Single-image 3D reconstruction remains a fundamental challenge in computer vision due to inherent geometric ambiguities and limited viewpoint information. Recent advances in Latent Video Diffusion Models (LVDMs) offer promising 3D priors learned from large-scale video data. However, leveraging these priors effectively faces three key challenges: (1) degradation in quality across large camera motions, (2) difficulties in achieving precise camera control, and (3) geometric distortions inherent to the diffusion process that damage 3D consistency. We address these challenges by proposing LiftImage3D, a framework that effectively releases LVDMs' generative priors while ensuring 3D consistency. Specifically, we design an articulated trajectory strategy to generate video frames, which decomposes video sequences with large camera motions into ones with controllable small motions. Then we use robust neural matching models, i.e. MASt3R, to calibrate the camera poses of generated frames and produce corresponding point clouds. Finally, we propose a distortion-aware 3D Gaussian splatting representation, which can learn independent distortions between frames and output undistorted canonical Gaussians. Extensive experiments demonstrate that LiftImage3D achieves state-of-the-art performance on two challenging datasets, i.e. LLFF, DL3DV, and Tanks and Temples, and generalizes well to diverse in-the-wild images, from cartoon illustrations to complex real-world scenes.

CamCtrl3D: Single-Image Scene Exploration with Precise 3D Camera Control
We propose a method for generating fly-through videos of a scene, from a single image and a given camera trajectory. We build upon an image-to-video latent diffusion model. We condition its UNet denoiser on the camera trajectory, using four techniques. (1) We condition the UNet's temporal blocks on raw camera extrinsics, similar to MotionCtrl. (2) We use images containing camera rays and directions, similar to CameraCtrl. (3) We reproject the initial image to subsequent frames and use the resulting video as a condition. (4) We use 2D<=>3D transformers to introduce a global 3D representation, which implicitly conditions on the camera poses. We combine all conditions in a ContolNet-style architecture. We then propose a metric that evaluates overall video quality and the ability to preserve details with view changes, which we use to analyze the trade-offs of individual and combined conditions. Finally, we identify an optimal combination of conditions. We calibrate camera positions in our datasets for scale consistency across scenes, and we train our scene exploration model, CamCtrl3D, demonstrating state-of-theart results.
Learning Human Motion Representations: A Unified Perspective
We present a unified perspective on tackling various human-centric video tasks by learning human motion representations from large-scale and heterogeneous data resources. Specifically, we propose a pretraining stage in which a motion encoder is trained to recover the underlying 3D motion from noisy partial 2D observations. The motion representations acquired in this way incorporate geometric, kinematic, and physical knowledge about human motion, which can be easily transferred to multiple downstream tasks. We implement the motion encoder with a Dual-stream Spatio-temporal Transformer (DSTformer) neural network. It could capture long-range spatio-temporal relationships among the skeletal joints comprehensively and adaptively, exemplified by the lowest 3D pose estimation error so far when trained from scratch. Furthermore, our proposed framework achieves state-of-the-art performance on all three downstream tasks by simply finetuning the pretrained motion encoder with a simple regression head (1-2 layers), which demonstrates the versatility of the learned motion representations.

Detecting Moving Objects Using a Novel Optical-Flow-Based Range-Independent Invariant
This paper focuses on a novel approach for detecting moving objects during camera motion. We present an optical-flow-based transformation that yields a consistent 2D invariant image output regardless of time instants, range of points in 3D, and the speed of the camera. In other words, this transformation generates a lookup image that remains invariant despite the changing projection of the 3D scene and camera motion. In the new domain, projections of 3D points that deviate from the values of the predefined lookup image can be clearly identified as moving relative to the stationary 3D environment, making them seamlessly detectable. The method does not require prior knowledge of the direction of motion or speed of the camera, nor does it necessitate 3D point range information. It is well-suited for real-time parallel processing, rendering it highly practical for implementation. We have validated the effectiveness of the new domain through simulations and experiments, demonstrating its robustness in scenarios involving rectilinear camera motion, both in simulations and with real-world data. This approach introduces new ways for moving objects detection during camera motion, and also lays the foundation for future research in the context of moving object detection during six-degrees-of-freedom camera motion.
Can Video Diffusion Model Reconstruct 4D Geometry?
Reconstructing dynamic 3D scenes (i.e., 4D geometry) from monocular video is an important yet challenging problem. Conventional multiview geometry-based approaches often struggle with dynamic motion, whereas recent learning-based methods either require specialized 4D representation or sophisticated optimization. In this paper, we present Sora3R, a novel framework that taps into the rich spatiotemporal priors of large-scale video diffusion models to directly infer 4D pointmaps from casual videos. Sora3R follows a two-stage pipeline: (1) we adapt a pointmap VAE from a pretrained video VAE, ensuring compatibility between the geometry and video latent spaces; (2) we finetune a diffusion backbone in combined video and pointmap latent space to generate coherent 4D pointmaps for every frame. Sora3R operates in a fully feedforward manner, requiring no external modules (e.g., depth, optical flow, or segmentation) or iterative global alignment. Extensive experiments demonstrate that Sora3R reliably recovers both camera poses and detailed scene geometry, achieving performance on par with state-of-the-art methods for dynamic 4D reconstruction across diverse scenarios.

SCAIL: Towards Studio-Grade Character Animation via In-Context Learning of 3D-Consistent Pose Representations
Achieving character animation that meets studio-grade production standards remains challenging despite recent progress. Existing approaches can transfer motion from a driving video to a reference image, but often fail to preserve structural fidelity and temporal consistency in wild scenarios involving complex motion and cross-identity animations. In this work, we present SCAIL (Studio-grade Character Animation via In-context Learning), a framework designed to address these challenges from two key innovations. First, we propose a novel 3D pose representation, providing a more robust and flexible motion signal. Second, we introduce a full-context pose injection mechanism within a diffusion-transformer architecture, enabling effective spatio-temporal reasoning over full motion sequences. To align with studio-level requirements, we develop a curated data pipeline ensuring both diversity and quality, and establish a comprehensive benchmark for systematic evaluation. Experiments show that SCAIL achieves state-of-the-art performance and advances character animation toward studio-grade reliability and realism.

You See it, You Got it: Learning 3D Creation on Pose-Free Videos at Scale
Recent 3D generation models typically rely on limited-scale 3D `gold-labels' or 2D diffusion priors for 3D content creation. However, their performance is upper-bounded by constrained 3D priors due to the lack of scalable learning paradigms. In this work, we present See3D, a visual-conditional multi-view diffusion model trained on large-scale Internet videos for open-world 3D creation. The model aims to Get 3D knowledge by solely Seeing the visual contents from the vast and rapidly growing video data -- You See it, You Got it. To achieve this, we first scale up the training data using a proposed data curation pipeline that automatically filters out multi-view inconsistencies and insufficient observations from source videos. This results in a high-quality, richly diverse, large-scale dataset of multi-view images, termed WebVi3D, containing 320M frames from 16M video clips. Nevertheless, learning generic 3D priors from videos without explicit 3D geometry or camera pose annotations is nontrivial, and annotating poses for web-scale videos is prohibitively expensive. To eliminate the need for pose conditions, we introduce an innovative visual-condition - a purely 2D-inductive visual signal generated by adding time-dependent noise to the masked video data. Finally, we introduce a novel visual-conditional 3D generation framework by integrating See3D into a warping-based pipeline for high-fidelity 3D generation. Our numerical and visual comparisons on single and sparse reconstruction benchmarks show that See3D, trained on cost-effective and scalable video data, achieves notable zero-shot and open-world generation capabilities, markedly outperforming models trained on costly and constrained 3D datasets. Please refer to our project page at: https://vision.baai.ac.cn/see3d





Infinite-Homography as Robust Conditioning for Camera-Controlled Video Generation
Recent progress in video diffusion models has spurred growing interest in camera-controlled novel-view video generation for dynamic scenes, aiming to provide creators with cinematic camera control capabilities in post-production. A key challenge in camera-controlled video generation is ensuring fidelity to the specified camera pose, while maintaining view consistency and reasoning about occluded geometry from limited observations. To address this, existing methods either train trajectory-conditioned video generation model on trajectory-video pair dataset, or estimate depth from the input video to reproject it along a target trajectory and generate the unprojected regions. Nevertheless, existing methods struggle to generate camera-pose-faithful, high-quality videos for two main reasons: (1) reprojection-based approaches are highly susceptible to errors caused by inaccurate depth estimation; and (2) the limited diversity of camera trajectories in existing datasets restricts learned models. To address these limitations, we present InfCam, a depth-free, camera-controlled video-to-video generation framework with high pose fidelity. The framework integrates two key components: (1) infinite homography warping, which encodes 3D camera rotations directly within the 2D latent space of a video diffusion model. Conditioning on this noise-free rotational information, the residual parallax term is predicted through end-to-end training to achieve high camera-pose fidelity; and (2) a data augmentation pipeline that transforms existing synthetic multiview datasets into sequences with diverse trajectories and focal lengths. Experimental results demonstrate that InfCam outperforms baseline methods in camera-pose accuracy and visual fidelity, generalizing well from synthetic to real-world data. Link to our project page:https://emjay73.github.io/InfCam/

LocalDyGS: Multi-view Global Dynamic Scene Modeling via Adaptive Local Implicit Feature Decoupling
Due to the complex and highly dynamic motions in the real world, synthesizing dynamic videos from multi-view inputs for arbitrary viewpoints is challenging. Previous works based on neural radiance field or 3D Gaussian splatting are limited to modeling fine-scale motion, greatly restricting their application. In this paper, we introduce LocalDyGS, which consists of two parts to adapt our method to both large-scale and fine-scale motion scenes: 1) We decompose a complex dynamic scene into streamlined local spaces defined by seeds, enabling global modeling by capturing motion within each local space. 2) We decouple static and dynamic features for local space motion modeling. A static feature shared across time steps captures static information, while a dynamic residual field provides time-specific features. These are combined and decoded to generate Temporal Gaussians, modeling motion within each local space. As a result, we propose a novel dynamic scene reconstruction framework to model highly dynamic real-world scenes more realistically. Our method not only demonstrates competitive performance on various fine-scale datasets compared to state-of-the-art (SOTA) methods, but also represents the first attempt to model larger and more complex highly dynamic scenes. Project page: https://wujh2001.github.io/LocalDyGS/.
Trace Anything: Representing Any Video in 4D via Trajectory Fields
Effective spatio-temporal representation is fundamental to modeling, understanding, and predicting dynamics in videos. The atomic unit of a video, the pixel, traces a continuous 3D trajectory over time, serving as the primitive element of dynamics. Based on this principle, we propose representing any video as a Trajectory Field: a dense mapping that assigns a continuous 3D trajectory function of time to each pixel in every frame. With this representation, we introduce Trace Anything, a neural network that predicts the entire trajectory field in a single feed-forward pass. Specifically, for each pixel in each frame, our model predicts a set of control points that parameterizes a trajectory (i.e., a B-spline), yielding its 3D position at arbitrary query time instants. We trained the Trace Anything model on large-scale 4D data, including data from our new platform, and our experiments demonstrate that: (i) Trace Anything achieves state-of-the-art performance on our new benchmark for trajectory field estimation and performs competitively on established point-tracking benchmarks; (ii) it offers significant efficiency gains thanks to its one-pass paradigm, without requiring iterative optimization or auxiliary estimators; and (iii) it exhibits emergent abilities, including goal-conditioned manipulation, motion forecasting, and spatio-temporal fusion. Project page: https://trace-anything.github.io/.

Monocular Quasi-Dense 3D Object Tracking
A reliable and accurate 3D tracking framework is essential for predicting future locations of surrounding objects and planning the observer's actions in numerous applications such as autonomous driving. We propose a framework that can effectively associate moving objects over time and estimate their full 3D bounding box information from a sequence of 2D images captured on a moving platform. The object association leverages quasi-dense similarity learning to identify objects in various poses and viewpoints with appearance cues only. After initial 2D association, we further utilize 3D bounding boxes depth-ordering heuristics for robust instance association and motion-based 3D trajectory prediction for re-identification of occluded vehicles. In the end, an LSTM-based object velocity learning module aggregates the long-term trajectory information for more accurate motion extrapolation. Experiments on our proposed simulation data and real-world benchmarks, including KITTI, nuScenes, and Waymo datasets, show that our tracking framework offers robust object association and tracking on urban-driving scenarios. On the Waymo Open benchmark, we establish the first camera-only baseline in the 3D tracking and 3D detection challenges. Our quasi-dense 3D tracking pipeline achieves impressive improvements on the nuScenes 3D tracking benchmark with near five times tracking accuracy of the best vision-only submission among all published methods. Our code, data and trained models are available at https://github.com/SysCV/qd-3dt.

FinePhys: Fine-grained Human Action Generation by Explicitly Incorporating Physical Laws for Effective Skeletal Guidance
Despite significant advances in video generation, synthesizing physically plausible human actions remains a persistent challenge, particularly in modeling fine-grained semantics and complex temporal dynamics. For instance, generating gymnastics routines such as "switch leap with 0.5 turn" poses substantial difficulties for current methods, often yielding unsatisfactory results. To bridge this gap, we propose FinePhys, a Fine-grained human action generation framework that incorporates Physics to obtain effective skeletal guidance. Specifically, FinePhys first estimates 2D poses in an online manner and then performs 2D-to-3D dimension lifting via in-context learning. To mitigate the instability and limited interpretability of purely data-driven 3D poses, we further introduce a physics-based motion re-estimation module governed by Euler-Lagrange equations, calculating joint accelerations via bidirectional temporal updating. The physically predicted 3D poses are then fused with data-driven ones, offering multi-scale 2D heatmap guidance for the diffusion process. Evaluated on three fine-grained action subsets from FineGym (FX-JUMP, FX-TURN, and FX-SALTO), FinePhys significantly outperforms competitive baselines. Comprehensive qualitative results further demonstrate FinePhys's ability to generate more natural and plausible fine-grained human actions.


Generative Video Motion Editing with 3D Point Tracks
Camera and object motions are central to a video's narrative. However, precisely editing these captured motions remains a significant challenge, especially under complex object movements. Current motion-controlled image-to-video (I2V) approaches often lack full-scene context for consistent video editing, while video-to-video (V2V) methods provide viewpoint changes or basic object translation, but offer limited control over fine-grained object motion. We present a track-conditioned V2V framework that enables joint editing of camera and object motion. We achieve this by conditioning a video generation model on a source video and paired 3D point tracks representing source and target motions. These 3D tracks establish sparse correspondences that transfer rich context from the source video to new motions while preserving spatiotemporal coherence. Crucially, compared to 2D tracks, 3D tracks provide explicit depth cues, allowing the model to resolve depth order and handle occlusions for precise motion editing. Trained in two stages on synthetic and real data, our model supports diverse motion edits, including joint camera/object manipulation, motion transfer, and non-rigid deformation, unlocking new creative potential in video editing.

MomentaMorph: Unsupervised Spatial-Temporal Registration with Momenta, Shooting, and Correction
Tagged magnetic resonance imaging (tMRI) has been employed for decades to measure the motion of tissue undergoing deformation. However, registration-based motion estimation from tMRI is difficult due to the periodic patterns in these images, particularly when the motion is large. With a larger motion the registration approach gets trapped in a local optima, leading to motion estimation errors. We introduce a novel "momenta, shooting, and correction" framework for Lagrangian motion estimation in the presence of repetitive patterns and large motion. This framework, grounded in Lie algebra and Lie group principles, accumulates momenta in the tangent vector space and employs exponential mapping in the diffeomorphic space for rapid approximation towards true optima, circumventing local optima. A subsequent correction step ensures convergence to true optima. The results on a 2D synthetic dataset and a real 3D tMRI dataset demonstrate our method's efficiency in estimating accurate, dense, and diffeomorphic 2D/3D motion fields amidst large motion and repetitive patterns.
ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model
3D human motion generation is crucial for creative industry. Recent advances rely on generative models with domain knowledge for text-driven motion generation, leading to substantial progress in capturing common motions. However, the performance on more diverse motions remains unsatisfactory. In this work, we propose ReMoDiffuse, a diffusion-model-based motion generation framework that integrates a retrieval mechanism to refine the denoising process. ReMoDiffuse enhances the generalizability and diversity of text-driven motion generation with three key designs: 1) Hybrid Retrieval finds appropriate references from the database in terms of both semantic and kinematic similarities. 2) Semantic-Modulated Transformer selectively absorbs retrieval knowledge, adapting to the difference between retrieved samples and the target motion sequence. 3) Condition Mixture better utilizes the retrieval database during inference, overcoming the scale sensitivity in classifier-free guidance. Extensive experiments demonstrate that ReMoDiffuse outperforms state-of-the-art methods by balancing both text-motion consistency and motion quality, especially for more diverse motion generation.




An Efficient 3D Gaussian Representation for Monocular/Multi-view Dynamic Scenes
In novel view synthesis of scenes from multiple input views, 3D Gaussian splatting emerges as a viable alternative to existing radiance field approaches, delivering great visual quality and real-time rendering. While successful in static scenes, the present advancement of 3D Gaussian representation, however, faces challenges in dynamic scenes in terms of memory consumption and the need for numerous observations per time step, due to the onus of storing 3D Gaussian parameters per time step. In this study, we present an efficient 3D Gaussian representation tailored for dynamic scenes in which we define positions and rotations as functions of time while leaving other time-invariant properties of the static 3D Gaussian unchanged. Notably, our representation reduces memory usage, which is consistent regardless of the input sequence length. Additionally, it mitigates the risk of overfitting observed frames by accounting for temporal changes. The optimization of our Gaussian representation based on image and flow reconstruction results in a powerful framework for dynamic scene view synthesis in both monocular and multi-view cases. We obtain the highest rendering speed of 118 frames per second (FPS) at a resolution of 1352 times 1014 with a single GPU, showing the practical usability and effectiveness of our proposed method in dynamic scene rendering scenarios.
FLD: Fourier Latent Dynamics for Structured Motion Representation and Learning
Motion trajectories offer reliable references for physics-based motion learning but suffer from sparsity, particularly in regions that lack sufficient data coverage. To address this challenge, we introduce a self-supervised, structured representation and generation method that extracts spatial-temporal relationships in periodic or quasi-periodic motions. The motion dynamics in a continuously parameterized latent space enable our method to enhance the interpolation and generalization capabilities of motion learning algorithms. The motion learning controller, informed by the motion parameterization, operates online tracking of a wide range of motions, including targets unseen during training. With a fallback mechanism, the controller dynamically adapts its tracking strategy and automatically resorts to safe action execution when a potentially risky target is proposed. By leveraging the identified spatial-temporal structure, our work opens new possibilities for future advancements in general motion representation and learning algorithms.
T3M: Text Guided 3D Human Motion Synthesis from Speech
Speech-driven 3D motion synthesis seeks to create lifelike animations based on human speech, with potential uses in virtual reality, gaming, and the film production. Existing approaches reply solely on speech audio for motion generation, leading to inaccurate and inflexible synthesis results. To mitigate this problem, we introduce a novel text-guided 3D human motion synthesis method, termed T3M. Unlike traditional approaches, T3M allows precise control over motion synthesis via textual input, enhancing the degree of diversity and user customization. The experiment results demonstrate that T3M can greatly outperform the state-of-the-art methods in both quantitative metrics and qualitative evaluations. We have publicly released our code at https://github.com/Gloria2tt/T3M.git{https://github.com/Gloria2tt/T3M.git}

MoMaps: Semantics-Aware Scene Motion Generation with Motion Maps
This paper addresses the challenge of learning semantically and functionally meaningful 3D motion priors from real-world videos, in order to enable prediction of future 3D scene motion from a single input image. We propose a novel pixel-aligned Motion Map (MoMap) representation for 3D scene motion, which can be generated from existing generative image models to facilitate efficient and effective motion prediction. To learn meaningful distributions over motion, we create a large-scale database of MoMaps from over 50,000 real videos and train a diffusion model on these representations. Our motion generation not only synthesizes trajectories in 3D but also suggests a new pipeline for 2D video synthesis: first generate a MoMap, then warp an image accordingly and complete the warped point-based renderings. Experimental results demonstrate that our approach generates plausible and semantically consistent 3D scene motion.
Emergent Extreme-View Geometry in 3D Foundation Models
3D foundation models (3DFMs) have recently transformed 3D vision, enabling joint prediction of depths, poses, and point maps directly from images. Yet their ability to reason under extreme, non-overlapping views remains largely unexplored. In this work, we study their internal representations and find that 3DFMs exhibit an emergent understanding of extreme-view geometry, despite never being trained for such conditions. To further enhance these capabilities, we introduce a lightweight alignment scheme that refines their internal 3D representation by tuning only a small subset of backbone bias terms, leaving all decoder heads frozen. This targeted adaptation substantially improves relative pose estimation under extreme viewpoints without degrading per-image depth or point quality. Additionally, we contribute MegaUnScene, a new benchmark of Internet scenes unseen by existing 3DFMs, with dedicated test splits for both relative pose estimation and dense 3D reconstruction. All code and data will be released.

3DRegNet: A Deep Neural Network for 3D Point Registration
We present 3DRegNet, a novel deep learning architecture for the registration of 3D scans. Given a set of 3D point correspondences, we build a deep neural network to address the following two challenges: (i) classification of the point correspondences into inliers/outliers, and (ii) regression of the motion parameters that align the scans into a common reference frame. With regard to regression, we present two alternative approaches: (i) a Deep Neural Network (DNN) registration and (ii) a Procrustes approach using SVD to estimate the transformation. Our correspondence-based approach achieves a higher speedup compared to competing baselines. We further propose the use of a refinement network, which consists of a smaller 3DRegNet as a refinement to improve the accuracy of the registration. Extensive experiments on two challenging datasets demonstrate that we outperform other methods and achieve state-of-the-art results. The code is available.

Text-To-4D Dynamic Scene Generation
We present MAV3D (Make-A-Video3D), a method for generating three-dimensional dynamic scenes from text descriptions. Our approach uses a 4D dynamic Neural Radiance Field (NeRF), which is optimized for scene appearance, density, and motion consistency by querying a Text-to-Video (T2V) diffusion-based model. The dynamic video output generated from the provided text can be viewed from any camera location and angle, and can be composited into any 3D environment. MAV3D does not require any 3D or 4D data and the T2V model is trained only on Text-Image pairs and unlabeled videos. We demonstrate the effectiveness of our approach using comprehensive quantitative and qualitative experiments and show an improvement over previously established internal baselines. To the best of our knowledge, our method is the first to generate 3D dynamic scenes given a text description.


Fast Multi-view Consistent 3D Editing with Video Priors
Text-driven 3D editing enables user-friendly 3D object or scene editing with text instructions. Due to the lack of multi-view consistency priors, existing methods typically resort to employing 2D generation or editing models to process each view individually, followed by iterative 2D-3D-2D updating. However, these methods are not only time-consuming but also prone to over-smoothed results because the different editing signals gathered from different views are averaged during the iterative process. In this paper, we propose generative Video Prior based 3D Editing (ViP3DE) to employ the temporal consistency priors from pre-trained video generation models for multi-view consistent 3D editing in a single forward pass. Our key insight is to condition the video generation model on a single edited view to generate other consistent edited views for 3D updating directly, thereby bypassing the iterative editing paradigm. Since 3D updating requires edited views to be paired with specific camera poses, we propose motion-preserved noise blending for the video model to generate edited views at predefined camera poses. In addition, we introduce geometry-aware denoising to further enhance multi-view consistency by integrating 3D geometric priors into video models. Extensive experiments demonstrate that our proposed ViP3DE can achieve high-quality 3D editing results even within a single forward pass, significantly outperforming existing methods in both editing quality and speed.
TrackingWorld: World-centric Monocular 3D Tracking of Almost All Pixels
Monocular 3D tracking aims to capture the long-term motion of pixels in 3D space from a single monocular video and has witnessed rapid progress in recent years. However, we argue that the existing monocular 3D tracking methods still fall short in separating the camera motion from foreground dynamic motion and cannot densely track newly emerging dynamic subjects in the videos. To address these two limitations, we propose TrackingWorld, a novel pipeline for dense 3D tracking of almost all pixels within a world-centric 3D coordinate system. First, we introduce a tracking upsampler that efficiently lifts the arbitrary sparse 2D tracks into dense 2D tracks. Then, to generalize the current tracking methods to newly emerging objects, we apply the upsampler to all frames and reduce the redundancy of 2D tracks by eliminating the tracks in overlapped regions. Finally, we present an efficient optimization-based framework to back-project dense 2D tracks into world-centric 3D trajectories by estimating the camera poses and the 3D coordinates of these 2D tracks. Extensive evaluations on both synthetic and real-world datasets demonstrate that our system achieves accurate and dense 3D tracking in a world-centric coordinate frame.

4-Doodle: Text to 3D Sketches that Move!
We present a novel task: text-to-3D sketch animation, which aims to bring freeform sketches to life in dynamic 3D space. Unlike prior works focused on photorealistic content generation, we target sparse, stylized, and view-consistent 3D vector sketches, a lightweight and interpretable medium well-suited for visual communication and prototyping. However, this task is very challenging: (i) no paired dataset exists for text and 3D (or 4D) sketches; (ii) sketches require structural abstraction that is difficult to model with conventional 3D representations like NeRFs or point clouds; and (iii) animating such sketches demands temporal coherence and multi-view consistency, which current pipelines do not address. Therefore, we propose 4-Doodle, the first training-free framework for generating dynamic 3D sketches from text. It leverages pretrained image and video diffusion models through a dual-space distillation scheme: one space captures multi-view-consistent geometry using differentiable Bézier curves, while the other encodes motion dynamics via temporally-aware priors. Unlike prior work (e.g., DreamFusion), which optimizes from a single view per step, our multi-view optimization ensures structural alignment and avoids view ambiguity, critical for sparse sketches. Furthermore, we introduce a structure-aware motion module that separates shape-preserving trajectories from deformation-aware changes, enabling expressive motion such as flipping, rotation, and articulated movement. Extensive experiments show that our method produces temporally realistic and structurally stable 3D sketch animations, outperforming existing baselines in both fidelity and controllability. We hope this work serves as a step toward more intuitive and accessible 4D content creation.
4DSloMo: 4D Reconstruction for High Speed Scene with Asynchronous Capture
Reconstructing fast-dynamic scenes from multi-view videos is crucial for high-speed motion analysis and realistic 4D reconstruction. However, the majority of 4D capture systems are limited to frame rates below 30 FPS (frames per second), and a direct 4D reconstruction of high-speed motion from low FPS input may lead to undesirable results. In this work, we propose a high-speed 4D capturing system only using low FPS cameras, through novel capturing and processing modules. On the capturing side, we propose an asynchronous capture scheme that increases the effective frame rate by staggering the start times of cameras. By grouping cameras and leveraging a base frame rate of 25 FPS, our method achieves an equivalent frame rate of 100-200 FPS without requiring specialized high-speed cameras. On processing side, we also propose a novel generative model to fix artifacts caused by 4D sparse-view reconstruction, as asynchrony reduces the number of viewpoints at each timestamp. Specifically, we propose to train a video-diffusion-based artifact-fix model for sparse 4D reconstruction, which refines missing details, maintains temporal consistency, and improves overall reconstruction quality. Experimental results demonstrate that our method significantly enhances high-speed 4D reconstruction compared to synchronous capture.





VGGT-X: When VGGT Meets Dense Novel View Synthesis
We study the problem of applying 3D Foundation Models (3DFMs) to dense Novel View Synthesis (NVS). Despite significant progress in Novel View Synthesis powered by NeRF and 3DGS, current approaches remain reliant on accurate 3D attributes (e.g., camera poses and point clouds) acquired from Structure-from-Motion (SfM), which is often slow and fragile in low-texture or low-overlap captures. Recent 3DFMs showcase orders of magnitude speedup over the traditional pipeline and great potential for online NVS. But most of the validation and conclusions are confined to sparse-view settings. Our study reveals that naively scaling 3DFMs to dense views encounters two fundamental barriers: dramatically increasing VRAM burden and imperfect outputs that degrade initialization-sensitive 3D training. To address these barriers, we introduce VGGT-X, incorporating a memory-efficient VGGT implementation that scales to 1,000+ images, an adaptive global alignment for VGGT output enhancement, and robust 3DGS training practices. Extensive experiments show that these measures substantially close the fidelity gap with COLMAP-initialized pipelines, achieving state-of-the-art results in dense COLMAP-free NVS and pose estimation. Additionally, we analyze the causes of remaining gaps with COLMAP-initialized rendering, providing insights for the future development of 3D foundation models and dense NVS. Our project page is available at https://dekuliutesla.github.io/vggt-x.github.io/
PLA4D: Pixel-Level Alignments for Text-to-4D Gaussian Splatting
As text-conditioned diffusion models (DMs) achieve breakthroughs in image, video, and 3D generation, the research community's focus has shifted to the more challenging task of text-to-4D synthesis, which introduces a temporal dimension to generate dynamic 3D objects. In this context, we identify Score Distillation Sampling (SDS), a widely used technique for text-to-3D synthesis, as a significant hindrance to text-to-4D performance due to its Janus-faced and texture-unrealistic problems coupled with high computational costs. In this paper, we propose Pixel-Level Alignments for Text-to-4D Gaussian Splatting (PLA4D), a novel method that utilizes text-to-video frames as explicit pixel alignment targets to generate static 3D objects and inject motion into them. Specifically, we introduce Focal Alignment to calibrate camera poses for rendering and GS-Mesh Contrastive Learning to distill geometry priors from rendered image contrasts at the pixel level. Additionally, we develop Motion Alignment using a deformation network to drive changes in Gaussians and implement Reference Refinement for smooth 4D object surfaces. These techniques enable 4D Gaussian Splatting to align geometry, texture, and motion with generated videos at the pixel level. Compared to previous methods, PLA4D produces synthesized outputs with better texture details in less time and effectively mitigates the Janus-faced problem. PLA4D is fully implemented using open-source models, offering an accessible, user-friendly, and promising direction for 4D digital content creation. Our project page: https://github.com/MiaoQiaowei/PLA4D.github.io{https://github.com/MiaoQiaowei/PLA4D.github.io}.


Gaussian Variation Field Diffusion for High-fidelity Video-to-4D Synthesis
In this paper, we present a novel framework for video-to-4D generation that creates high-quality dynamic 3D content from single video inputs. Direct 4D diffusion modeling is extremely challenging due to costly data construction and the high-dimensional nature of jointly representing 3D shape, appearance, and motion. We address these challenges by introducing a Direct 4DMesh-to-GS Variation Field VAE that directly encodes canonical Gaussian Splats (GS) and their temporal variations from 3D animation data without per-instance fitting, and compresses high-dimensional animations into a compact latent space. Building upon this efficient representation, we train a Gaussian Variation Field diffusion model with temporal-aware Diffusion Transformer conditioned on input videos and canonical GS. Trained on carefully-curated animatable 3D objects from the Objaverse dataset, our model demonstrates superior generation quality compared to existing methods. It also exhibits remarkable generalization to in-the-wild video inputs despite being trained exclusively on synthetic data, paving the way for generating high-quality animated 3D content. Project page: https://gvfdiffusion.github.io/.

EG4D: Explicit Generation of 4D Object without Score Distillation
In recent years, the increasing demand for dynamic 3D assets in design and gaming applications has given rise to powerful generative pipelines capable of synthesizing high-quality 4D objects. Previous methods generally rely on score distillation sampling (SDS) algorithm to infer the unseen views and motion of 4D objects, thus leading to unsatisfactory results with defects like over-saturation and Janus problem. Therefore, inspired by recent progress of video diffusion models, we propose to optimize a 4D representation by explicitly generating multi-view videos from one input image. However, it is far from trivial to handle practical challenges faced by such a pipeline, including dramatic temporal inconsistency, inter-frame geometry and texture diversity, and semantic defects brought by video generation results. To address these issues, we propose DG4D, a novel multi-stage framework that generates high-quality and consistent 4D assets without score distillation. Specifically, collaborative techniques and solutions are developed, including an attention injection strategy to synthesize temporal-consistent multi-view videos, a robust and efficient dynamic reconstruction method based on Gaussian Splatting, and a refinement stage with diffusion prior for semantic restoration. The qualitative results and user preference study demonstrate that our framework outperforms the baselines in generation quality by a considerable margin. Code will be released at https://github.com/jasongzy/EG4D.
3D-Aware Implicit Motion Control for View-Adaptive Human Video Generation
Existing methods for human motion control in video generation typically rely on either 2D poses or explicit 3D parametric models (e.g., SMPL) as control signals. However, 2D poses rigidly bind motion to the driving viewpoint, precluding novel-view synthesis. Explicit 3D models, though structurally informative, suffer from inherent inaccuracies (e.g., depth ambiguity and inaccurate dynamics) which, when used as a strong constraint, override the powerful intrinsic 3D awareness of large-scale video generators. In this work, we revisit motion control from a 3D-aware perspective, advocating for an implicit, view-agnostic motion representation that naturally aligns with the generator's spatial priors rather than depending on externally reconstructed constraints. We introduce 3DiMo, which jointly trains a motion encoder with a pretrained video generator to distill driving frames into compact, view-agnostic motion tokens, injected semantically via cross-attention. To foster 3D awareness, we train with view-rich supervision (i.e., single-view, multi-view, and moving-camera videos), forcing motion consistency across diverse viewpoints. Additionally, we use auxiliary geometric supervision that leverages SMPL only for early initialization and is annealed to zero, enabling the model to transition from external 3D guidance to learning genuine 3D spatial motion understanding from the data and the generator's priors. Experiments confirm that 3DiMo faithfully reproduces driving motions with flexible, text-driven camera control, significantly surpassing existing methods in both motion fidelity and visual quality.

Shape-for-Motion: Precise and Consistent Video Editing with 3D Proxy
Recent advances in deep generative modeling have unlocked unprecedented opportunities for video synthesis. In real-world applications, however, users often seek tools to faithfully realize their creative editing intentions with precise and consistent control. Despite the progress achieved by existing methods, ensuring fine-grained alignment with user intentions remains an open and challenging problem. In this work, we present Shape-for-Motion, a novel framework that incorporates a 3D proxy for precise and consistent video editing. Shape-for-Motion achieves this by converting the target object in the input video to a time-consistent mesh, i.e., a 3D proxy, allowing edits to be performed directly on the proxy and then inferred back to the video frames. To simplify the editing process, we design a novel Dual-Propagation Strategy that allows users to perform edits on the 3D mesh of a single frame, and the edits are then automatically propagated to the 3D meshes of the other frames. The 3D meshes for different frames are further projected onto the 2D space to produce the edited geometry and texture renderings, which serve as inputs to a decoupled video diffusion model for generating edited results. Our framework supports various precise and physically-consistent manipulations across the video frames, including pose editing, rotation, scaling, translation, texture modification, and object composition. Our approach marks a key step toward high-quality, controllable video editing workflows. Extensive experiments demonstrate the superiority and effectiveness of our approach. Project page: https://shapeformotion.github.io/


MotionDuet: Dual-Conditioned 3D Human Motion Generation with Video-Regularized Text Learning
3D Human motion generation is pivotal across film, animation, gaming, and embodied intelligence. Traditional 3D motion synthesis relies on costly motion capture, while recent work shows that 2D videos provide rich, temporally coherent observations of human behavior. Existing approaches, however, either map high-level text descriptions to motion or rely solely on video conditioning, leaving a gap between generated dynamics and real-world motion statistics. We introduce MotionDuet, a multimodal framework that aligns motion generation with the distribution of video-derived representations. In this dual-conditioning paradigm, video cues extracted from a pretrained model (e.g., VideoMAE) ground low-level motion dynamics, while textual prompts provide semantic intent. To bridge the distribution gap across modalities, we propose Dual-stream Unified Encoding and Transformation (DUET) and a Distribution-Aware Structural Harmonization (DASH) loss. DUET fuses video-informed cues into the motion latent space via unified encoding and dynamic attention, while DASH aligns motion trajectories with both distributional and structural statistics of video features. An auto-guidance mechanism further balances textual and visual signals by leveraging a weakened copy of the model, enhancing controllability without sacrificing diversity. Extensive experiments demonstrate that MotionDuet generates realistic and controllable human motions, surpassing strong state-of-the-art baselines.
BF-STVSR: B-Splines and Fourier-Best Friends for High Fidelity Spatial-Temporal Video Super-Resolution
Enhancing low-resolution, low-frame-rate videos to high-resolution, high-frame-rate quality is essential for a seamless user experience, motivating advancements in Continuous Spatial-Temporal Video Super Resolution (C-STVSR). While prior methods employ Implicit Neural Representation (INR) for continuous encoding, they often struggle to capture the complexity of video data, relying on simple coordinate concatenation and pre-trained optical flow network for motion representation. Interestingly, we find that adding position encoding, contrary to common observations, does not improve-and even degrade performance. This issue becomes particularly pronounced when combined with pre-trained optical flow networks, which can limit the model's flexibility. To address these issues, we propose BF-STVSR, a C-STVSR framework with two key modules tailored to better represent spatial and temporal characteristics of video: 1) B-spline Mapper for smooth temporal interpolation, and 2) Fourier Mapper for capturing dominant spatial frequencies. Our approach achieves state-of-the-art PSNR and SSIM performance, showing enhanced spatial details and natural temporal consistency.
FreeTimeGS: Free Gaussians at Anytime and Anywhere for Dynamic Scene Reconstruction
This paper addresses the challenge of reconstructing dynamic 3D scenes with complex motions. Some recent works define 3D Gaussian primitives in the canonical space and use deformation fields to map canonical primitives to observation spaces, achieving real-time dynamic view synthesis. However, these methods often struggle to handle scenes with complex motions due to the difficulty of optimizing deformation fields. To overcome this problem, we propose FreeTimeGS, a novel 4D representation that allows Gaussian primitives to appear at arbitrary time and locations. In contrast to canonical Gaussian primitives, our representation possesses the strong flexibility, thus improving the ability to model dynamic 3D scenes. In addition, we endow each Gaussian primitive with an motion function, allowing it to move to neighboring regions over time, which reduces the temporal redundancy. Experiments results on several datasets show that the rendering quality of our method outperforms recent methods by a large margin.
RoHM: Robust Human Motion Reconstruction via Diffusion
We propose RoHM, an approach for robust 3D human motion reconstruction from monocular RGB(-D) videos in the presence of noise and occlusions. Most previous approaches either train neural networks to directly regress motion in 3D or learn data-driven motion priors and combine them with optimization at test time. The former do not recover globally coherent motion and fail under occlusions; the latter are time-consuming, prone to local minima, and require manual tuning. To overcome these shortcomings, we exploit the iterative, denoising nature of diffusion models. RoHM is a novel diffusion-based motion model that, conditioned on noisy and occluded input data, reconstructs complete, plausible motions in consistent global coordinates. Given the complexity of the problem -- requiring one to address different tasks (denoising and infilling) in different solution spaces (local and global motion) -- we decompose it into two sub-tasks and learn two models, one for global trajectory and one for local motion. To capture the correlations between the two, we then introduce a novel conditioning module, combining it with an iterative inference scheme. We apply RoHM to a variety of tasks -- from motion reconstruction and denoising to spatial and temporal infilling. Extensive experiments on three popular datasets show that our method outperforms state-of-the-art approaches qualitatively and quantitatively, while being faster at test time. The code will be available at https://sanweiliti.github.io/ROHM/ROHM.html.
GS-DiT: Advancing Video Generation with Pseudo 4D Gaussian Fields through Efficient Dense 3D Point Tracking
4D video control is essential in video generation as it enables the use of sophisticated lens techniques, such as multi-camera shooting and dolly zoom, which are currently unsupported by existing methods. Training a video Diffusion Transformer (DiT) directly to control 4D content requires expensive multi-view videos. Inspired by Monocular Dynamic novel View Synthesis (MDVS) that optimizes a 4D representation and renders videos according to different 4D elements, such as camera pose and object motion editing, we bring pseudo 4D Gaussian fields to video generation. Specifically, we propose a novel framework that constructs a pseudo 4D Gaussian field with dense 3D point tracking and renders the Gaussian field for all video frames. Then we finetune a pretrained DiT to generate videos following the guidance of the rendered video, dubbed as GS-DiT. To boost the training of the GS-DiT, we also propose an efficient Dense 3D Point Tracking (D3D-PT) method for the pseudo 4D Gaussian field construction. Our D3D-PT outperforms SpatialTracker, the state-of-the-art sparse 3D point tracking method, in accuracy and accelerates the inference speed by two orders of magnitude. During the inference stage, GS-DiT can generate videos with the same dynamic content while adhering to different camera parameters, addressing a significant limitation of current video generation models. GS-DiT demonstrates strong generalization capabilities and extends the 4D controllability of Gaussian splatting to video generation beyond just camera poses. It supports advanced cinematic effects through the manipulation of the Gaussian field and camera intrinsics, making it a powerful tool for creative video production. Demos are available at https://wkbian.github.io/Projects/GS-DiT/.

MMVP: Motion-Matrix-based Video Prediction
A central challenge of video prediction lies where the system has to reason the objects' future motions from image frames while simultaneously maintaining the consistency of their appearances across frames. This work introduces an end-to-end trainable two-stream video prediction framework, Motion-Matrix-based Video Prediction (MMVP), to tackle this challenge. Unlike previous methods that usually handle motion prediction and appearance maintenance within the same set of modules, MMVP decouples motion and appearance information by constructing appearance-agnostic motion matrices. The motion matrices represent the temporal similarity of each and every pair of feature patches in the input frames, and are the sole input of the motion prediction module in MMVP. This design improves video prediction in both accuracy and efficiency, and reduces the model size. Results of extensive experiments demonstrate that MMVP outperforms state-of-the-art systems on public data sets by non-negligible large margins (about 1 db in PSNR, UCF Sports) in significantly smaller model sizes (84% the size or smaller).
Hi3D: Pursuing High-Resolution Image-to-3D Generation with Video Diffusion Models
Despite having tremendous progress in image-to-3D generation, existing methods still struggle to produce multi-view consistent images with high-resolution textures in detail, especially in the paradigm of 2D diffusion that lacks 3D awareness. In this work, we present High-resolution Image-to-3D model (Hi3D), a new video diffusion based paradigm that redefines a single image to multi-view images as 3D-aware sequential image generation (i.e., orbital video generation). This methodology delves into the underlying temporal consistency knowledge in video diffusion model that generalizes well to geometry consistency across multiple views in 3D generation. Technically, Hi3D first empowers the pre-trained video diffusion model with 3D-aware prior (camera pose condition), yielding multi-view images with low-resolution texture details. A 3D-aware video-to-video refiner is learnt to further scale up the multi-view images with high-resolution texture details. Such high-resolution multi-view images are further augmented with novel views through 3D Gaussian Splatting, which are finally leveraged to obtain high-fidelity meshes via 3D reconstruction. Extensive experiments on both novel view synthesis and single view reconstruction demonstrate that our Hi3D manages to produce superior multi-view consistency images with highly-detailed textures. Source code and data are available at https://github.com/yanghb22-fdu/Hi3D-Official.


Sora Generates Videos with Stunning Geometrical Consistency
The recently developed Sora model [1] has exhibited remarkable capabilities in video generation, sparking intense discussions regarding its ability to simulate real-world phenomena. Despite its growing popularity, there is a lack of established metrics to evaluate its fidelity to real-world physics quantitatively. In this paper, we introduce a new benchmark that assesses the quality of the generated videos based on their adherence to real-world physics principles. We employ a method that transforms the generated videos into 3D models, leveraging the premise that the accuracy of 3D reconstruction is heavily contingent on the video quality. From the perspective of 3D reconstruction, we use the fidelity of the geometric constraints satisfied by the constructed 3D models as a proxy to gauge the extent to which the generated videos conform to real-world physics rules. Project page: https://sora-geometrical-consistency.github.io/



GenXD: Generating Any 3D and 4D Scenes
Recent developments in 2D visual generation have been remarkably successful. However, 3D and 4D generation remain challenging in real-world applications due to the lack of large-scale 4D data and effective model design. In this paper, we propose to jointly investigate general 3D and 4D generation by leveraging camera and object movements commonly observed in daily life. Due to the lack of real-world 4D data in the community, we first propose a data curation pipeline to obtain camera poses and object motion strength from videos. Based on this pipeline, we introduce a large-scale real-world 4D scene dataset: CamVid-30K. By leveraging all the 3D and 4D data, we develop our framework, GenXD, which allows us to produce any 3D or 4D scene. We propose multiview-temporal modules, which disentangle camera and object movements, to seamlessly learn from both 3D and 4D data. Additionally, GenXD employs masked latent conditions to support a variety of conditioning views. GenXD can generate videos that follow the camera trajectory as well as consistent 3D views that can be lifted into 3D representations. We perform extensive evaluations across various real-world and synthetic datasets, demonstrating GenXD's effectiveness and versatility compared to previous methods in 3D and 4D generation.




Delving into Motion-Aware Matching for Monocular 3D Object Tracking
Recent advances of monocular 3D object detection facilitate the 3D multi-object tracking task based on low-cost camera sensors. In this paper, we find that the motion cue of objects along different time frames is critical in 3D multi-object tracking, which is less explored in existing monocular-based approaches. In this paper, we propose a motion-aware framework for monocular 3D MOT. To this end, we propose MoMA-M3T, a framework that mainly consists of three motion-aware components. First, we represent the possible movement of an object related to all object tracklets in the feature space as its motion features. Then, we further model the historical object tracklet along the time frame in a spatial-temporal perspective via a motion transformer. Finally, we propose a motion-aware matching module to associate historical object tracklets and current observations as final tracking results. We conduct extensive experiments on the nuScenes and KITTI datasets to demonstrate that our MoMA-M3T achieves competitive performance against state-of-the-art methods. Moreover, the proposed tracker is flexible and can be easily plugged into existing image-based 3D object detectors without re-training. Code and models are available at https://github.com/kuanchihhuang/MoMA-M3T.
RAGME: Retrieval Augmented Video Generation for Enhanced Motion Realism
Video generation is experiencing rapid growth, driven by advances in diffusion models and the development of better and larger datasets. However, producing high-quality videos remains challenging due to the high-dimensional data and the complexity of the task. Recent efforts have primarily focused on enhancing visual quality and addressing temporal inconsistencies, such as flickering. Despite progress in these areas, the generated videos often fall short in terms of motion complexity and physical plausibility, with many outputs either appearing static or exhibiting unrealistic motion. In this work, we propose a framework to improve the realism of motion in generated videos, exploring a complementary direction to much of the existing literature. Specifically, we advocate for the incorporation of a retrieval mechanism during the generation phase. The retrieved videos act as grounding signals, providing the model with demonstrations of how the objects move. Our pipeline is designed to apply to any text-to-video diffusion model, conditioning a pretrained model on the retrieved samples with minimal fine-tuning. We demonstrate the superiority of our approach through established metrics, recently proposed benchmarks, and qualitative results, and we highlight additional applications of the framework.
AAMDM: Accelerated Auto-regressive Motion Diffusion Model
Interactive motion synthesis is essential in creating immersive experiences in entertainment applications, such as video games and virtual reality. However, generating animations that are both high-quality and contextually responsive remains a challenge. Traditional techniques in the game industry can produce high-fidelity animations but suffer from high computational costs and poor scalability. Trained neural network models alleviate the memory and speed issues, yet fall short on generating diverse motions. Diffusion models offer diverse motion synthesis with low memory usage, but require expensive reverse diffusion processes. This paper introduces the Accelerated Auto-regressive Motion Diffusion Model (AAMDM), a novel motion synthesis framework designed to achieve quality, diversity, and efficiency all together. AAMDM integrates Denoising Diffusion GANs as a fast Generation Module, and an Auto-regressive Diffusion Model as a Polishing Module. Furthermore, AAMDM operates in a lower-dimensional embedded space rather than the full-dimensional pose space, which reduces the training complexity as well as further improves the performance. We show that AAMDM outperforms existing methods in motion quality, diversity, and runtime efficiency, through comprehensive quantitative analyses and visual comparisons. We also demonstrate the effectiveness of each algorithmic component through ablation studies.
Long-Term 3D Point Tracking By Cost Volume Fusion
Long-term point tracking is essential to understand non-rigid motion in the physical world better. Deep learning approaches have recently been incorporated into long-term point tracking, but most prior work predominantly functions in 2D. Although these methods benefit from the well-established backbones and matching frameworks, the motions they produce do not always make sense in the 3D physical world. In this paper, we propose the first deep learning framework for long-term point tracking in 3D that generalizes to new points and videos without requiring test-time fine-tuning. Our model contains a cost volume fusion module that effectively integrates multiple past appearances and motion information via a transformer architecture, significantly enhancing overall tracking performance. In terms of 3D tracking performance, our model significantly outperforms simple scene flow chaining and previous 2D point tracking methods, even if one uses ground truth depth and camera pose to backproject 2D point tracks in a synthetic scenario.
Physically Compatible 3D Object Modeling from a Single Image
We present a computational framework that transforms single images into 3D physical objects. The visual geometry of a physical object in an image is determined by three orthogonal attributes: mechanical properties, external forces, and rest-shape geometry. Existing single-view 3D reconstruction methods often overlook this underlying composition, presuming rigidity or neglecting external forces. Consequently, the reconstructed objects fail to withstand real-world physical forces, resulting in instability or undesirable deformation -- diverging from their intended designs as depicted in the image. Our optimization framework addresses this by embedding physical compatibility into the reconstruction process. We explicitly decompose the three physical attributes and link them through static equilibrium, which serves as a hard constraint, ensuring that the optimized physical shapes exhibit desired physical behaviors. Evaluations on a dataset collected from Objaverse demonstrate that our framework consistently enhances the physical realism of 3D models over existing methods. The utility of our framework extends to practical applications in dynamic simulations and 3D printing, where adherence to physical compatibility is paramount.

4D Gaussian Splatting: Towards Efficient Novel View Synthesis for Dynamic Scenes
We consider the problem of novel view synthesis (NVS) for dynamic scenes. Recent neural approaches have accomplished exceptional NVS results for static 3D scenes, but extensions to 4D time-varying scenes remain non-trivial. Prior efforts often encode dynamics by learning a canonical space plus implicit or explicit deformation fields, which struggle in challenging scenarios like sudden movements or capturing high-fidelity renderings. In this paper, we introduce 4D Gaussian Splatting (4DGS), a novel method that represents dynamic scenes with anisotropic 4D XYZT Gaussians, inspired by the success of 3D Gaussian Splatting in static scenes. We model dynamics at each timestamp by temporally slicing the 4D Gaussians, which naturally compose dynamic 3D Gaussians and can be seamlessly projected into images. As an explicit spatial-temporal representation, 4DGS demonstrates powerful capabilities for modeling complicated dynamics and fine details, especially for scenes with abrupt motions. We further implement our temporal slicing and splatting techniques in a highly optimized CUDA acceleration framework, achieving real-time inference rendering speeds of up to 277 FPS on an RTX 3090 GPU and 583 FPS on an RTX 4090 GPU. Rigorous evaluations on scenes with diverse motions showcase the superior efficiency and effectiveness of 4DGS, which consistently outperforms existing methods both quantitatively and qualitatively.
3DTrajMaster: Mastering 3D Trajectory for Multi-Entity Motion in Video Generation
This paper aims to manipulate multi-entity 3D motions in video generation. Previous methods on controllable video generation primarily leverage 2D control signals to manipulate object motions and have achieved remarkable synthesis results. However, 2D control signals are inherently limited in expressing the 3D nature of object motions. To overcome this problem, we introduce 3DTrajMaster, a robust controller that regulates multi-entity dynamics in 3D space, given user-desired 6DoF pose (location and rotation) sequences of entities. At the core of our approach is a plug-and-play 3D-motion grounded object injector that fuses multiple input entities with their respective 3D trajectories through a gated self-attention mechanism. In addition, we exploit an injector architecture to preserve the video diffusion prior, which is crucial for generalization ability. To mitigate video quality degradation, we introduce a domain adaptor during training and employ an annealed sampling strategy during inference. To address the lack of suitable training data, we construct a 360-Motion Dataset, which first correlates collected 3D human and animal assets with GPT-generated trajectory and then captures their motion with 12 evenly-surround cameras on diverse 3D UE platforms. Extensive experiments show that 3DTrajMaster sets a new state-of-the-art in both accuracy and generalization for controlling multi-entity 3D motions. Project page: http://fuxiao0719.github.io/projects/3dtrajmaster





3DGStream: On-the-Fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos
Constructing photo-realistic Free-Viewpoint Videos (FVVs) of dynamic scenes from multi-view videos remains a challenging endeavor. Despite the remarkable advancements achieved by current neural rendering techniques, these methods generally require complete video sequences for offline training and are not capable of real-time rendering. To address these constraints, we introduce 3DGStream, a method designed for efficient FVV streaming of real-world dynamic scenes. Our method achieves fast on-the-fly per-frame reconstruction within 12 seconds and real-time rendering at 200 FPS. Specifically, we utilize 3D Gaussians (3DGs) to represent the scene. Instead of the na\"ive approach of directly optimizing 3DGs per-frame, we employ a compact Neural Transformation Cache (NTC) to model the translations and rotations of 3DGs, markedly reducing the training time and storage required for each FVV frame. Furthermore, we propose an adaptive 3DG addition strategy to handle emerging objects in dynamic scenes. Experiments demonstrate that 3DGStream achieves competitive performance in terms of rendering speed, image quality, training time, and model storage when compared with state-of-the-art methods.



MoDec-GS: Global-to-Local Motion Decomposition and Temporal Interval Adjustment for Compact Dynamic 3D Gaussian Splatting
3D Gaussian Splatting (3DGS) has made significant strides in scene representation and neural rendering, with intense efforts focused on adapting it for dynamic scenes. Despite delivering remarkable rendering quality and speed, existing methods struggle with storage demands and representing complex real-world motions. To tackle these issues, we propose MoDecGS, a memory-efficient Gaussian splatting framework designed for reconstructing novel views in challenging scenarios with complex motions. We introduce GlobaltoLocal Motion Decomposition (GLMD) to effectively capture dynamic motions in a coarsetofine manner. This approach leverages Global Canonical Scaffolds (Global CS) and Local Canonical Scaffolds (Local CS), extending static Scaffold representation to dynamic video reconstruction. For Global CS, we propose Global Anchor Deformation (GAD) to efficiently represent global dynamics along complex motions, by directly deforming the implicit Scaffold attributes which are anchor position, offset, and local context features. Next, we finely adjust local motions via the Local Gaussian Deformation (LGD) of Local CS explicitly. Additionally, we introduce Temporal Interval Adjustment (TIA) to automatically control the temporal coverage of each Local CS during training, allowing MoDecGS to find optimal interval assignments based on the specified number of temporal segments. Extensive evaluations demonstrate that MoDecGS achieves an average 70% reduction in model size over stateoftheart methods for dynamic 3D Gaussians from realworld dynamic videos while maintaining or even improving rendering quality.



