---
license: apache-2.0
language:
- zh
- en
base_model:
- Qwen/Qwen2.5-VL-32B-Instruct
pipeline_tag: image-text-to-text
tags:
- multimodal
- flowchart
- chain-of-thought
- reinforcement-learning
- vision-language
datasets:
- Kingsoft-LLM/QZhou-Flowchart-QA
---
# QZhou-Flowchart-VL-32B: Multimodal Flowchart Reasoning Model
## Model Description
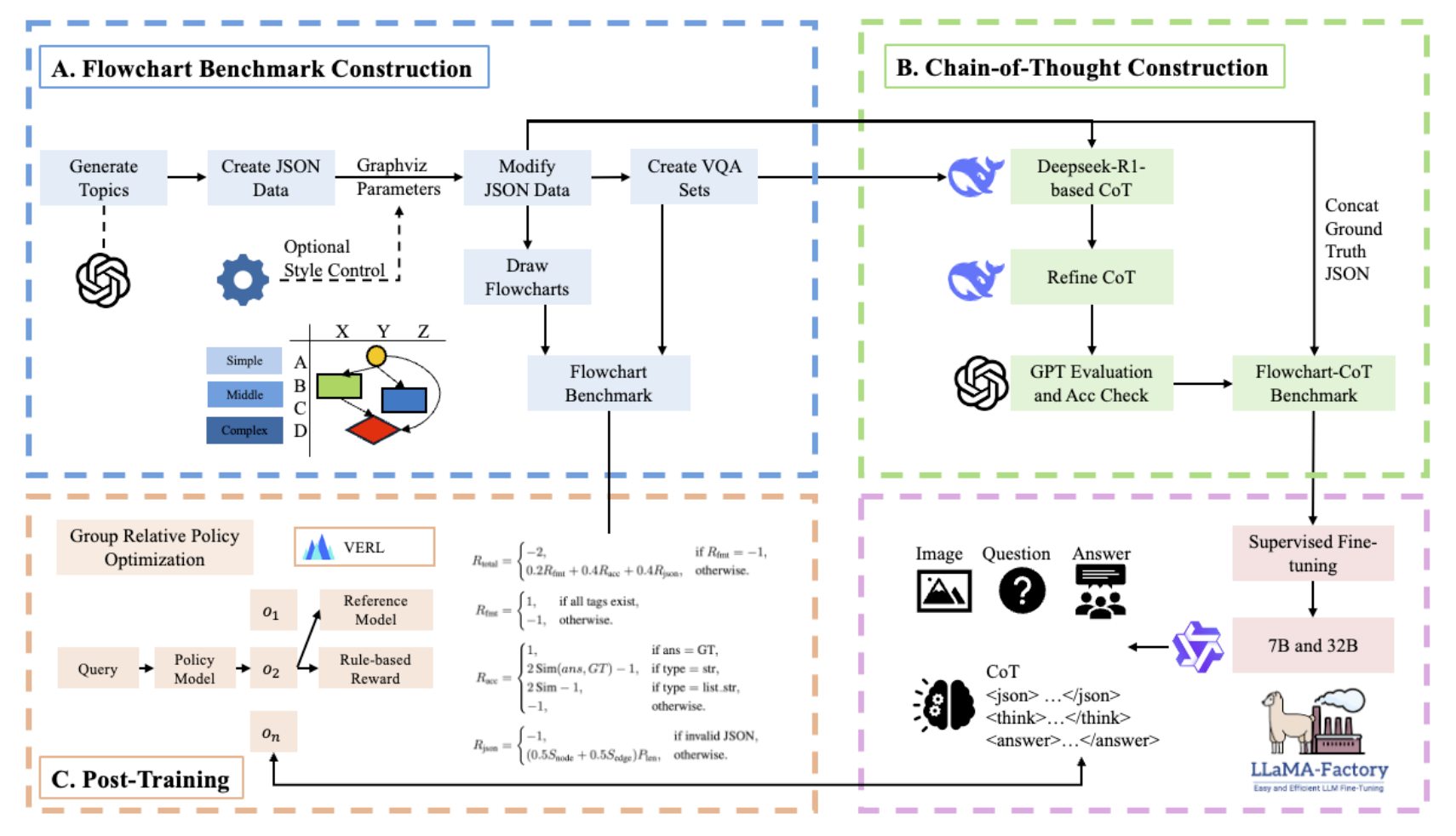
QZhou-Flowchart-VL-32B is a state-of-the-art multimodal large language model specifically designed for flowchart understanding and reasoning. This model is post-trained from Qwen2.5-VL-32B using reinforcement learning with our proposed **Tri-CoT** (Three-stage Chain-of-Thought) reasoning structure.
We develop a full training pipeline for multimodal large language models focused on flowchart understanding, covering data construction, structured reasoning, and reinforcement learning. The pipeline first synthesizes diverse flowcharts using automated topic generation, JSON-based structural representations, Graphviz-style drawing, and optional visual style control, followed by creating corresponding VQA pairs. To enable grounded reasoning, we propose Tri-CoT, a three-stage chain-of-thought format that separates diagram parsing, logical inference, and final answer generation. Unlike traditional CoT, the model is required to output a full JSON representation of the image before reasoning, ensuring accurate extraction of nodes, edges, and branching conditions. During post-training, we compare supervised fine-tuning with Group Relative Policy Optimization, showing that pure RL yields stronger structured reasoning and reduces hallucinations while preserving general capabilities.
**Key Features:**
- 🏆 Achieves **87.83%** on QZhou-Flowchart-QA-Benchmark, outperforming GPT-5, Gemini-2.5-Pro, and other SOTA models
- 🧠 Structured reasoning with Tri-CoT: JSON extraction → Logical thinking → Final answer
- 🔄 Trained with GRPO (Group Relative Policy Optimization) reinforcement learning
- 🎯 Maintains strong general capabilities across multimodal and text benchmarks
## Model Information
- **Base Model:** Qwen2.5-VL-32B
- **Training Method:** GRPO Reinforcement Learning
- **Training Data:** 14,600 synthetic flowchart samples with Tri-CoT annotations
## Performance
### QZhou-Flowchart-QA-Benchmark Results
| Model | QZhou-Flowchart-QA-Benchmark (%) |
|-------|-------------------|
| Qwen2.5-VL-32B | 73.90 |
| Qwen3-VL-Plus (235B) | 80.85 |
| Qwen3-VL-Plus-Thinking (235B) | 86.09 |
| Gemini-2.5-Pro | 84.42 |
| GLM-4.5V | 75.97 |
| doubao-seed-1-6 | 83.83 |
| GPT-5 | 79.29 |
| **QZhou-Flowchart-VL-32B (Ours)** | **87.83** |
### Comparison with Base Model
| Model | MMMU | CMMU | MathVista | DocVQA | QZhou-Flowchart-QA-Benchmark |
|-------|------|------|-----------|--------|----------------|
| Qwen2.5-VL-32B | 66.67 | 76.38 | 74.20 | 93.96 | 73.90 |
| **QZhou-Flowchart-VL-32B** | **67.78** | **76.46** | **76.50** | 93.87 | **87.83** |
## Quick Start
### Installation
```bash
pip install transformers torch pillow
```
### Basic Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
# Load model and tokenizer
model_name = "Kingsoft-LLM/QZhou-Flowchart-VL-32B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Load flowchart image
image = Image.open("flowchart.png")
# Prepare input with system prompt
system_prompt = """You are an expert at understanding and analyzing flowcharts.
When answering questions about flowcharts, you should:
1. First extract the flowchart structure in JSON format and wrap it in tags
2. Then provide your reasoning process in tags
3. Finally give the answer in tags"""
user_question = "What are the start nodes in this flowchart?"
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": [
{"type": "image", "image": image},
{"type": "text", "text": user_question}
]}
]
# Generate response
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=2048,
temperature=0.7,
top_p=0.9
)
response = tokenizer.batch_decode(
generated_ids,
skip_special_tokens=True
)[0]
print(response)
```
## Tri-CoT Output Format
The model generates responses in three structured parts:
```
{
"nodes": [...],
"edges": [...],
"axes": {...}
}
Step-by-step reasoning process based on the extracted JSON structure...
Final answer to the question
```
## Training Details
### Hyperparameters
- **Learning Rate:** 1e-6
- **Rollouts:** 5
- **Epochs:** 6
- **Framework:** VERL
- **Batch Size:** Variable per GPU
- **Training Samples:** 14,600
### Reward Function
The model uses a composite reward function with three components:
1. **Format Reward (20%):** Checks presence of all three tags (, , )
2. **Accuracy Reward (40%):** Compares predicted answer with ground truth
3. **JSON Reward (40%):** Evaluates node and edge extraction accuracy
## Supported Question Types
- Start/End Node Identification
- Node Counting
- Upstream/Downstream Node Queries
- Node In-degree/Out-degree
- Condition Queries
- X/Y-axis Spatial Relationships
- Path Analysis
- Stage-based Reasoning
## Limitations
- Primarily trained on synthetic flowcharts; real-world noisy images may require adaptation
- Performance may degrade with extremely large flowcharts (>50 nodes)
## License
This model is released under the same license as Qwen2.5-VL. Please refer to the [Qwen License](https://github.com/QwenLM/Qwen2.5-VL/blob/main/LICENSE) for details.
## Acknowledgements
- Base model: [Qwen2.5-VL](https://github.com/QwenLM/Qwen2.5-VL)
- Training framework: [VERL](https://github.com/volcengine/verl)
## Contact
For questions and feedback, contact us at [zhengshuli@kingsoft.com].